参考资料
ARM Architecture Reference Manual ARMv7-A and ARMv7-R edition
MDK环境搭建
下载Legacy Support支持包
https://armkeil.blob.core.windows.net/legacy/MDK79525.EXE
安装到MDK的安装目录下
下载ARM GNU工具链

创建项目
安装Legacy Support之后,可以在Device中对其进行选择
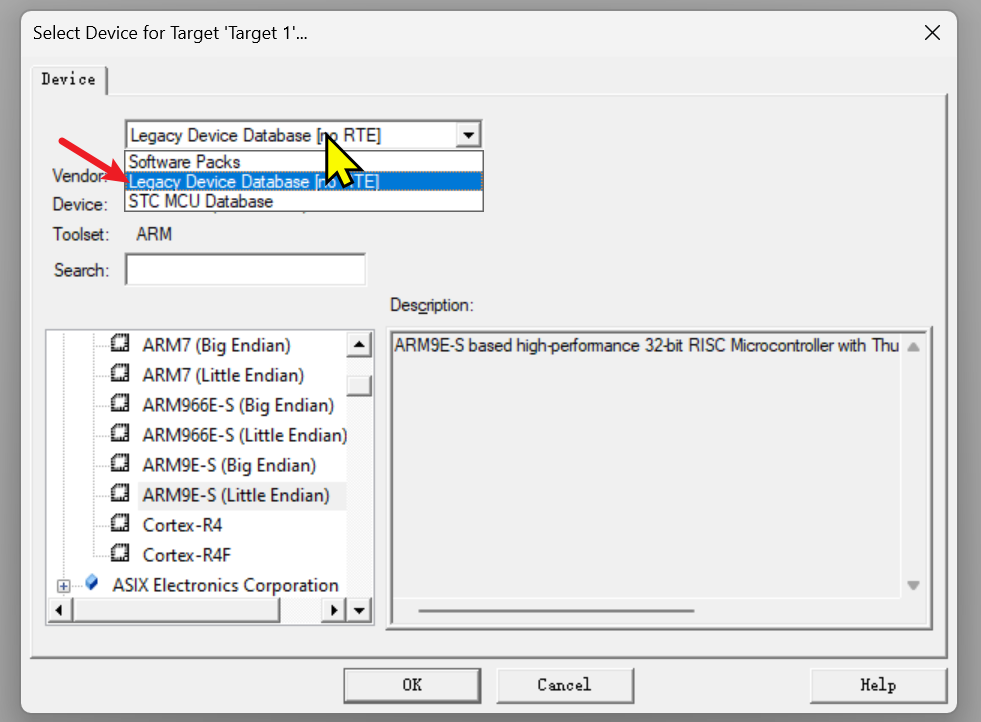
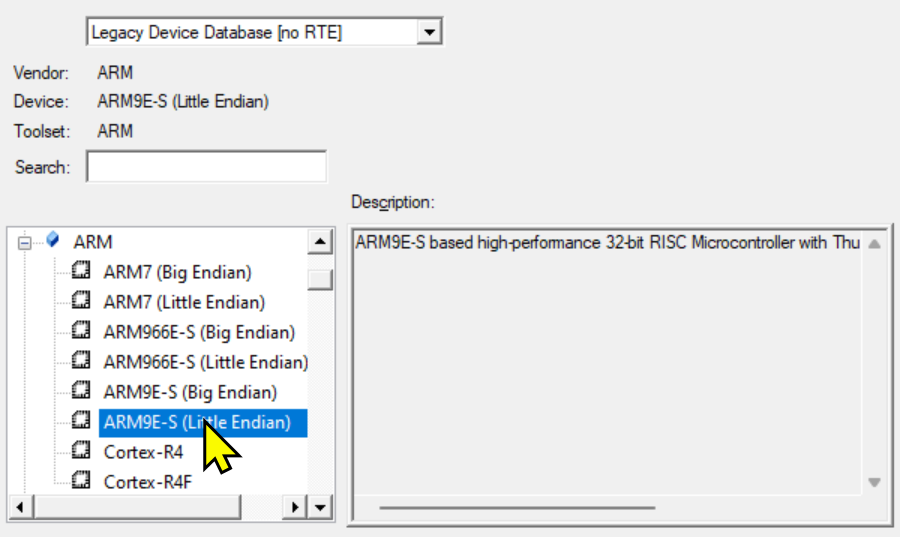
然后选择ARM9E-S(Little Endian)进行仿真
键入如下代码:
.global _start
_start:
mov r0,#1
mov r1,#2
mov r2,#3
stop:
b stop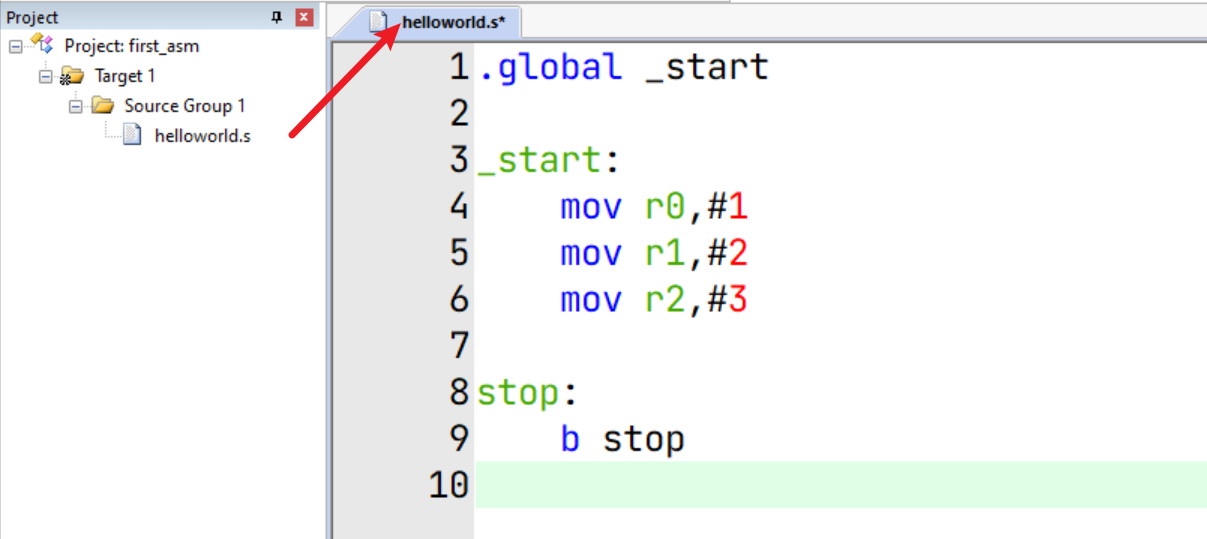
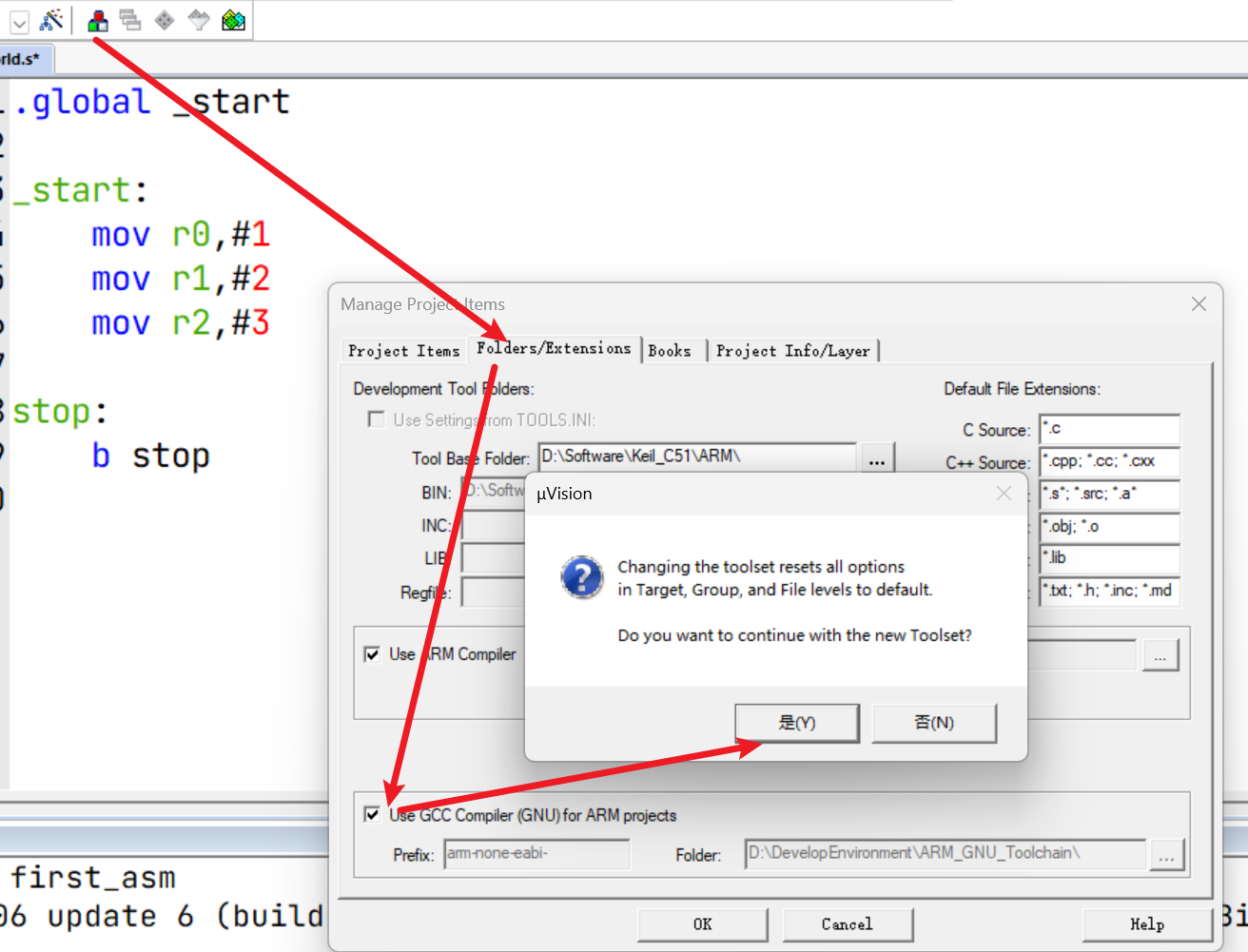
配置ARM GNU工具链
配置交叉编译工具链,即此前下载的ARM GNU的安装路径
编译项目
