参考资料
The ARM-THUMB Procedure Call Standard
ATPCS标准
ATPCS标准介绍
ATPCS是ARM-Thumb Procedure Call Standard的缩写,也就是ARM-Thumb的程序调用标准。
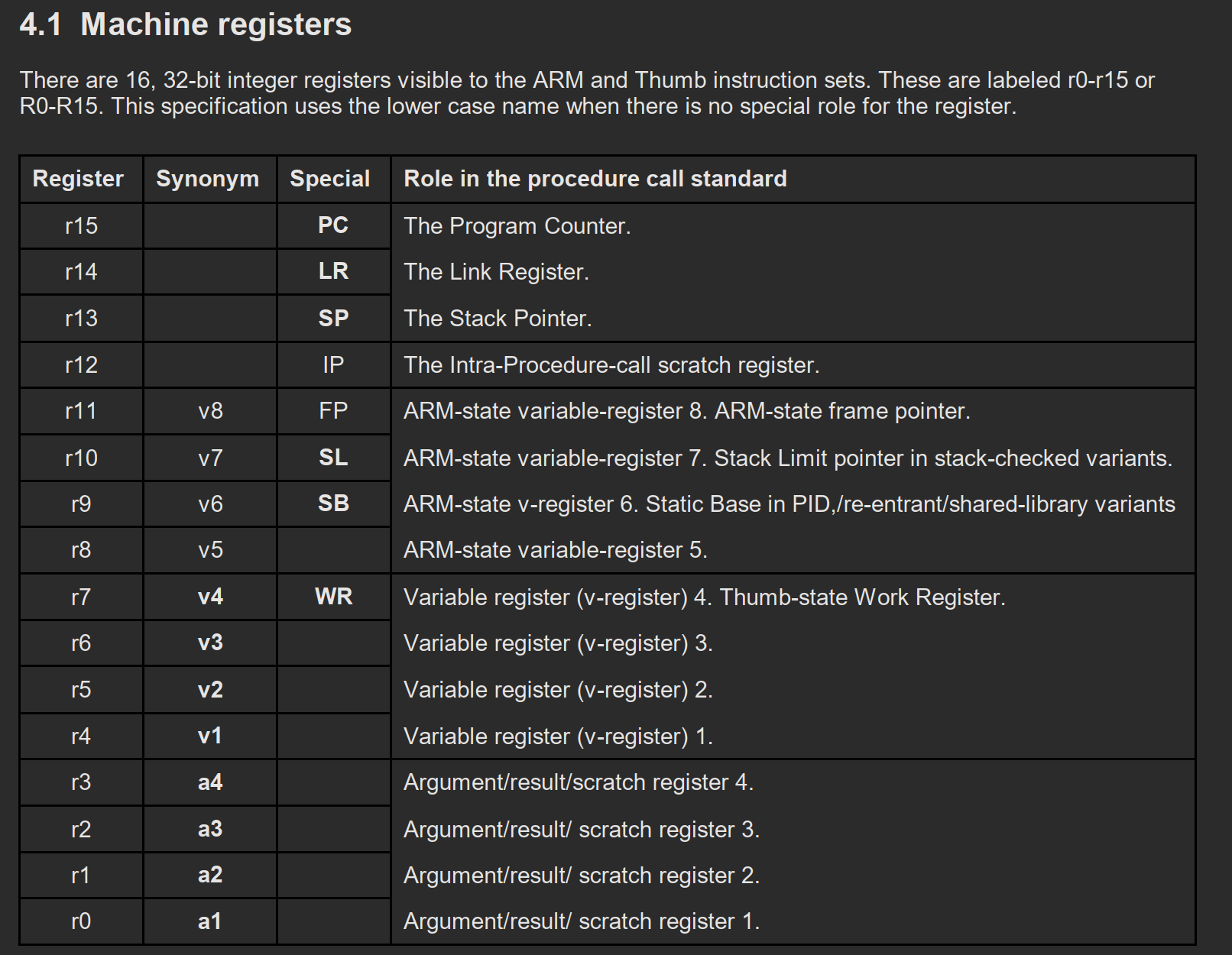
寄存器角色
The first four registers r0-r3 are used to pass parameter values into a routine and result values out of a routine and to hold intermediate values within a routine (but, in general, only between subroutine calls). In ARM-state, register r12— also called IP— can also be used to hold intermediate values between subroutine calls.
r0-r3通常用来传递函数参数、返回函数结果和保存函数执行过程中产生的中间变量(例如 sum=a+b需要先将 a+b的计算结果存到寄存器中再写到 sum对应的内存)。
在ARM状态下,r12,也称为IP寄存器也可以用来保存临时变量,尤其是当其他通用寄存器(r0-r11)已被使用时。
r12(IP) is a general-purpose register, not reserved for any specific use in standard ARM programming.The ARM Procedure Call Standard (AAPCS) defines it as a scratch register. This means:
- The caller can use it freely to store temporary values.