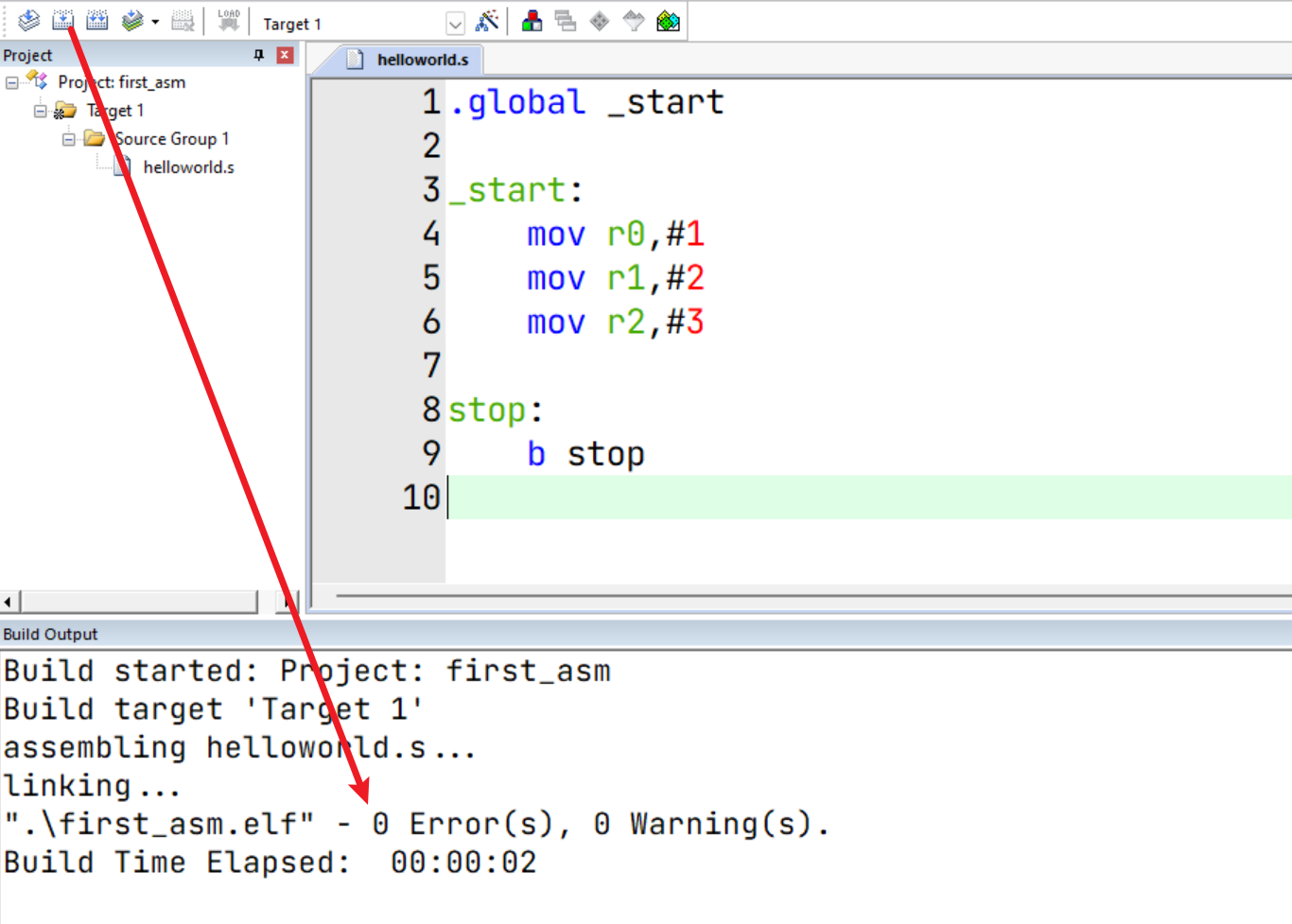
仿真/调试配置
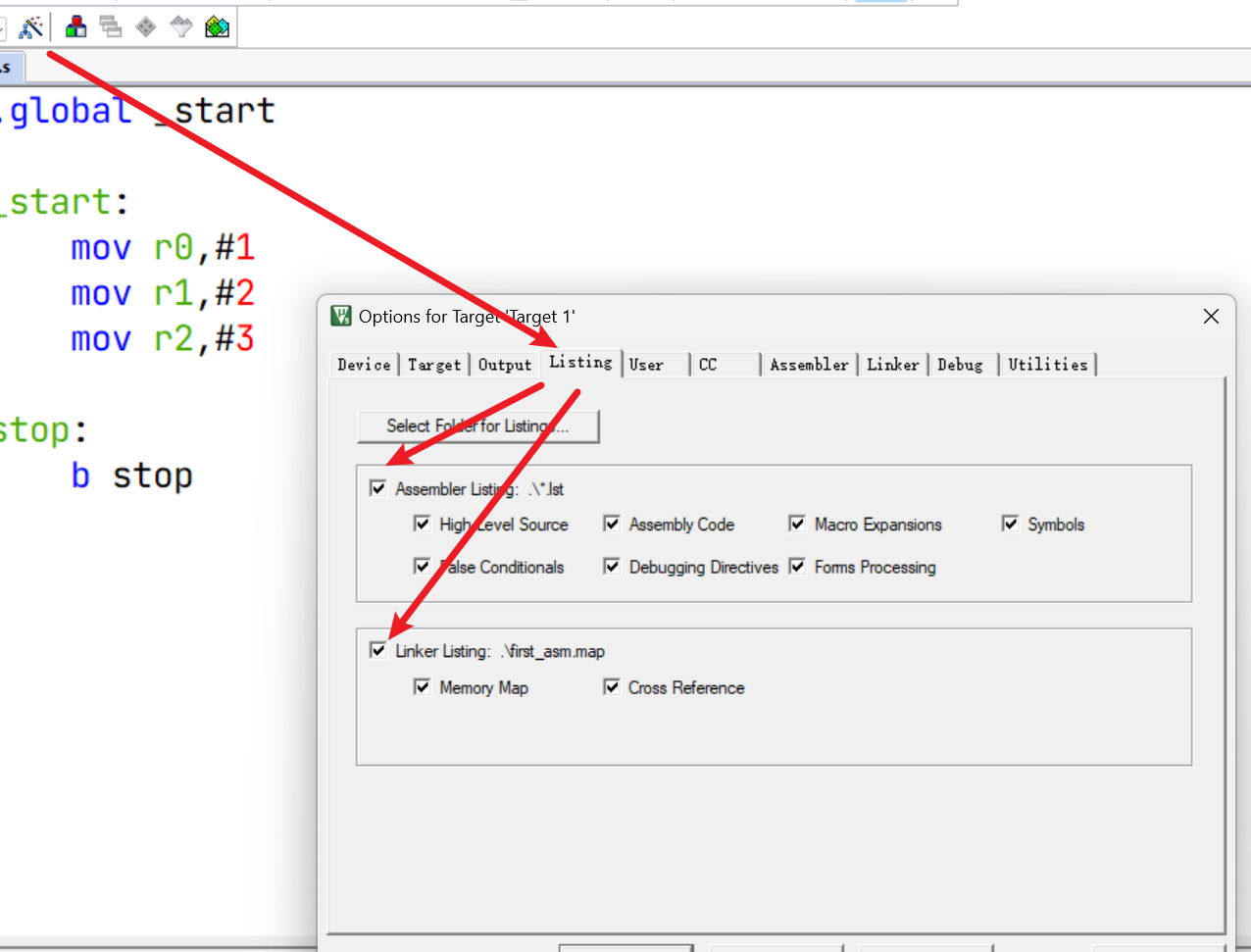
配置代码段开始地址:
注意:每次修改了编译配置选项后,最好重新编译一下以使其生效:
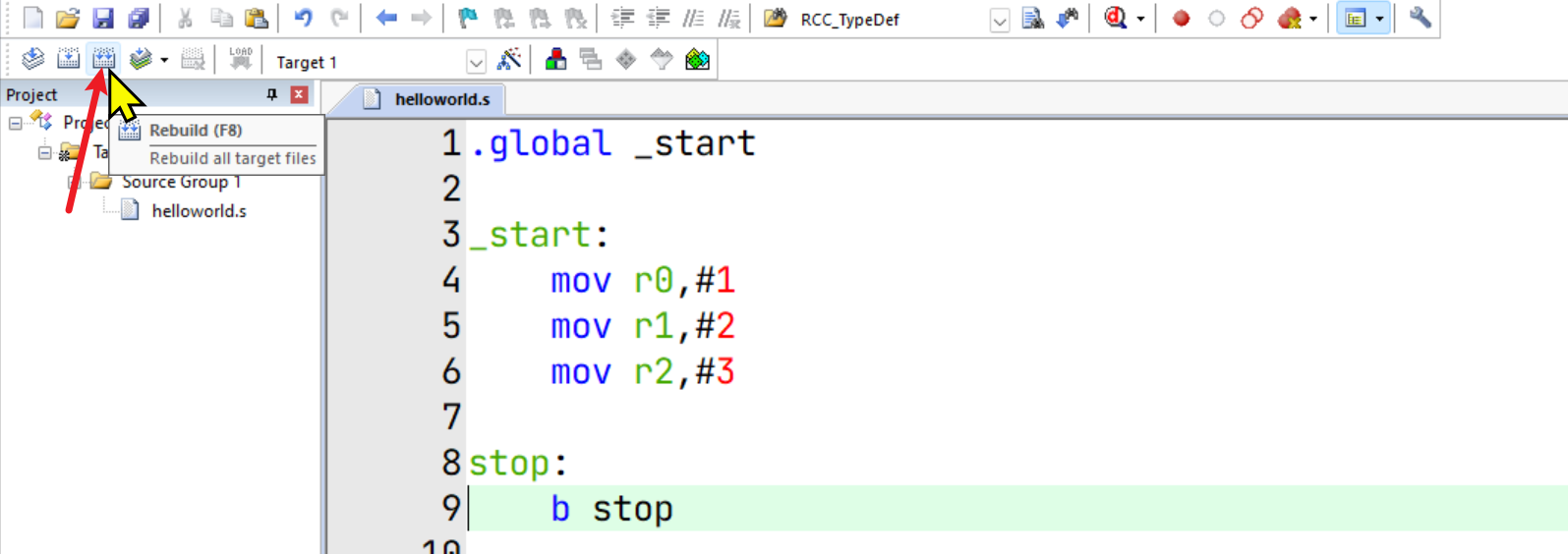
开始调试
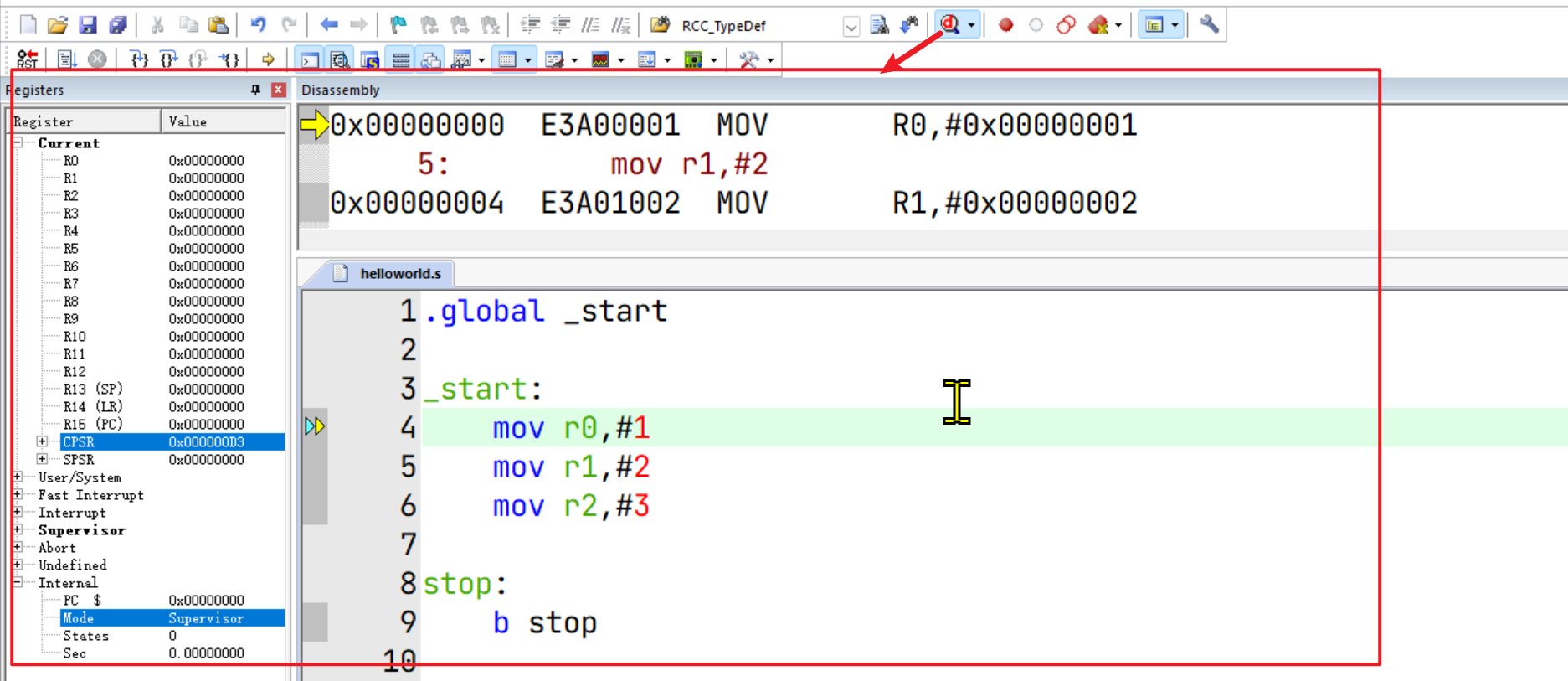
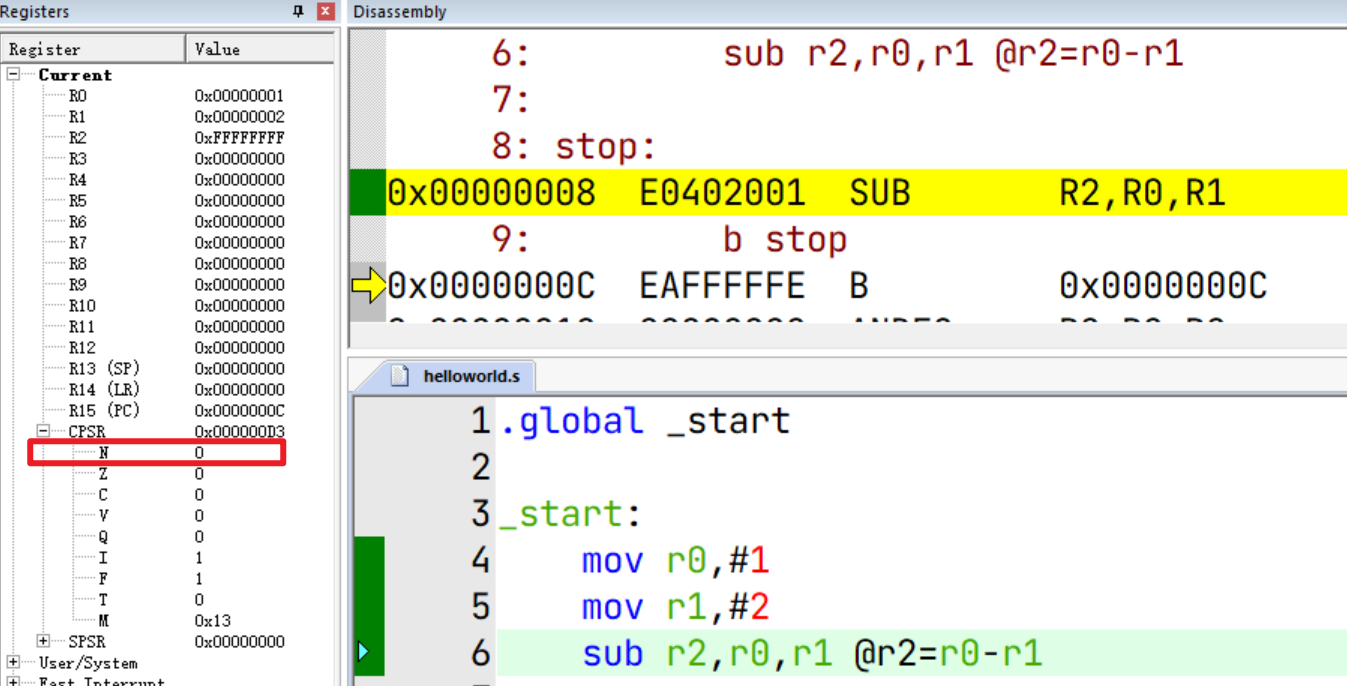
如果点击调试按钮后出现如上界面,则仿真环境配置成功了。左侧是ARM核的寄存器(可参考另一篇文章《ARM核(ARMv7-A/R)学习》),右上方是对应的汇编指令。
点击左上方的调试按钮,可以发现立即数1、2、3被依次加载到寄存器R0、R1、R2中了:
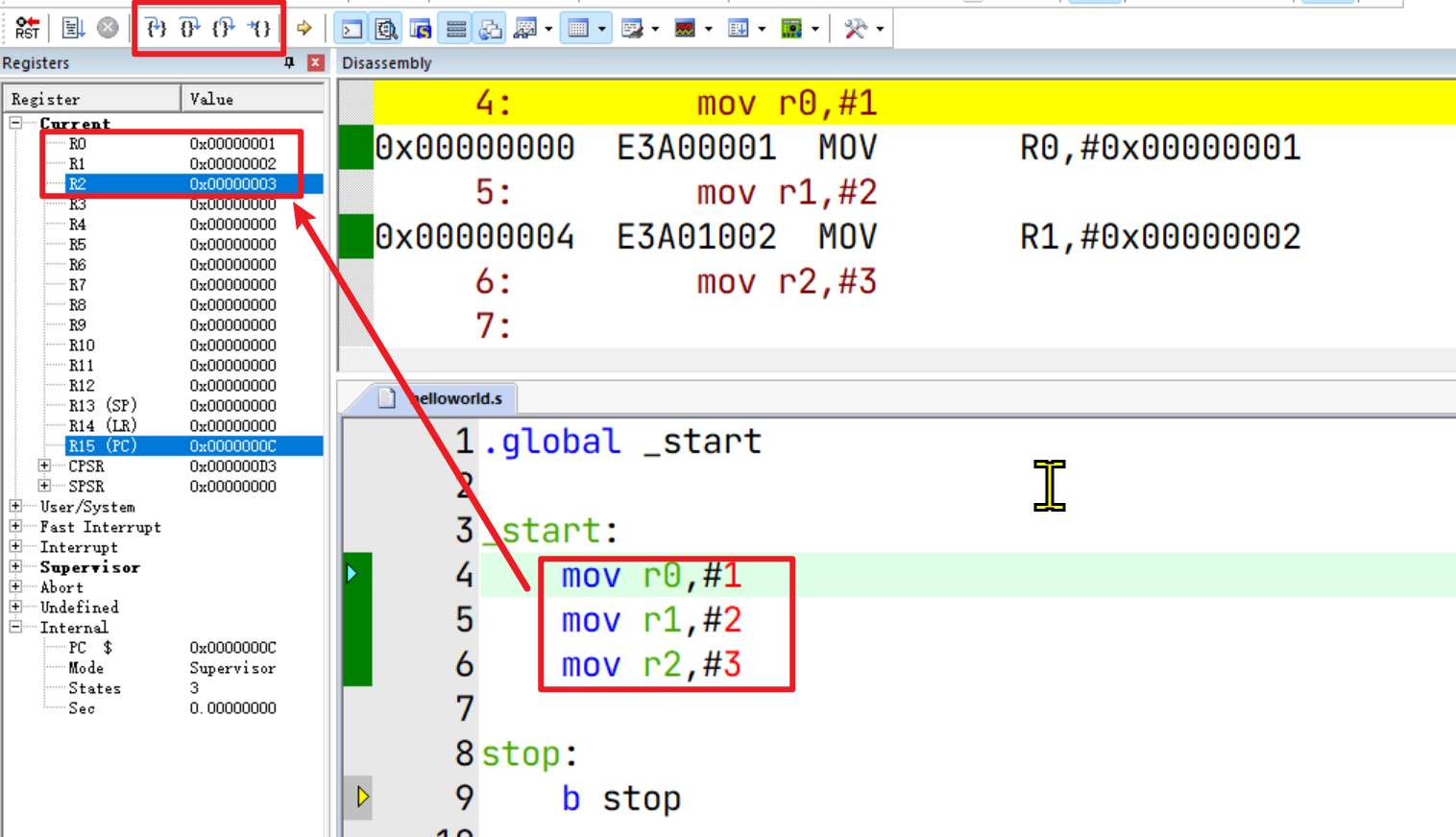
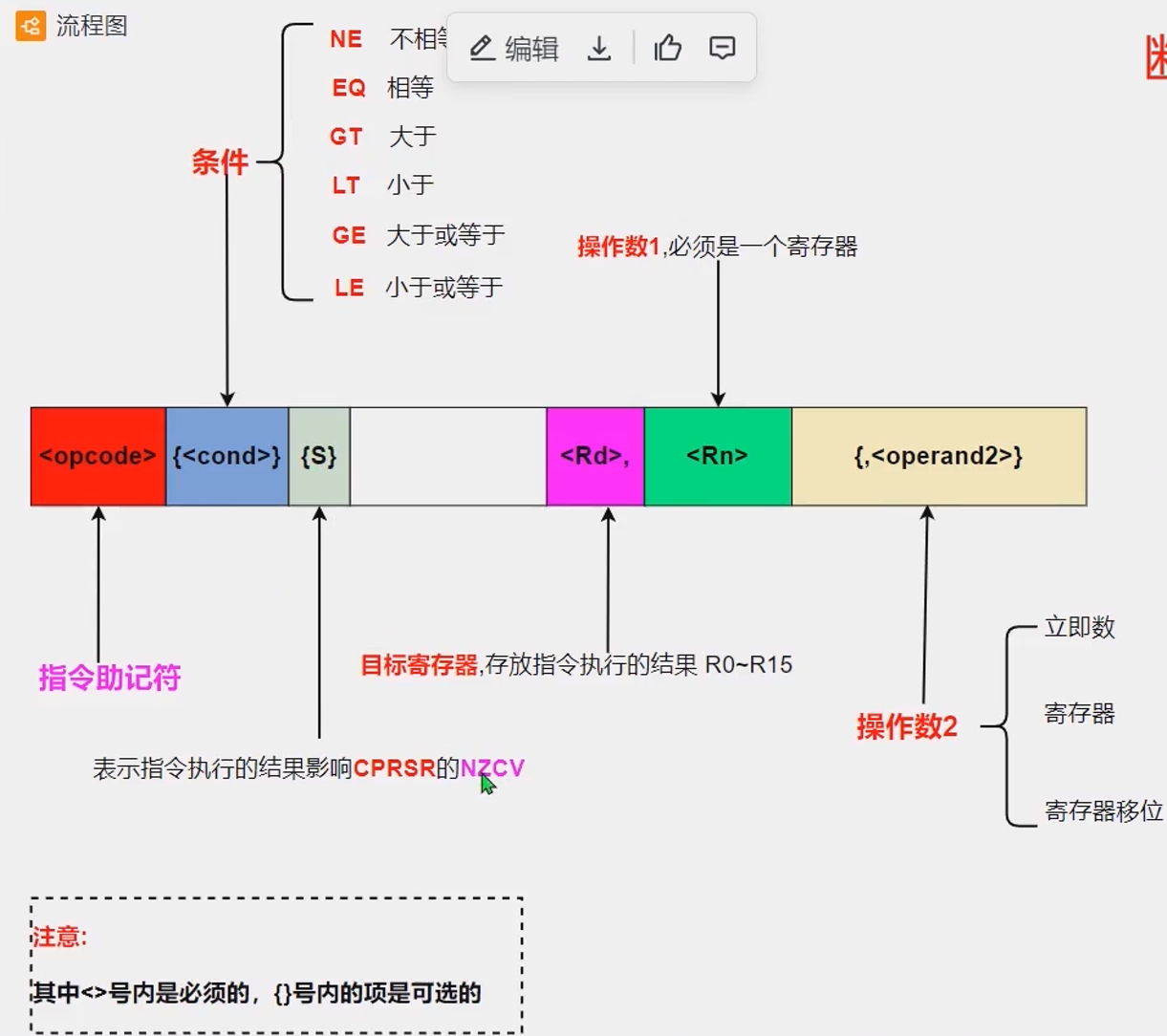
指令格式
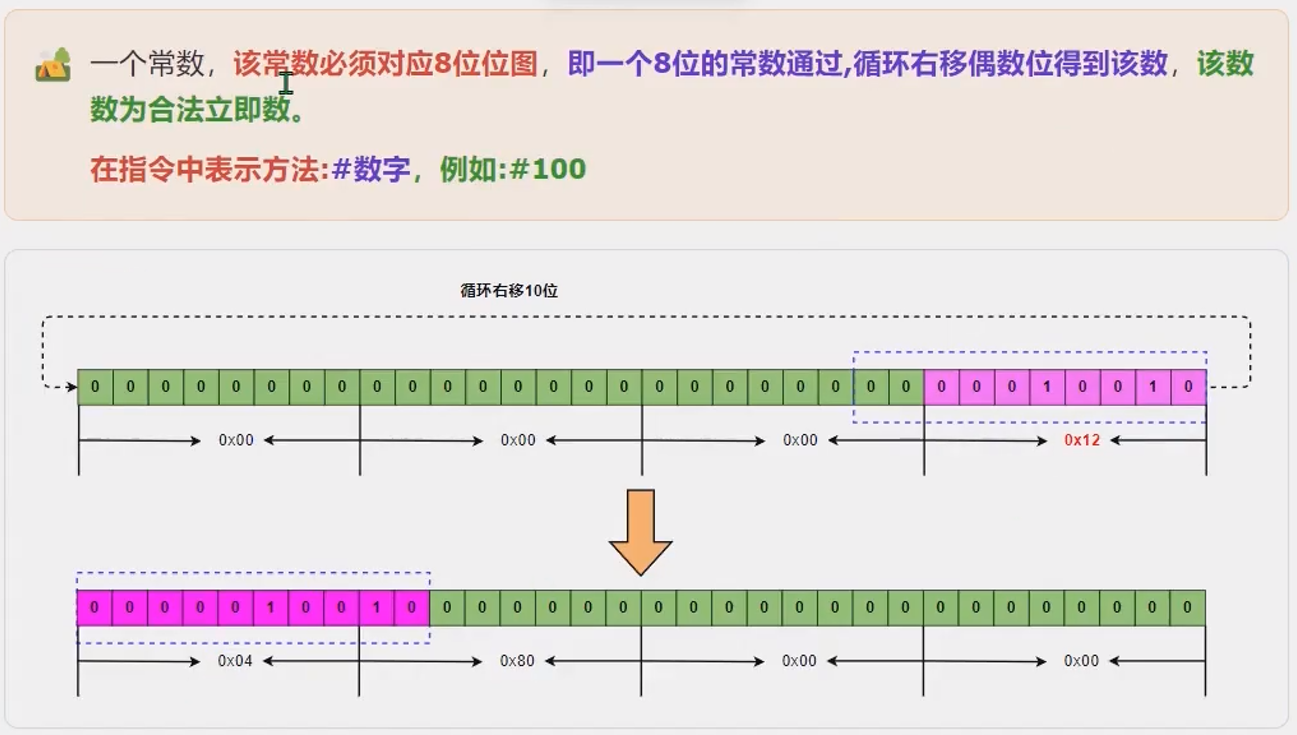
合法立即数
立即数使用 #数字来表示

寄存器移位

常用ARM核指令
参见手册中的 A8.8 Alphabetical list of instructions章节
数据传送指令
MOV

MVN
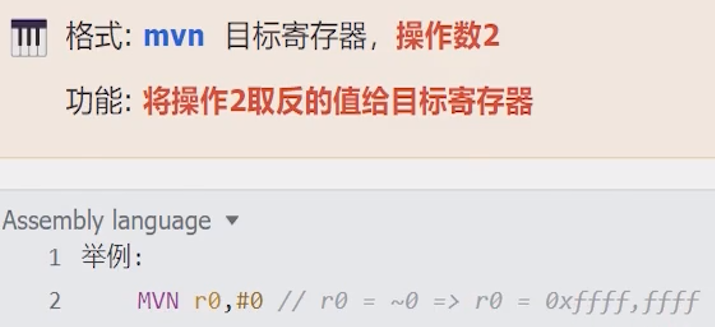
LDR
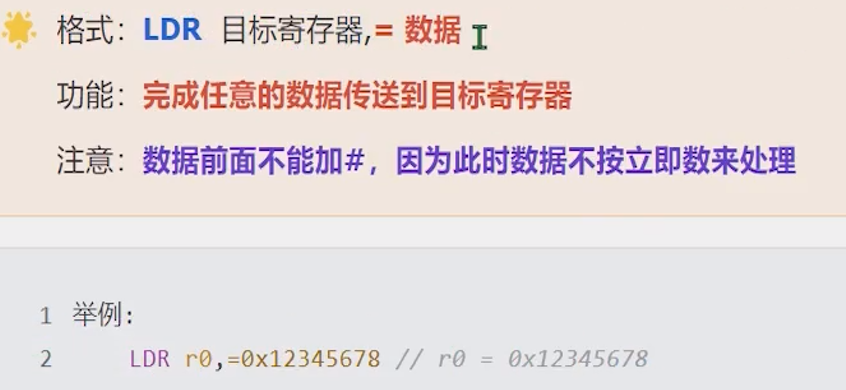
注意:数字常量前需要加上“=”,这是常量/字面量表示的语法规则
当数据不是合法立即数时,作为MOV的替代指令。这是一条伪指令,底层是通过将数据(=号后面的数字)先存放到内存,再通过LDR(从内存加载到寄存器)指令来实现的。

数据计算指令
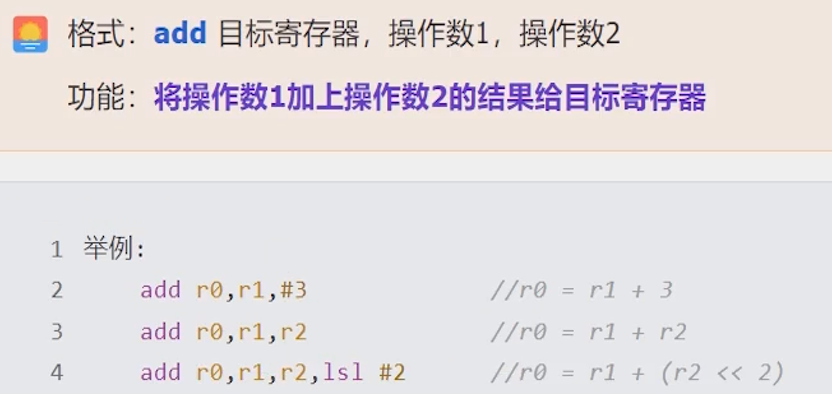
ADD加法
SUB减法

默认情况下SUB是不会影响CPSR的N标志位的,如果需要则要加上S后缀:
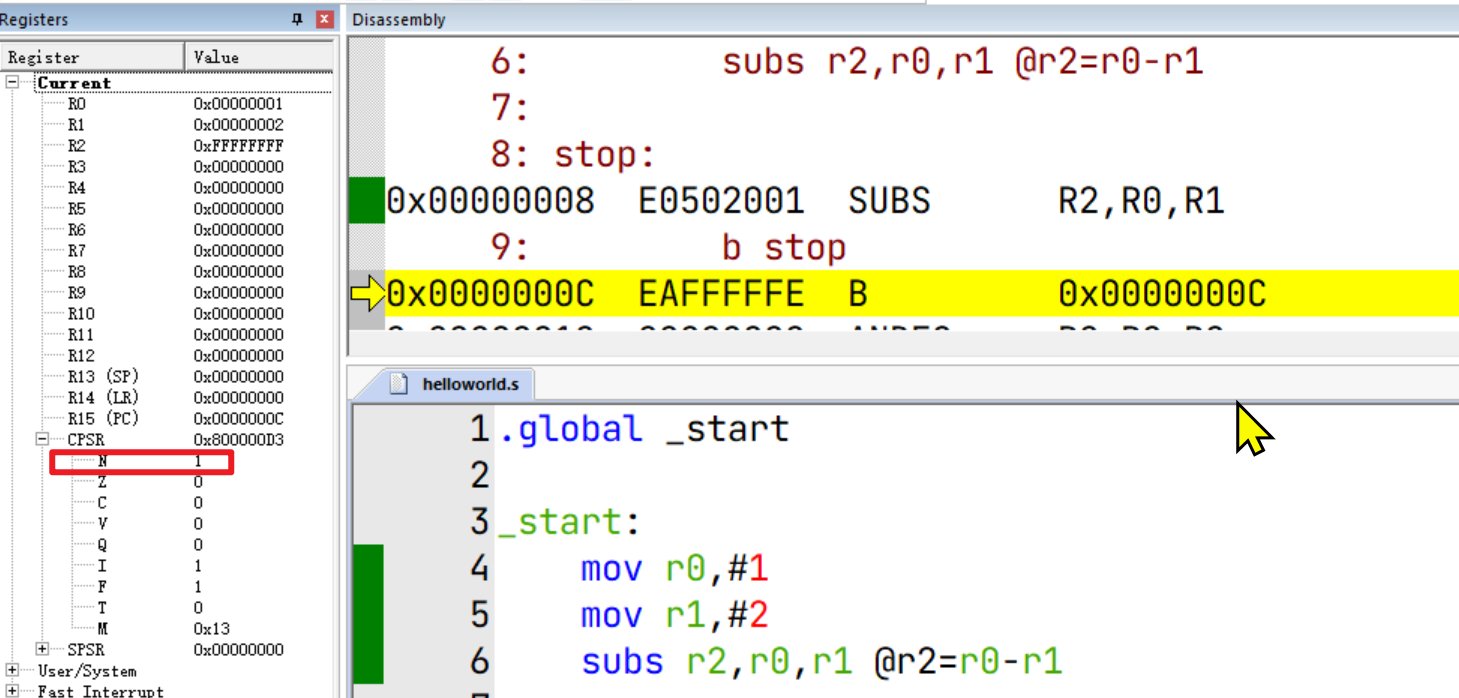
MUL乘法
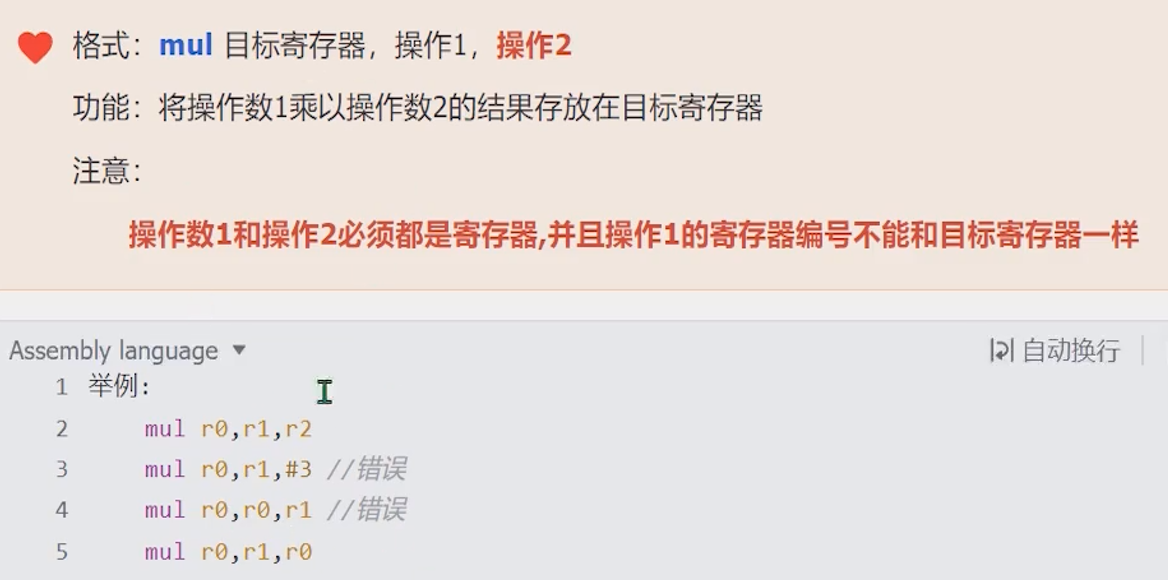
练习
练习1:
(2<<2)-5+0x12345678, 计算的结果存放在r0练习2:
25-3*5+6 最终的计算结果存放在r0中
.global _start
_start:
mov r0,#2
mov r1,r0,lsl #2
sub r1,r1,#5
ldr r0,=0x12345678
add r1,r1,r0
stop:
b stop
.global _start
_start:
mov r0,#3
mov r1,#5
mul r2,r0,r1 @r0=3*5
mov r1,#25
sub r0,r1,r2 @r0=25-15
add r0,r0,#6 @r0=10+6
stop:
b stop
位运算指令
AND

ORR-按位或

EOR-按位异或(Exclusive OR)

BIC-位清除指令

练习
.global _start
_start:
ldr r0,=0x12345678
ldr r1,=0xFFFF0000
bic r1,r0,r1
mov r0,r0,lsr #16
add r0,r0,r1
stop:
b stop
.global _start
_start:
ldr r0,=0xabcd
mov r1,#0x7
bic r0,r1,lsl #1
mov r1,#0x5
orr r0,r1,lsl #1
mov r1,#0x1f
bic r0,r1,lsl #7
stop:
b stop
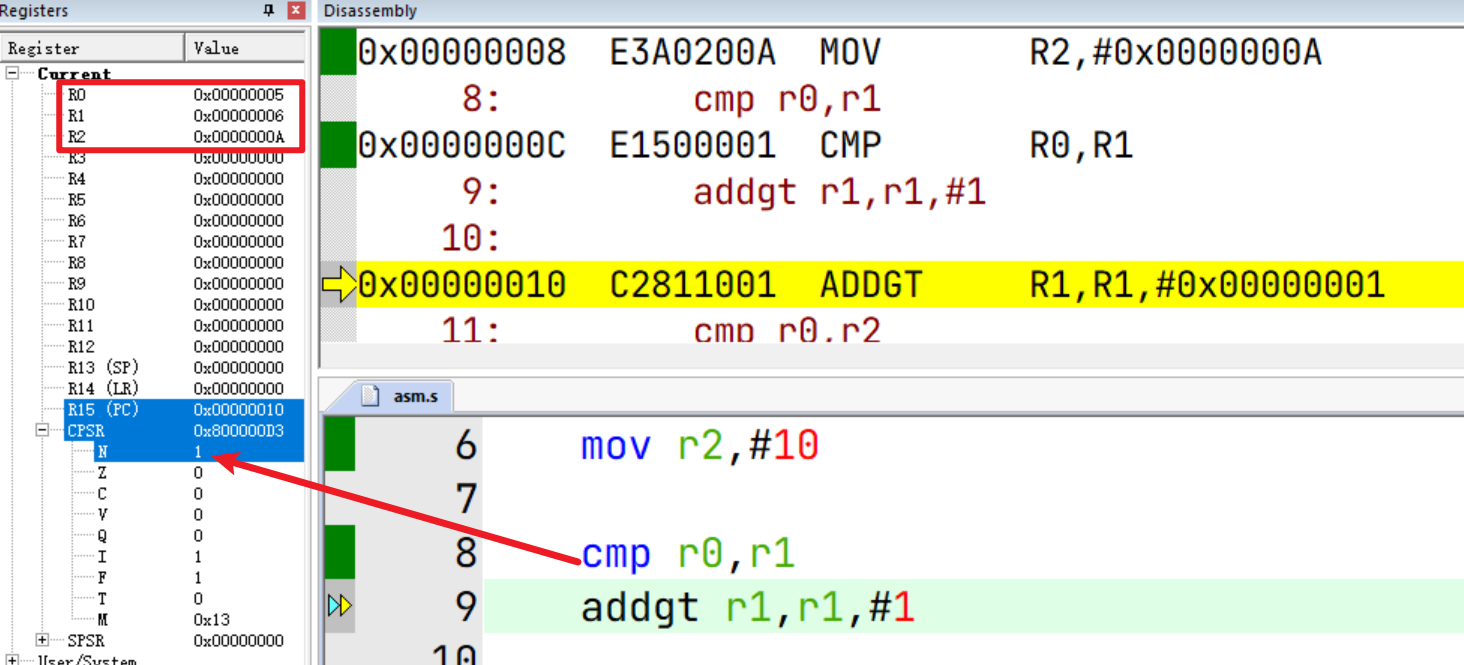
比较指令CMP

.global _start
_start:
mov r0,#5
mov r1,#6
mov r2,#10
cmp r0,r1
addgt r1,r1,#1
cmp r0,r2
addle r2,r2,#1
stop:
b stop
跳转指令
B/BL

Branch causes a branch to a target address.
B指令用于跳转到一个目标地址(指令存放地址),该指令会修改PC的值,就像从处理器的顺序执行路径开了一个分岔一样,让处理器从既定的顺序指令序列跳到了另一个指令序列。常用于函数调用、中断处理。
BL指令在B指令的基础之上增加了一个操作:将跳转前PC的值保存到LR寄存器中。这样如果想从分岔回到原来的路径继续执行,只需将LR会写PC即可。
死循环的实现
.global _start
_start:
mov r0,#1
mov r1,#2
b _start
函数调用
.global _start
_start:
mov r0,#1
mov r1,#2
bl add
mov r3,r2
stop:
b _start
add:
add r2,r0,r1
mov pc,lr
通过单步调试观察PC的变化我们可以发现每条汇编指令的地址是按照编写顺序从上到下依次编址的,每条指令地址相隔4个字节,也即偏移量为0x4
.global _start
_start:
mov r0,#1 @instruction address => 0x00000000
mov r1,#2 @instruction address => 0x00000004
bl add @instruction address => 0x00000008
mov r3,r2 @instruction address => 0x0000000C
stop:
b _start @instruction address => 0x00000010
add:
add r2,r0,r1 @instruction address => 0x00000014
mov pc,lr @instruction address => 0x00000018给PC赋值

B/BL指令有个限制:跳转的目标地址和当前PC中的指令地址之间的偏移量不能超过32M大小。如果超过了这个范围,我们可以直接赋值PC来实现跳转。
.global _start
_start:
mov r0,#1
mov r1,#2
ldr pc,=add_label
back_label:
mov r3,#10
stop:
b stop
add_label:
add r2,r0,r1
ldr pc,=back_label
其中标签名字面量(add_label、back_label、stop)本质上就是给标签名冒号后的指令地址取了个别名,其值就是冒号后第一条指令的地址;且标签声明不属于指令,也就不占用内存空间,因此 ldr pc,=add_label等价于 ldr pc,=0x00000014:
.global _start
_start:
mov r0,#1 @0x00000000
mov r1,#2 @0x00000004
ldr pc,=add_label @0x00000008
back_label:
mov r3,#10 @0x0000000C
stop:
b stop @0x00000010
add_label:
add r2,r0,r1 @0x00000014
ldr pc,=back_label @0x00000018
练习

.global _start
_start:
mov r0,#0 @sum=0
mov r1,#1 @i=1
loop:
cmp r1,#100
bgt stop @stop loop if r1 > 100
add r0,r0,r1 @sum+=i
add r1,r1,#1 @i++
b loop @continue loop
stop:
b stop
单个数据访问(一次性访问一个字宽数据)

寄存器间接寻址
LDR <目标寄存器> [源寄存器]:从源寄存器指定的地址中加载数据到目标寄存器
LDR <源寄存器> [目标寄存器]:将源寄存器中的数据存储到目标寄存器指定的内存地址中
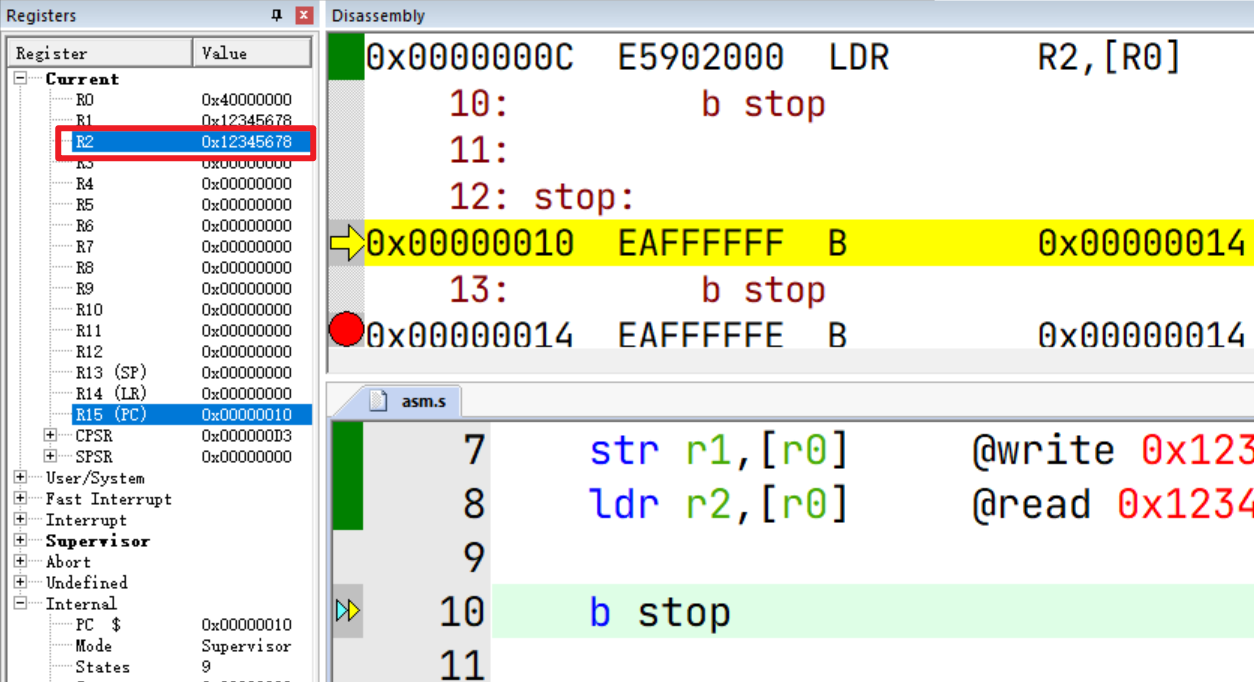
如下代码将数据 0x12345678 写(存储)到内存地址 0x40000000中,并从改地址读(加载)数据到R2寄存器中
.global _start
_start:
mov r0,#0x40000000
ldr r1,=0x12345678
str r1,[r0] @write 0x12345678 to memory address 0x40000000 => *r0 = r1
ldr r2,[r0] @read 0x12345678 from memory address 0x40000000 => r2 = *r0
b stop
stop:
b stop
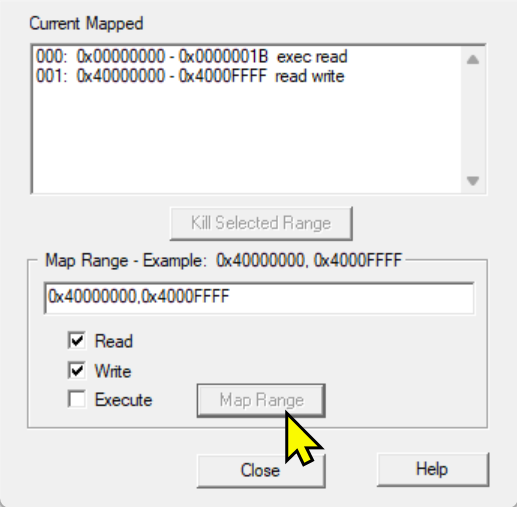
点击调试后,需要映射一下当前程序可访问的内存空间:
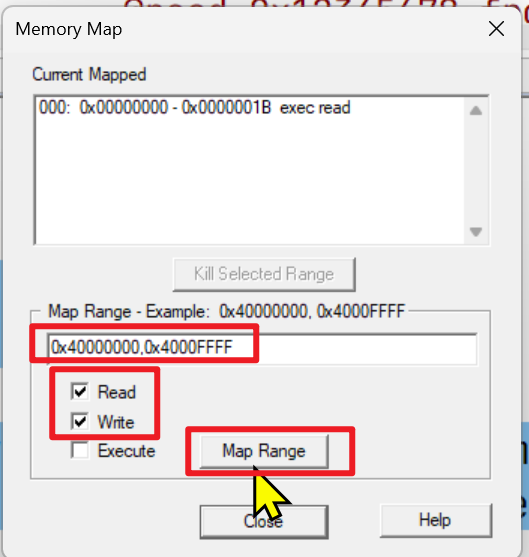
0x40000000,0x4000FFFF
然后可以打开内存查看窗口:

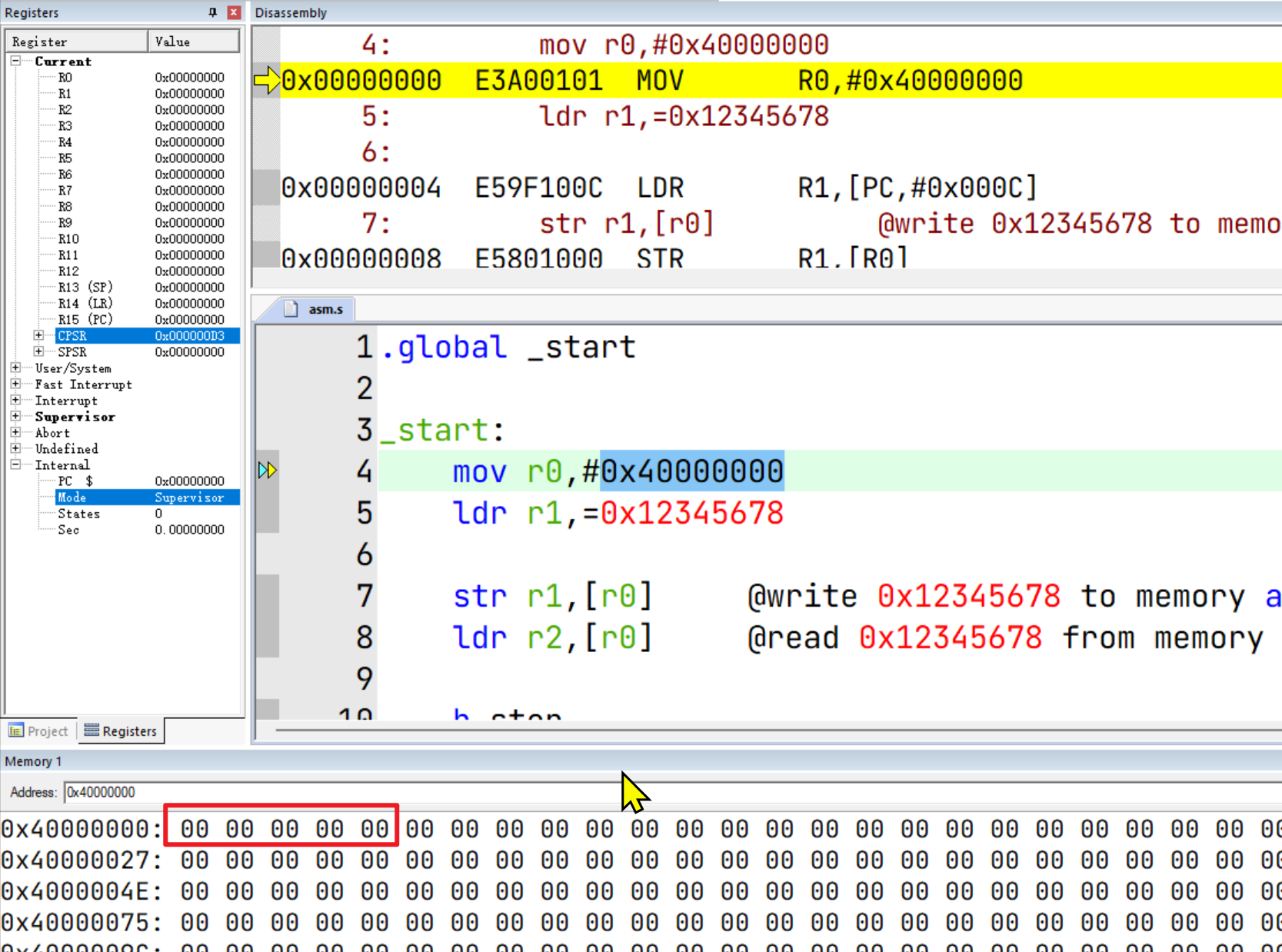
然后步进到 str r1,[r0]执行之后,会发现数据已被写入对应的内存。这里值得注意的是,存储方式是字节小端法。
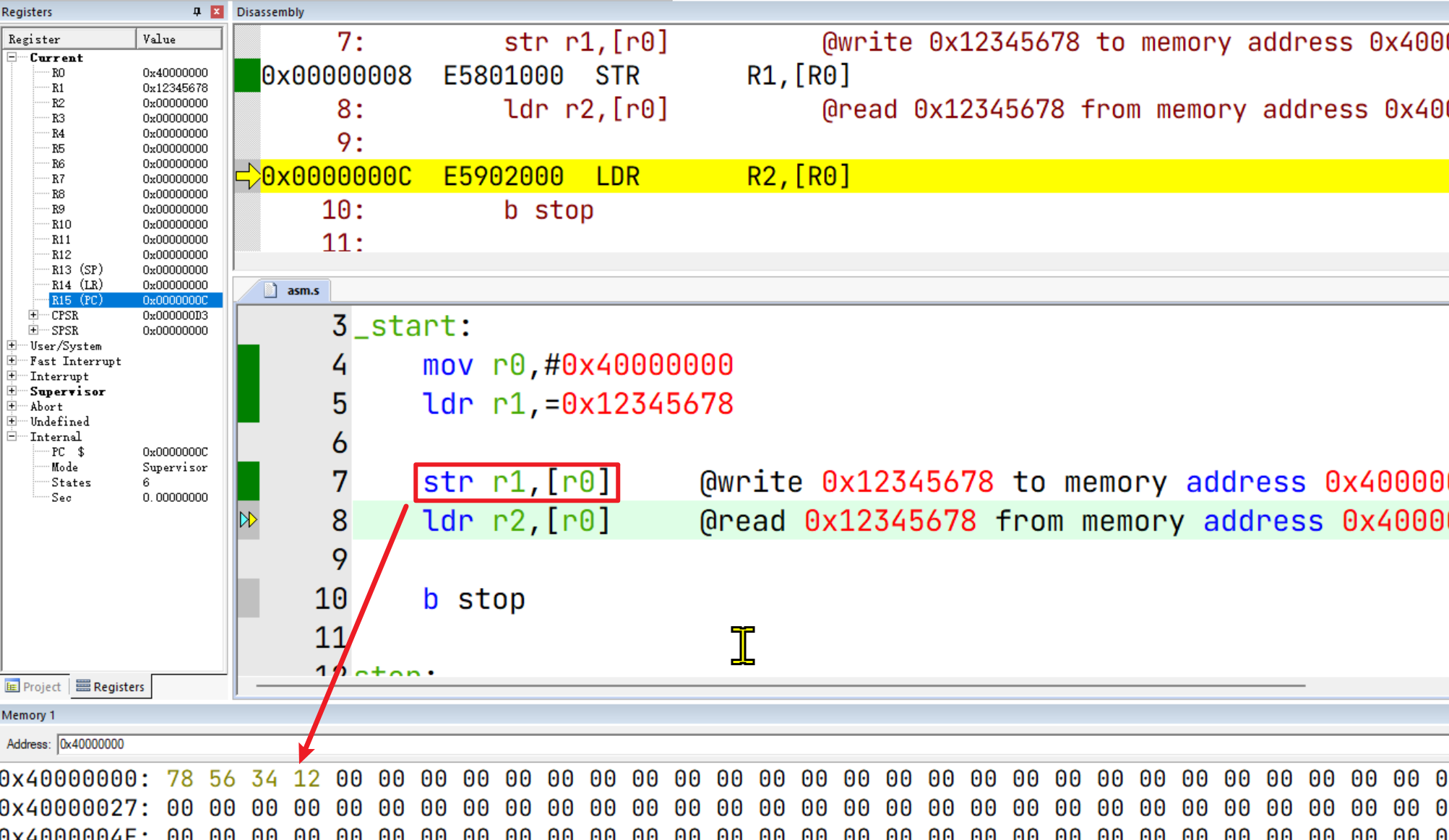
再进一步,数据从内存加载到了R2寄存器中
基地址变址寻址

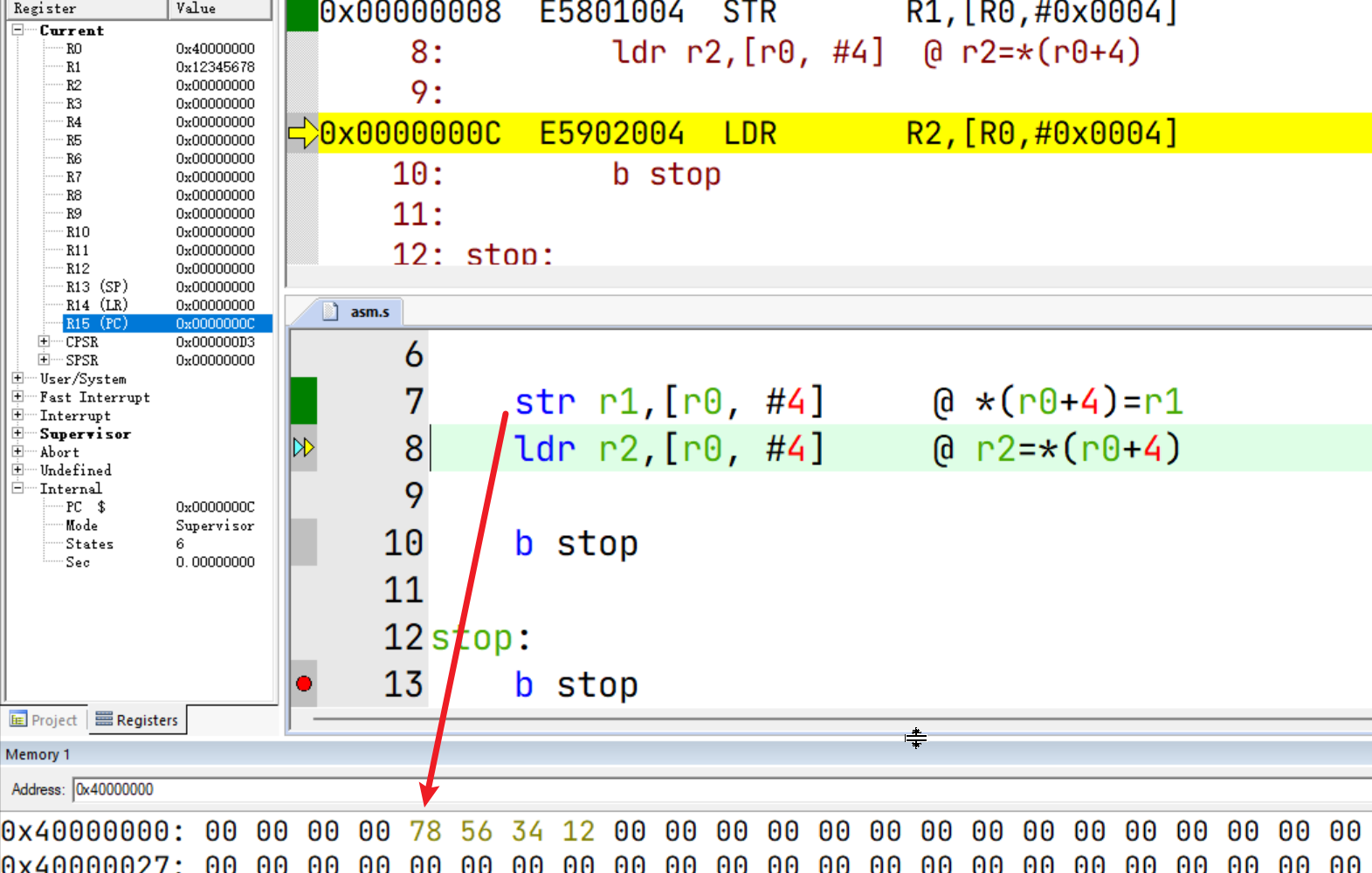
偏移量寻址
Offset addressing
The offset value is applied to an address obtained from the base register. The result is used as the
address for the memory access. The value of the base register is unchanged.
The assembly language syntax for this mode is:
[<Rn>, <offset>]
LDR/STR [<Rn>, <offset>]:Rn为基地址,offset为偏移字节数
类比理解:C语言中通过指针加偏移量来访问内存(num = *(p+1)),该操作不会改变指针的值。
.global _start
_start:
mov r0,#0x40000000
ldr r1,=0x12345678
str r1,[r0, #4] @ *(r0+4)=r1
ldr r2,[r0, #4] @ r2=*(r0+4)
b stop
stop:
b stop
注意:每次点击debug后做一下内存映射:
前索引寻址
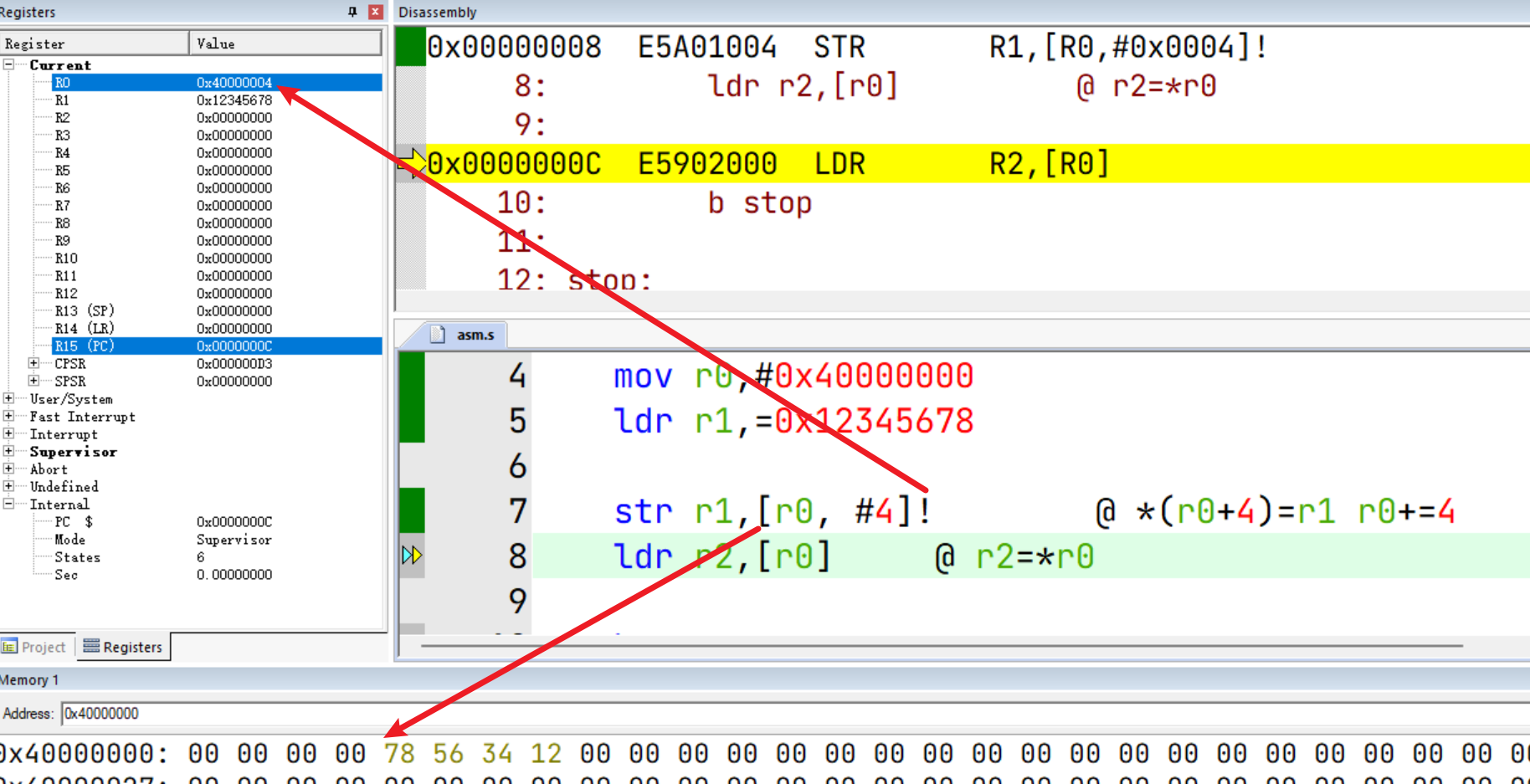
Pre-indexed addressing
The offset value is applied to an address obtained from the base register. The result is used as the
address for the memory access, and written back into the base register.
The assembly language syntax for this mode is:
[<Rn>, <offset>]!
LDR/STR [<Rn>, <offset>]!:Rn为基地址,offset为偏移字节数。
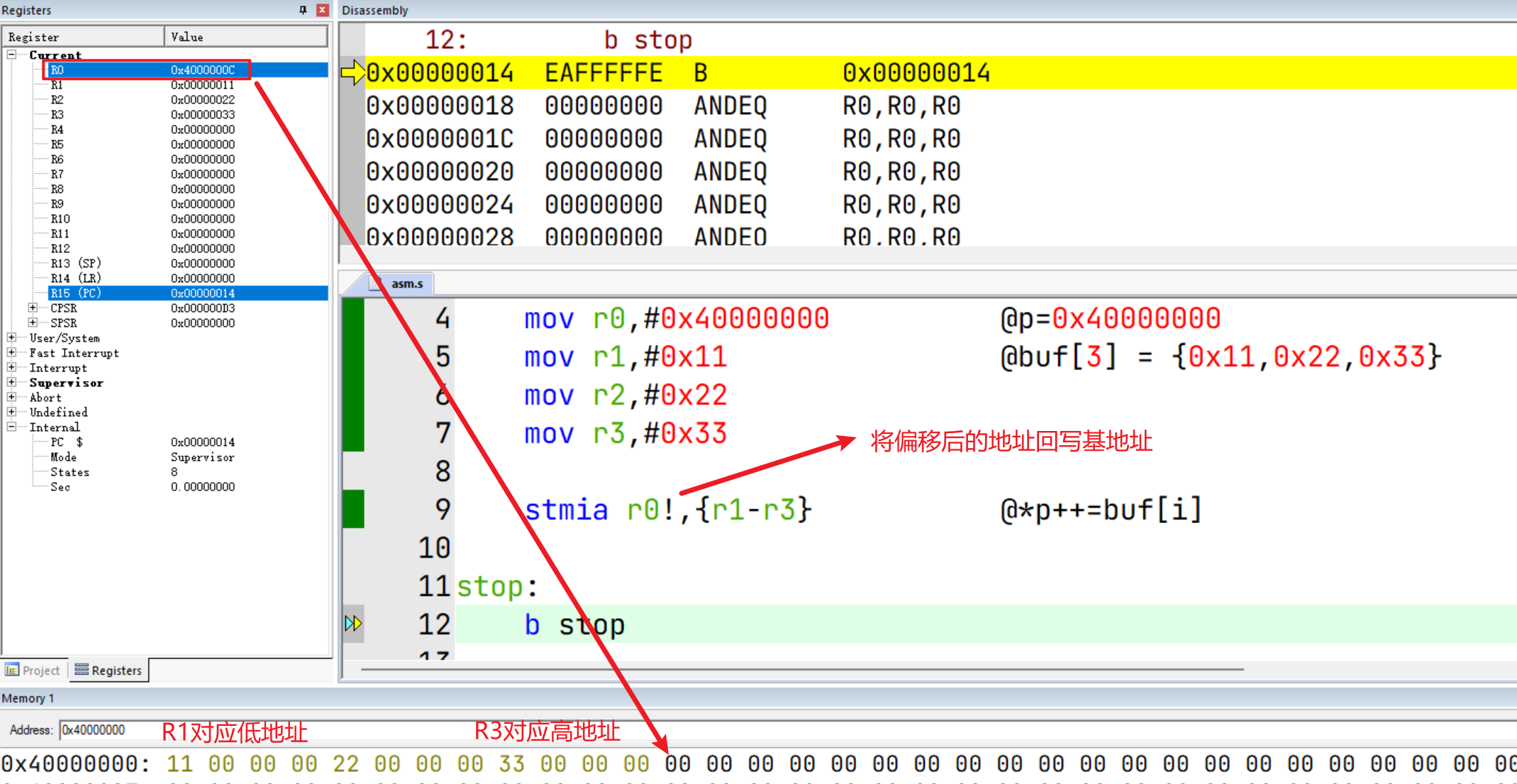
该指令在偏移量寻址的基础上加了个 !,标示在内存访问之后将访问的地址回写基地址Rn。
类比理解:num = *p++ => num = *p; p++;
.global _start
_start:
mov r0,#0x40000000
ldr r1,=0x12345678
str r1,[r0, #4]! @ *(r0+4)=r1 r0+=4
ldr r2,[r0] @ r2=*r0
b stop
stop:
b stop
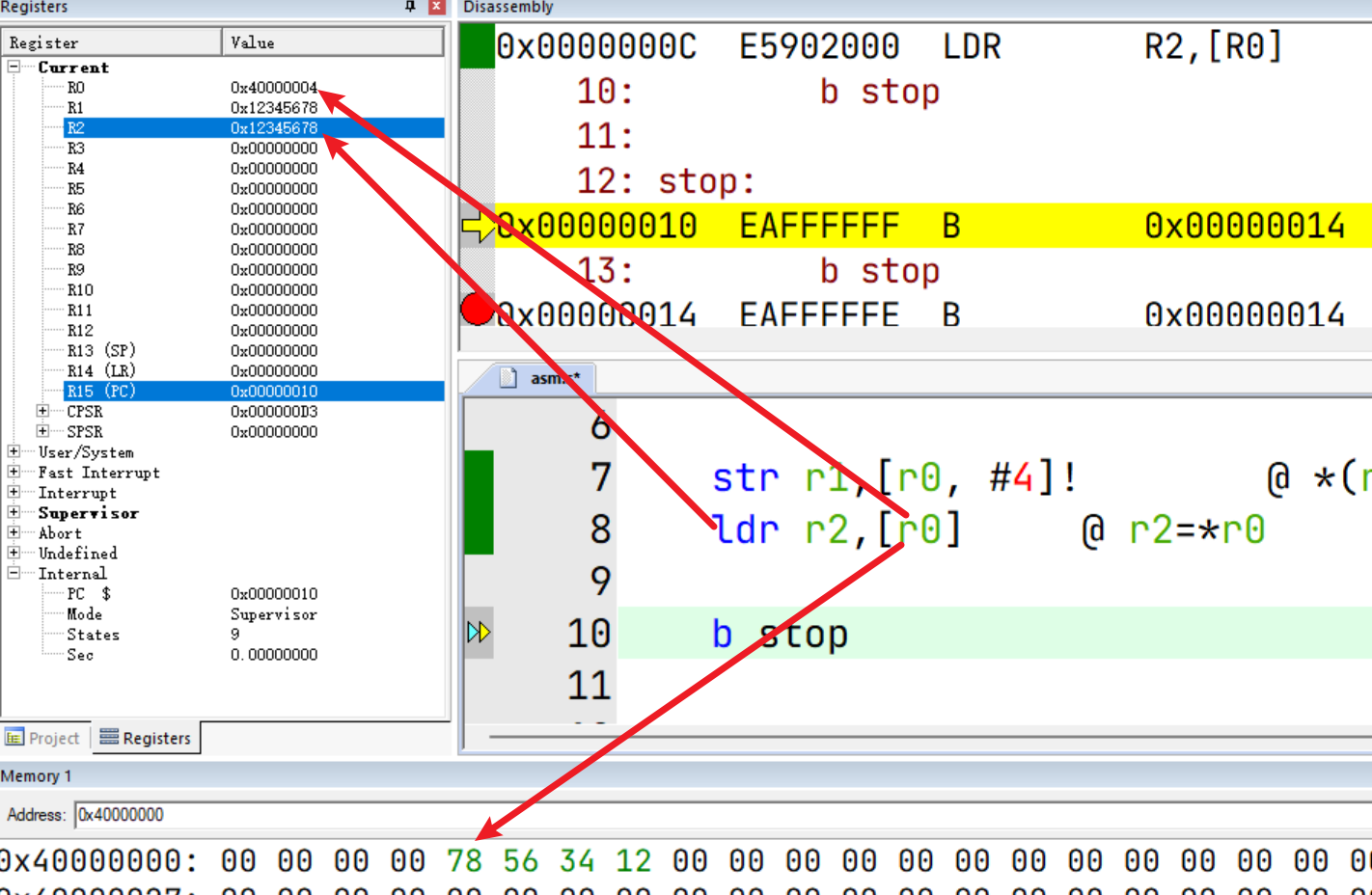
后索引寻址
Post-indexed addressing
The address obtained from the base register is used, unchanged, as the address for the memory
access. The offset value is applied to the address, and written back into the base register
The assembly language syntax for this mode is:
[<Rn>], <offset>
LDR/STR [<Rn>], <offset>:Rn为基地址,offset为偏移字节数。
该指令先从Rn访问内存,然后再将偏移量更新到Rn中。
类比理解:num = *p; p += offset
.global _start
_start:
mov r0,#0x40000000
ldr r1,=0x12345678
str r1,[r0],#4 @ *(r0)=r1 r0+=4
sub r0,r0,#4 @ r0-=4
ldr r2,[r0] @ r2=*r0
b stop
stop:
b stop
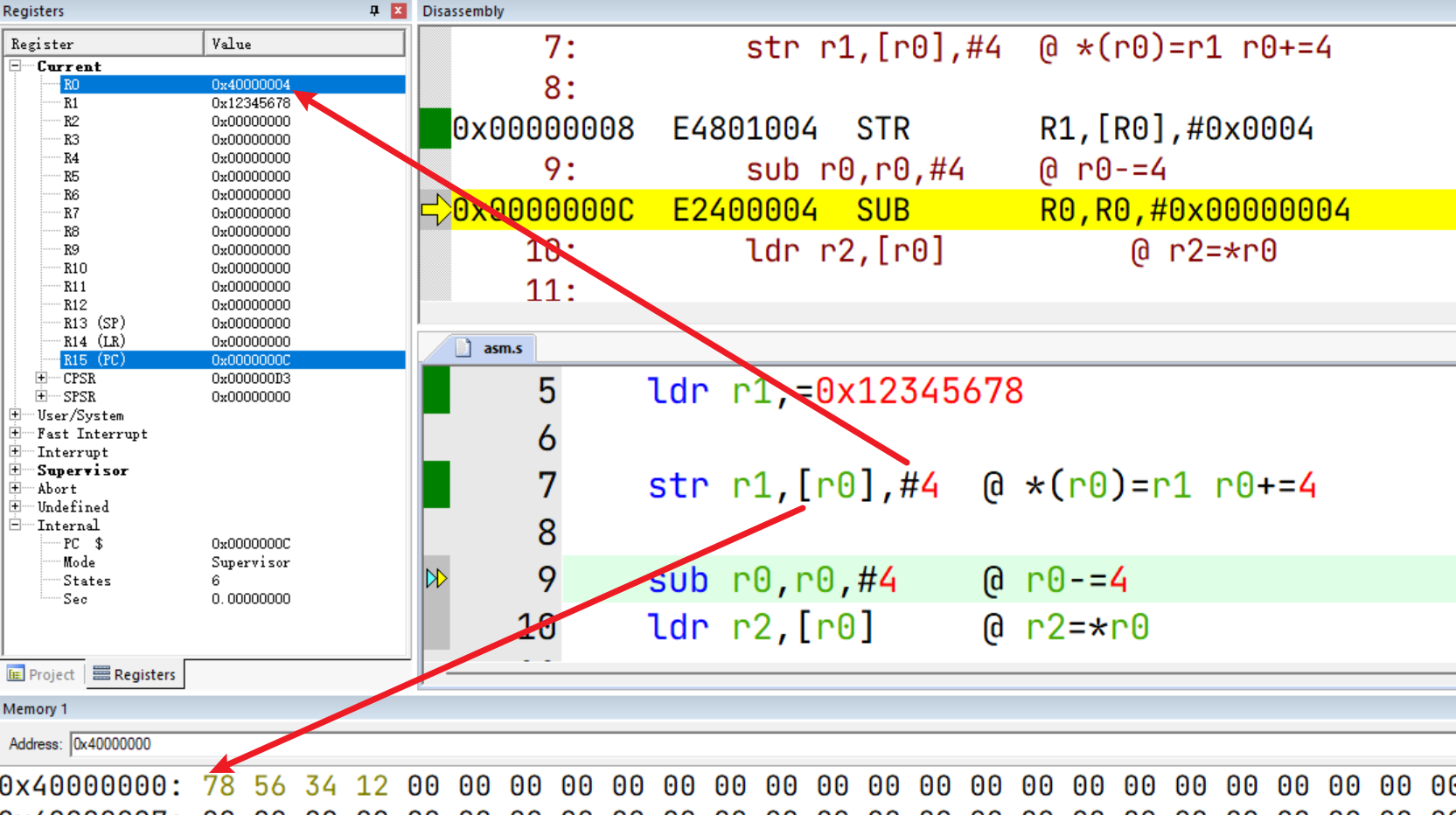
🌟总结
- 偏移量寻址:就是在给定地址上加减一个偏移量来访问内存(relative)
- 前索引:先对给定地址增减偏移量进行更新,再访问更新后的地址
- 后索引:先访问给定地址,再对给定地址加减偏移量并更新
练习

.global _start
_start:
mov r0,#1 @i=1
mov r1,#0x40000000 @p
bl write_data
mov r0,#1 @i=1
mov r1,#0x40000000 @p=>0x40000000
ldr r2,=0x40000100 @q=>0x40000100
mov r3,#0 @num=0
bl read_data
stop:
b stop
write_data:
str r0,[r1],#4 @*p++=i
add r0,r0,#1 @i++
cmp r0,#10
ble write_data @while(i<=10)
mov pc,lr @return
read_data:
ldr r3,[r1],#4 @num=*p++
str r3,[r2],#4 @*q++=num
add r0,r0,#1 @i++
cmp r0,#10
ble read_data @while(i<=10)
mov pc,lr @return

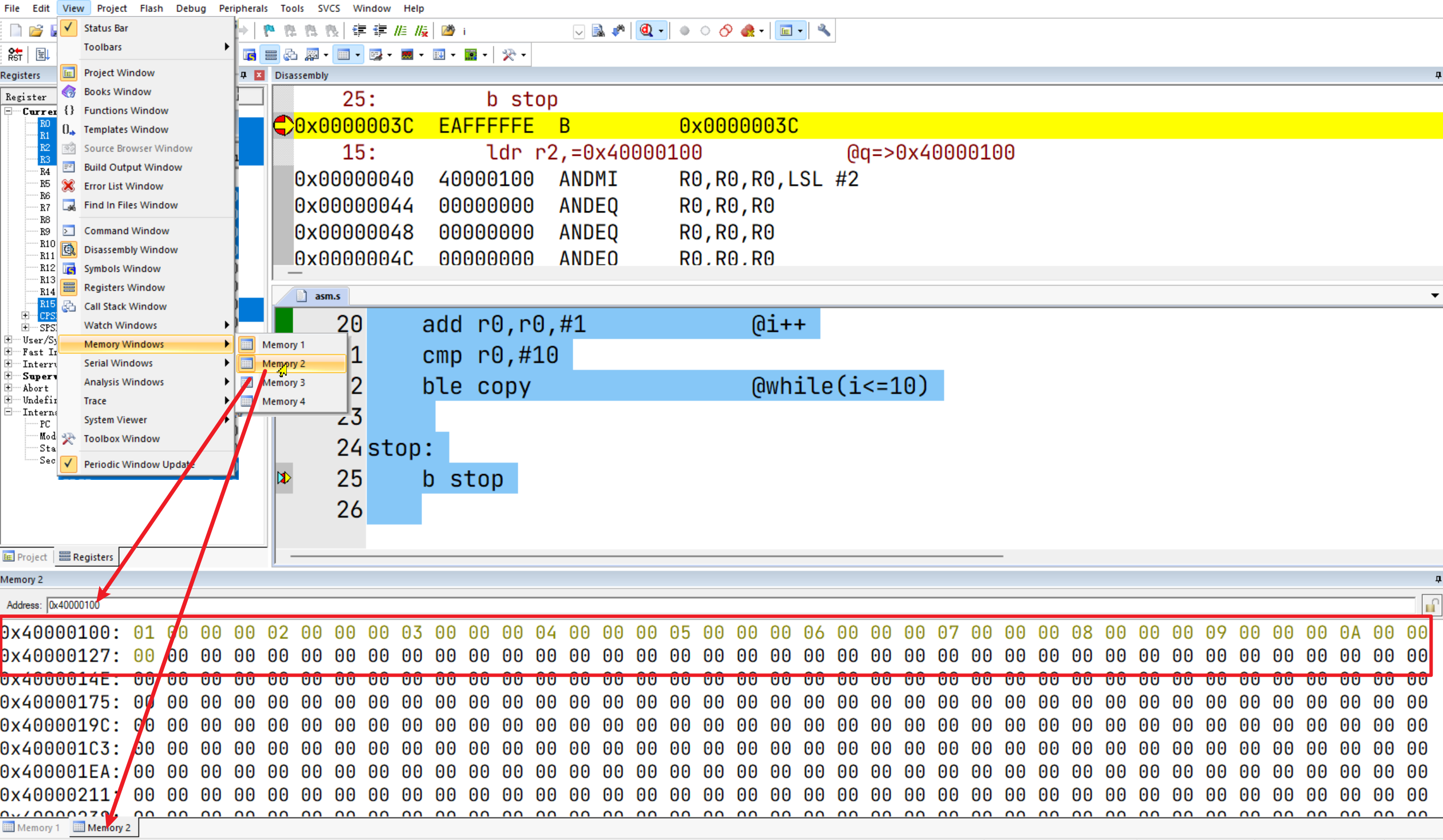
.global _start
_start:
ldr r0,=0x1234
ldr r1,=0x40000000 @p=0x40000000
str r0,[r1],#4 @*p++=0x1234
ldr r0,=0xabcd
str r0,[r1],#-4 @*p=0xabcd, p-=4
ldr r2,[r1],#4 @num1=*p++
ldr r3,[r1] @num2=*p
add r0,r2,r3 @sum=num1+num2
stop:
b stop
多个数据访问

指令模式
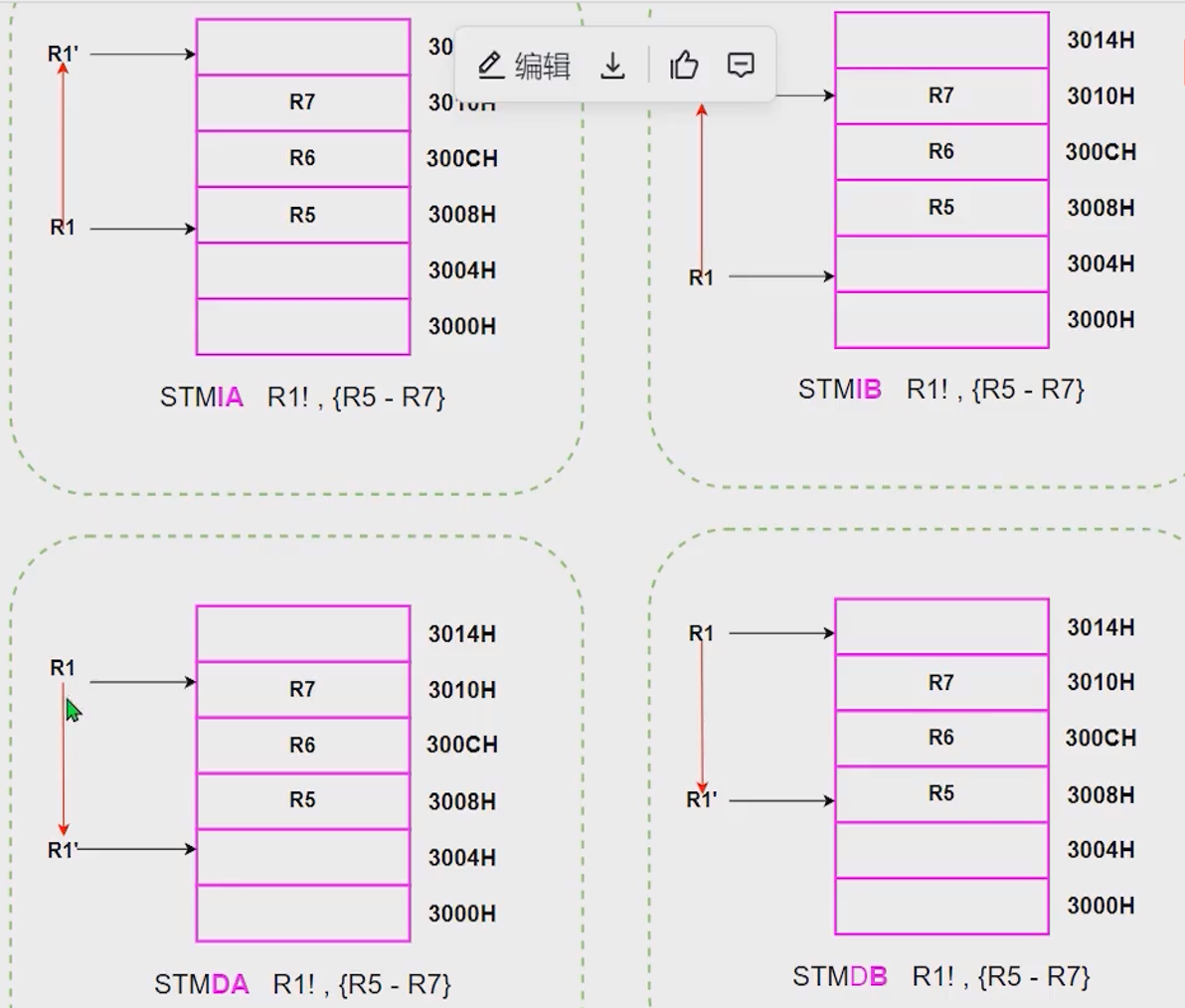
以STM(Store Multiple,写多个数据为例,LDM是类似的):
- STMIA:Increase After,先向基地址写入数据,然后递增基地址
- STMIB:Increase Before,先递增基地址,再向基地址写入数据
- STMDA:Decrease After,先向基地址写入数据,然后递减基地址
- STMDB:Decrease Before,先递减基地址,再向基地址写入数据
.global _start
_start:
mov r0,#0x40000000 @p=0x40000000
mov r1,#0x11 @buf[3] = {0x11,0x22,0x33}
mov r2,#0x22
mov r3,#0x33
stmia r0!,{r1-r3} @*p++=buf[i]
stop:
b stop
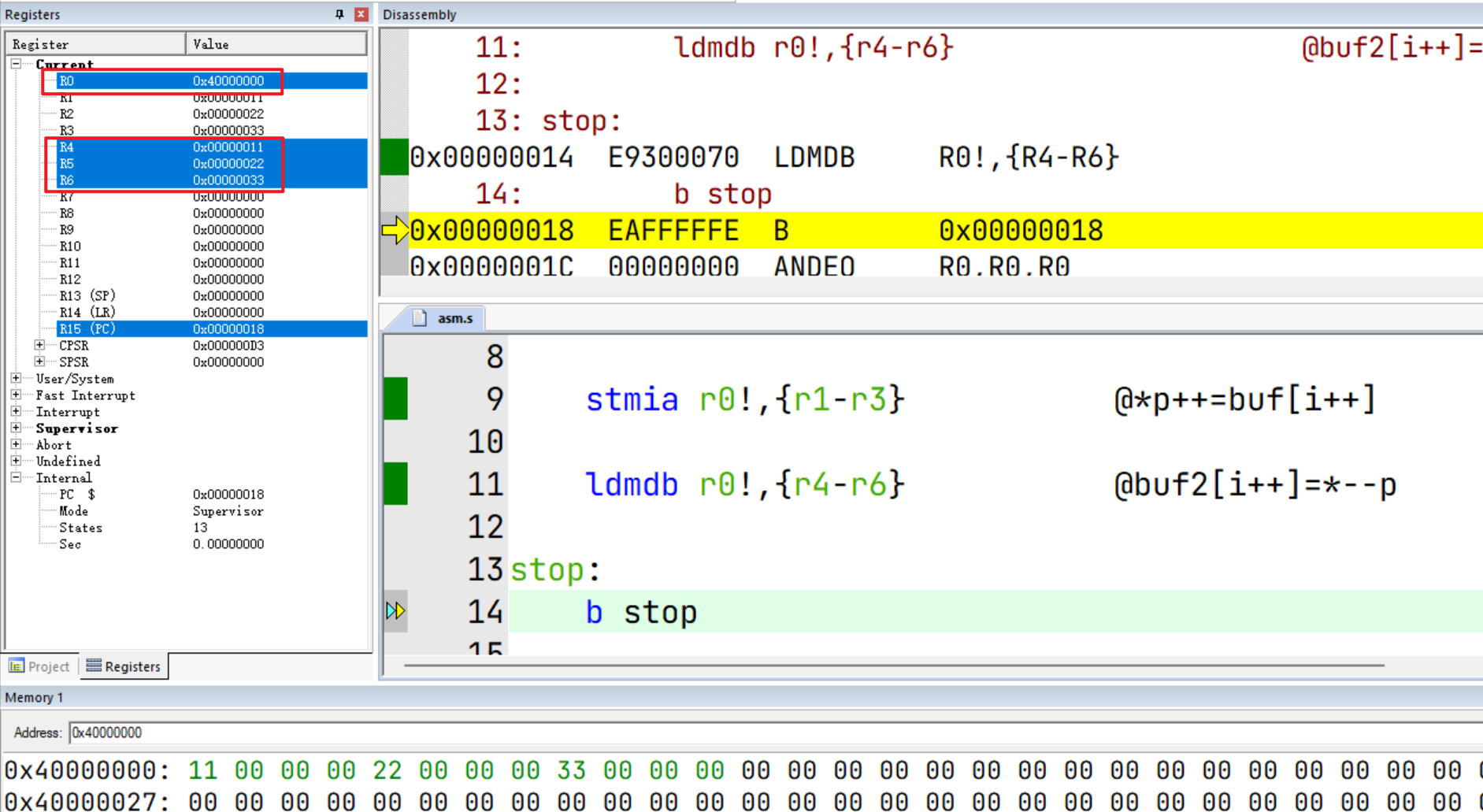
.global _start
_start:
mov r0,#0x40000000 @p=0x40000000
mov r1,#0x11 @buf[3] = {0x11,0x22,0x33}
mov r2,#0x22
mov r3,#0x33
stmia r0!,{r1-r3} @*p++=buf[i++]
ldmdb r0!,{r4-r6} @buf2[i++]=*--p
stop:
b stop
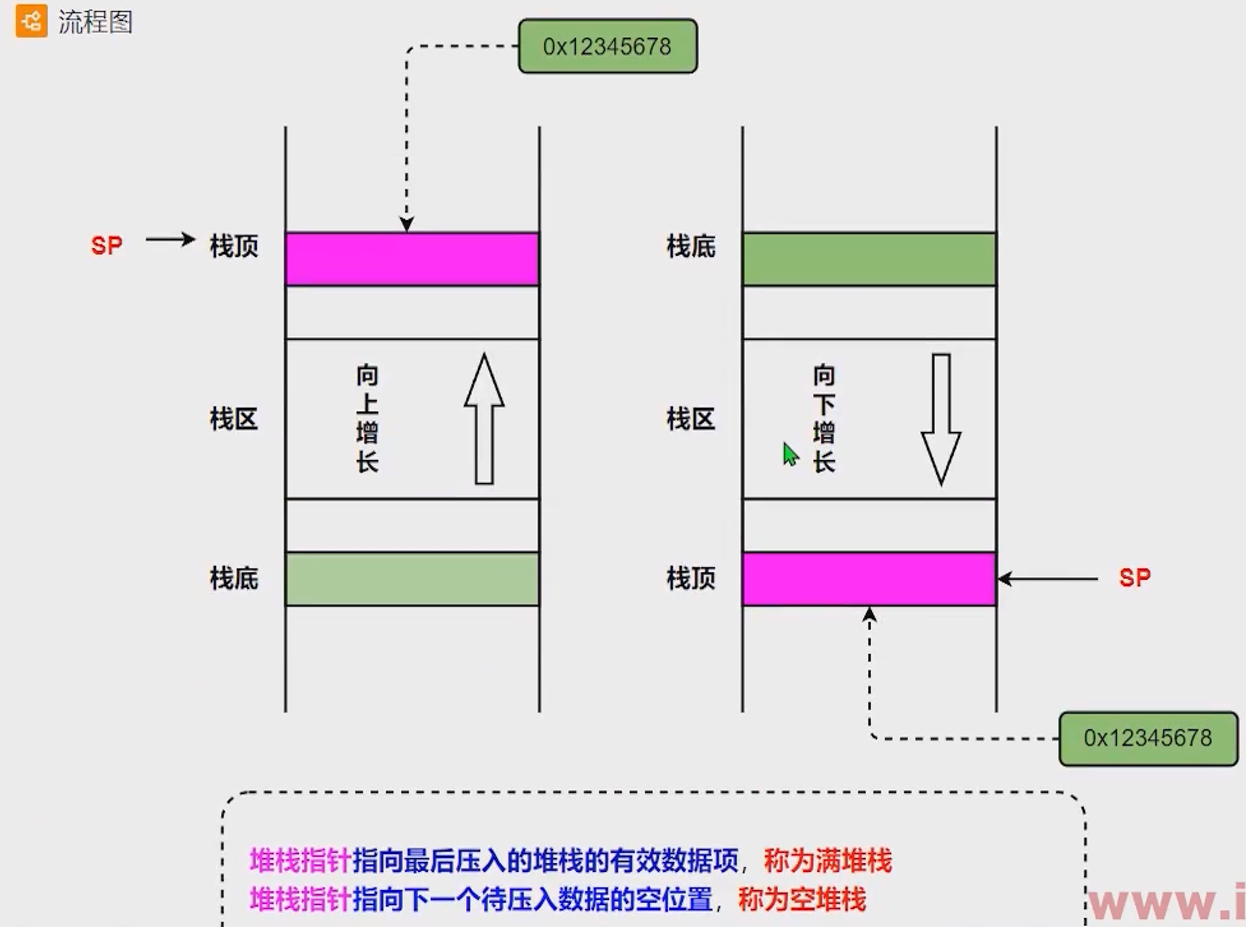
栈操作指令

栈增长模式
自底向上:栈顶指针随着入栈而递增(地址);自顶向下:栈顶指针随着入栈而递减
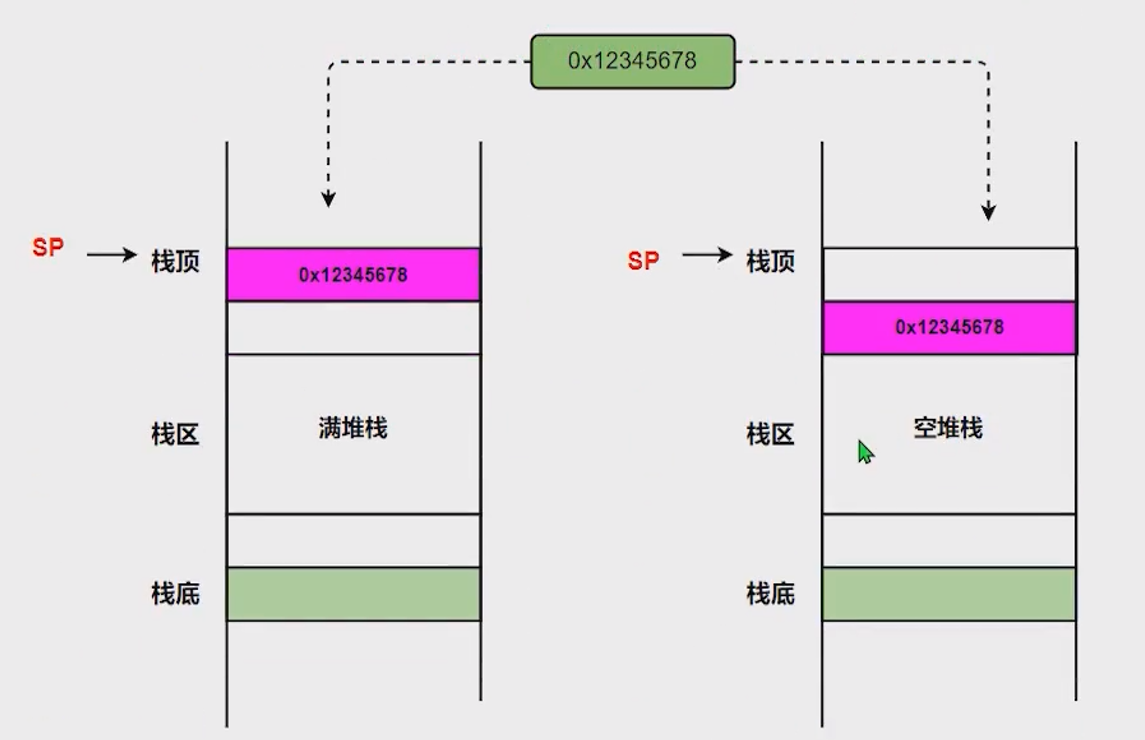
空堆栈和满堆栈
其实就是栈顶指针指向栈顶元素(满堆栈)还是指向下一个入栈元素要存放的位置(空堆栈)
示例:压栈保存,出栈恢复
在程序上下文发生切换时(例如函数调用、中断处理),我们通常需要先将先前程序执行状态相关的信息进行保存,然后在返回时进行恢复。
如下程序以通用寄存器的暂存和恢复为例来模拟这一过程:
.global _start
_start:
mov r1,#0x11
mov r2,#0x22
mov r3,#0x33
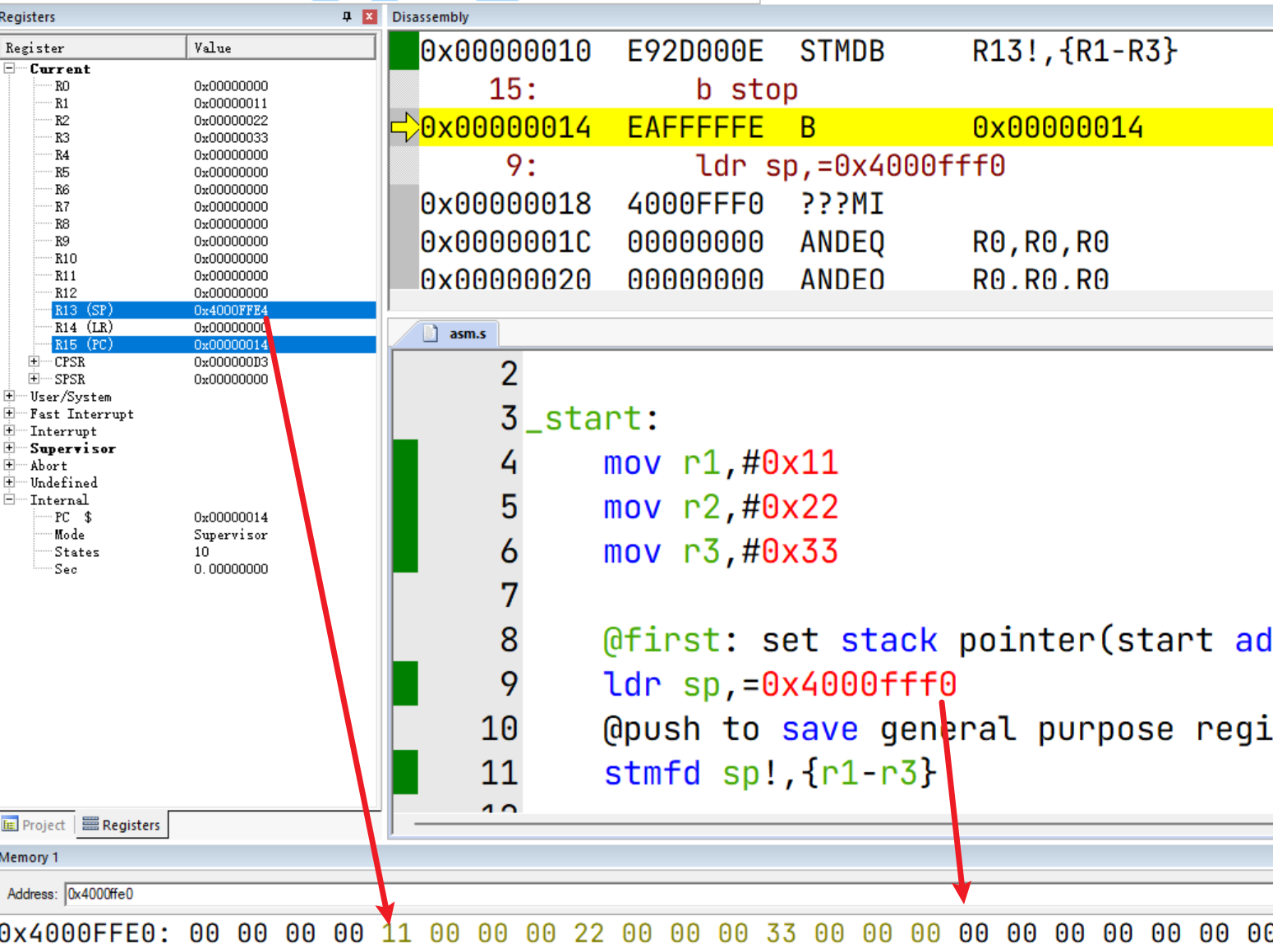
@first: set stack pointer(start address of stack, from high address to low)
ldr sp,=0x4000fff0
@push to save general purpose registers and decrease stack pointer
stmfd sp!,{r1-r3}
stop:
b stop
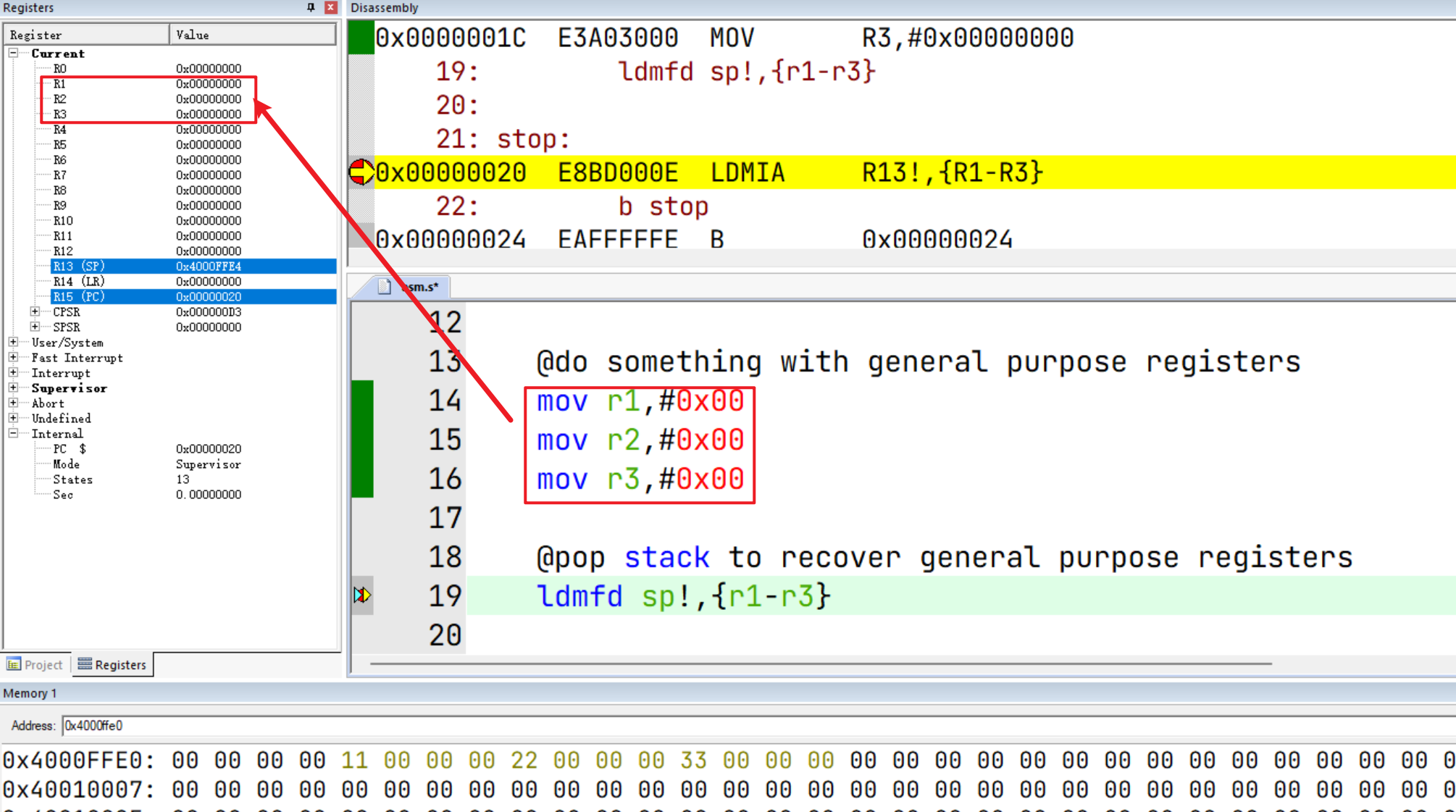
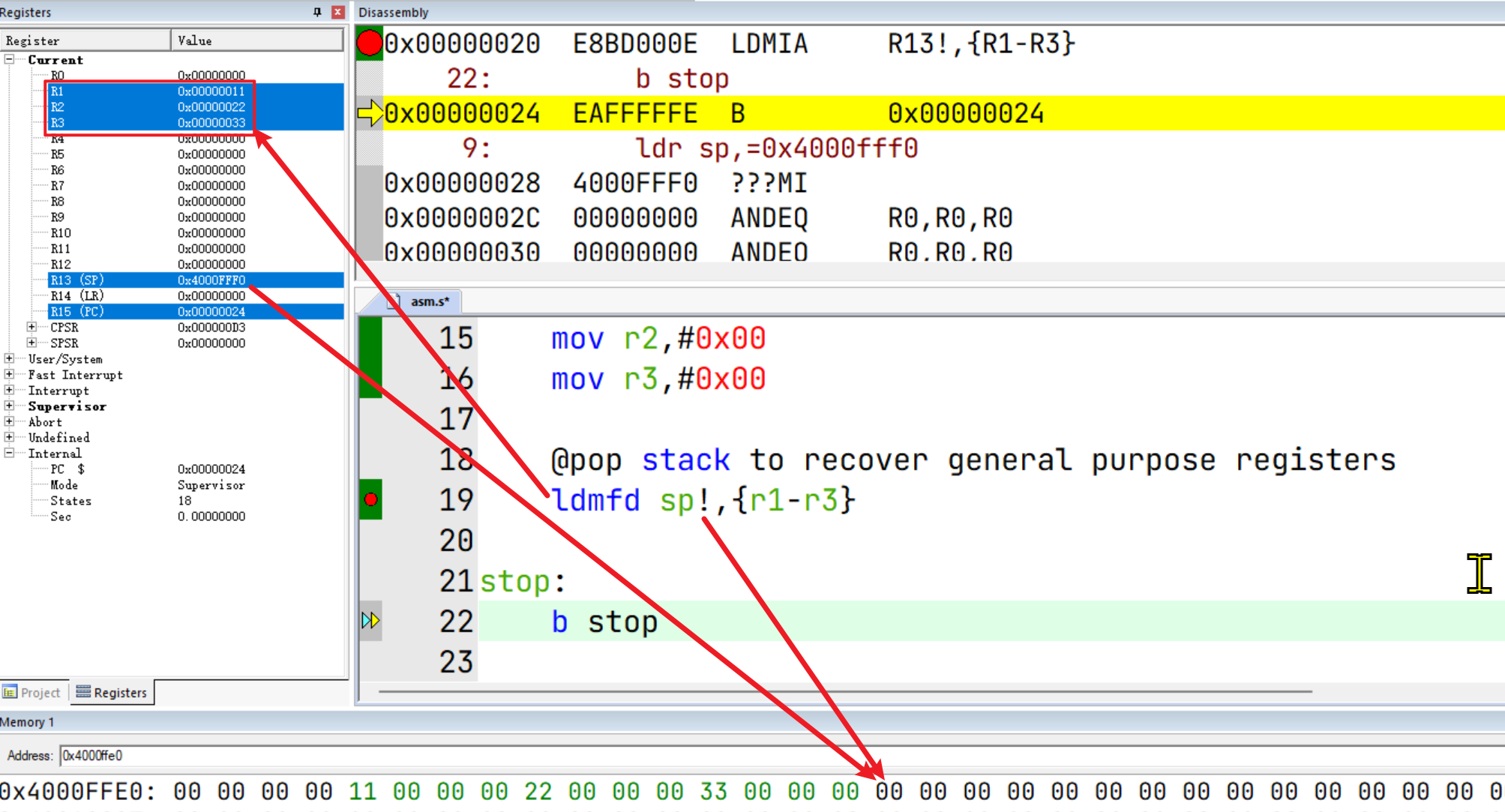
.global _start
_start:
mov r1,#0x11
mov r2,#0x22
mov r3,#0x33
@first: set stack pointer(start address of stack, from high address to low)
ldr sp,=0x4000fff0
@push to save general purpose registers and decrease stack pointer
stmfd sp!,{r1-r3}
@do something with general purpose registers
mov r1,#0x00
mov r2,#0x00
mov r3,#0x00
@pop stack to recover general purpose registers
ldmfd sp!,{r1-r3}
stop:
b stop
CPSR/SPSR操作指令
MRS(Move to Register from Special register)
Move to Register from Special register moves the value from the CPSR or SPSR of the current mode into an ARM
core register.
An MRS that accesses the SPSR is UNPREDICTABLE if executed in User or System mode.
An MRS that is executed in User mode and accesses the CPSR returns an UNKNOWN value for the
CPSR.{E, A, I, F, M} fields.
MRS{<c>}{<q>} <Rd>, <spec_reg>
MSR(Move register/immediate to Special Register)
Move to Special register from ARM core register moves the value of an ARM core register to the CPSR or the SPSR of the current mode.
MSR<c> <spec_reg>, #<const>
MSR{<c>}{<q>} <spec_reg>, <Rn>
🌟总结
MRS、MSR分辨:
- R在前面,则操作数1为通用寄存器(要将CPSR读到Rd);
- S在前面,操作数为特殊寄存器(要将通用寄存器写到CPSR)
练习

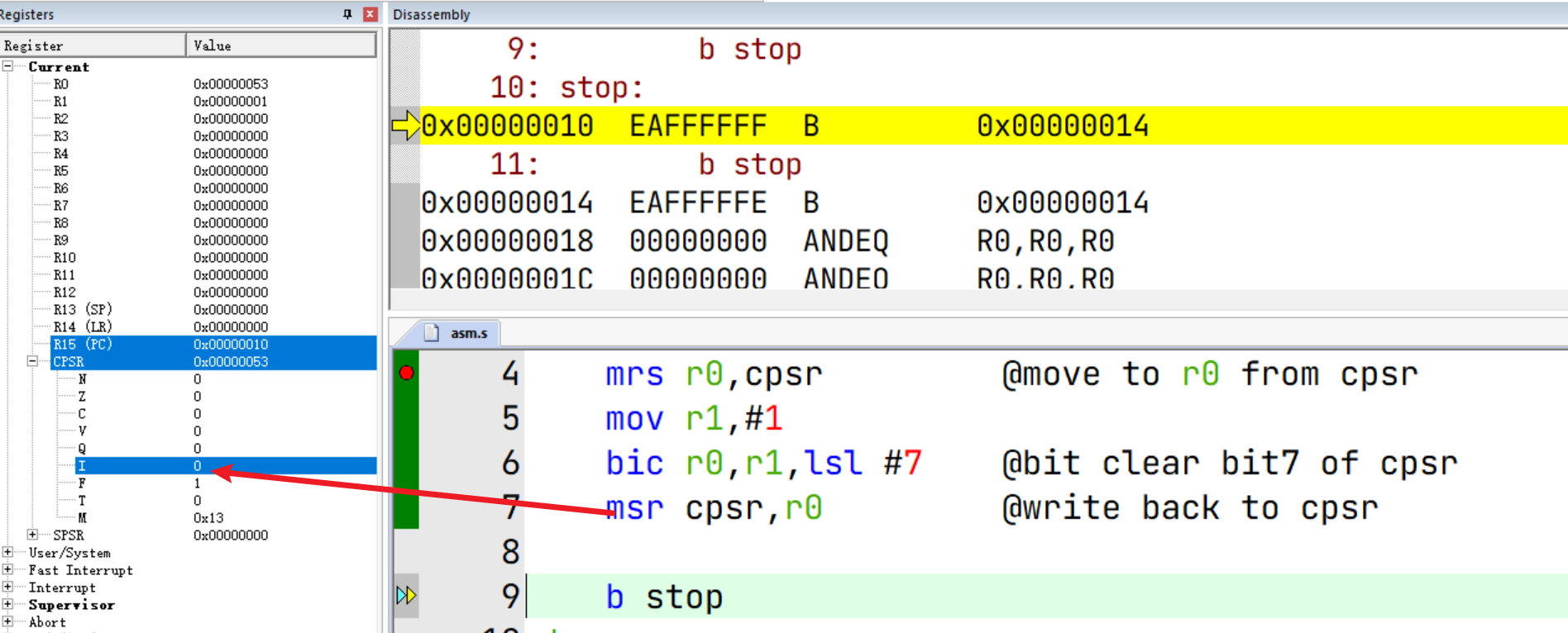
.global _start
_start:
mrs r0,cpsr @move to r0 from cpsr
mov r1,#1
bic r0,r1,lsl #7 @bit clear bit7 of cpsr
msr cpsr,r0 @write back to cpsr
b stop
stop:
b stop
.global _start
_start:
mrs r0,cpsr @move to r0 from cpsr
mov r1,#1
bic r0,r1,lsl #7 @bit clear bit7 of cpsr
msr cpsr,r0 @write back to cpsr
mrs r0,cpsr
orr r0,r1, lsl #7 @set bit7 of cpsr
msr cpsr,r0 @write back to cpsr
b stop
stop:
b stop