- The callee (the function being called) does not preserve its value. If
r12is used by the caller before calling another function, its value will be lost unless explicitly saved.
Typically, the registers from r4 to r11 are used to hold the values of a routine’s local variables. They are also labeled v1-v8. Only v1-v4 can be used uniformly by the whole Thumb instruction set (shown emboldened).
一般地,r4-r11用来保存函数的局部变量,他们被标记为v1-v8。Thumb指令集只能使用v1-v4。
In all variants of the procedure call standard, registers r12-r15 have special roles. In these roles they are labeled IP, SP, LR and PC (or ip, sp, lr, and pc, but this standard uses the upper case name for the special role)
r12-r15有着特殊的角色,例如IP(临时保存SP),SP(指向栈顶),LR(跳转时用来保存PC)、PC,并且使用大写来标示他们的特殊角色。
In some variants of the procedure call standard, r9 and r10 also have a special role. In these roles, r9 is labeled SB and r10 is labeled SL (or sb and sl).
Only registers r0-r7, SP, LR and PC are ubiquitously available in Thumb state. Their synonyms and special names are shown emboldened. Few Thumb instructions can access the high registers, v5-v8, SB, SL and IP.
In Thumb-state, r7 is often used as a work register and is also labeled WR
参数传递
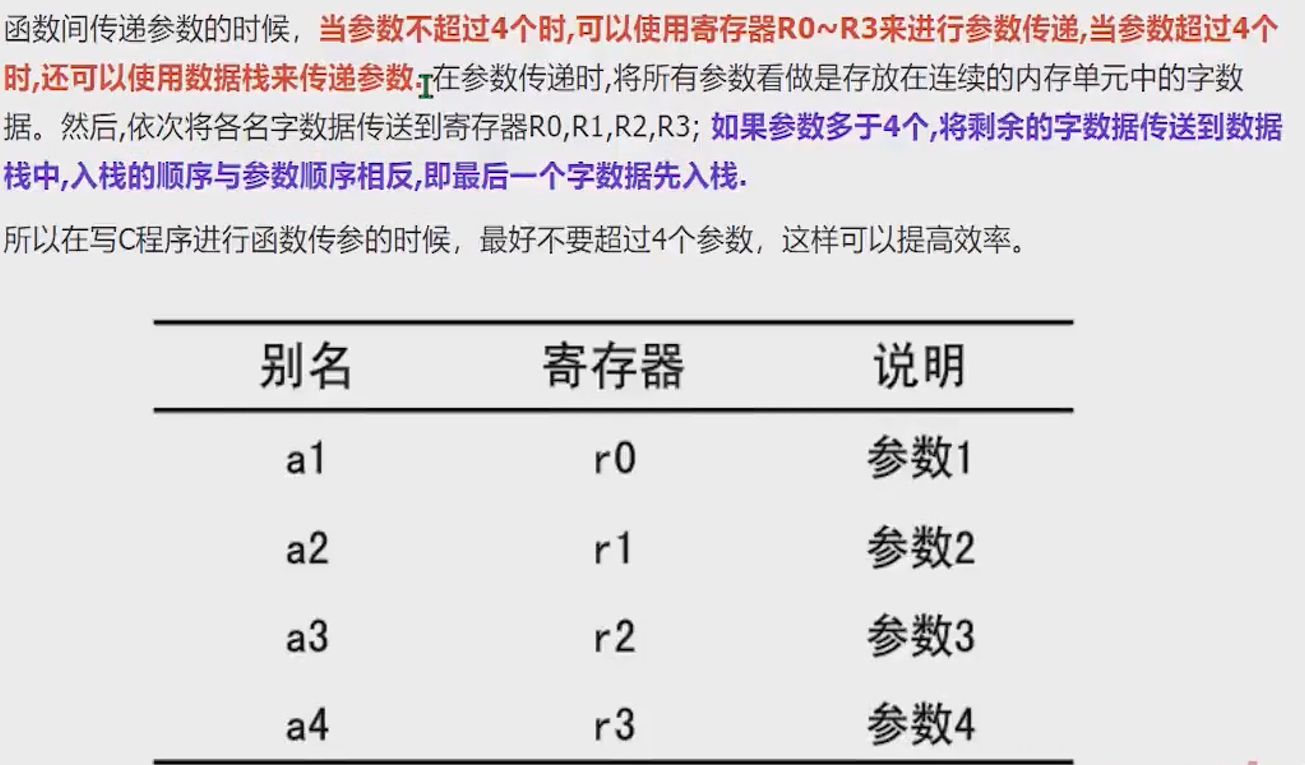
在定义函数时,参数数量尽量不要超过4个,这样效率较好
函数返回值
- 返回值为一个32位的整数时,可以通过寄存器0返回
- 返回值为一个64位整数时,可以通过R0和R1返回,依此类推
栈帧分析
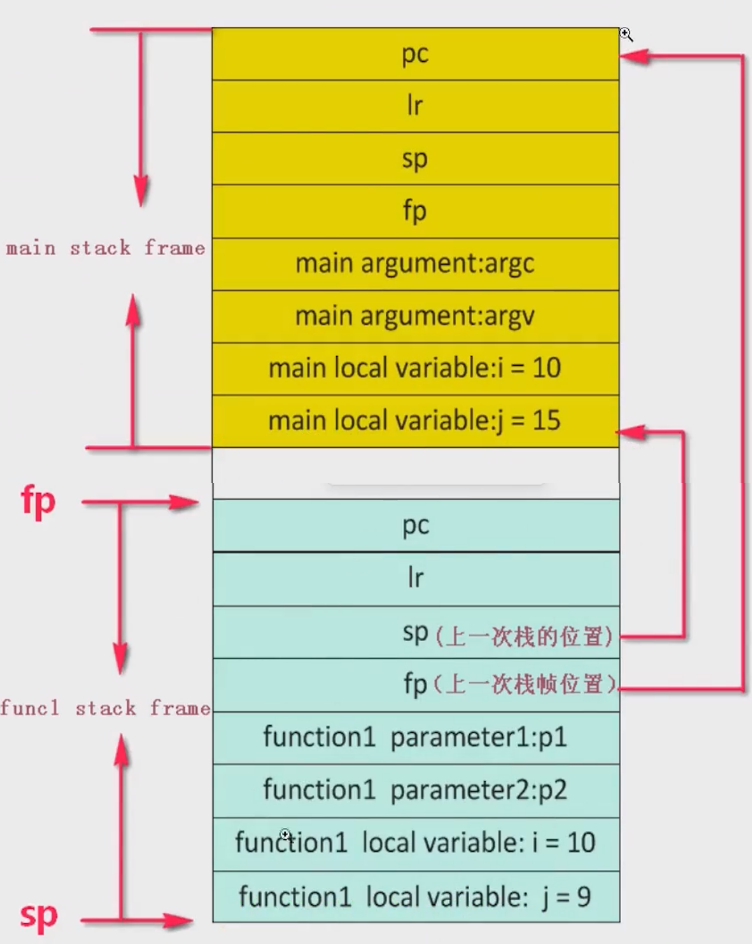

反汇编分析ATPCS标准
准备汇编和C文件
准备一个汇编启动文件和一个C文件:
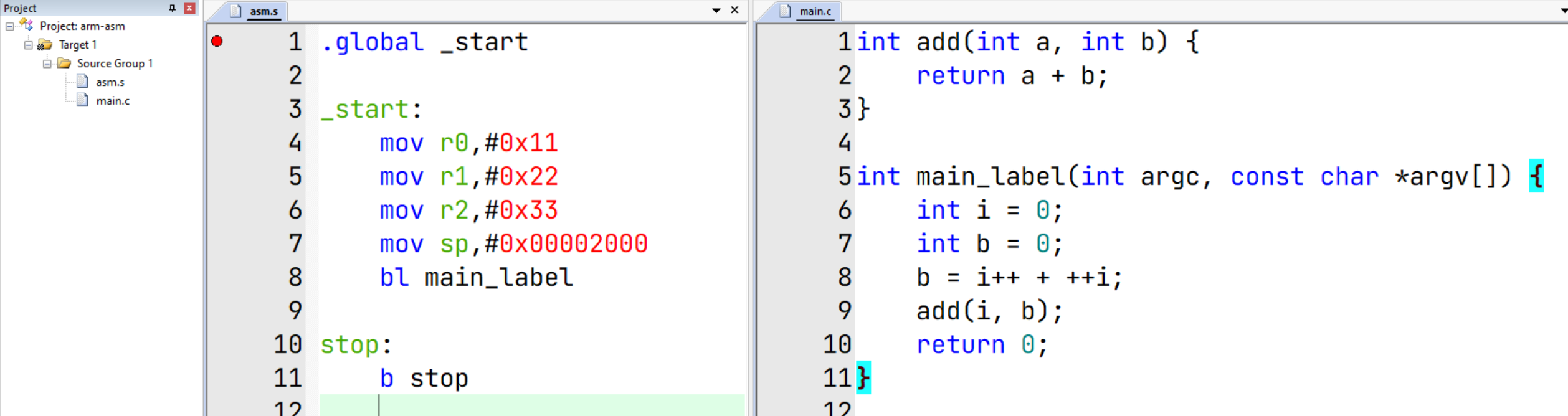
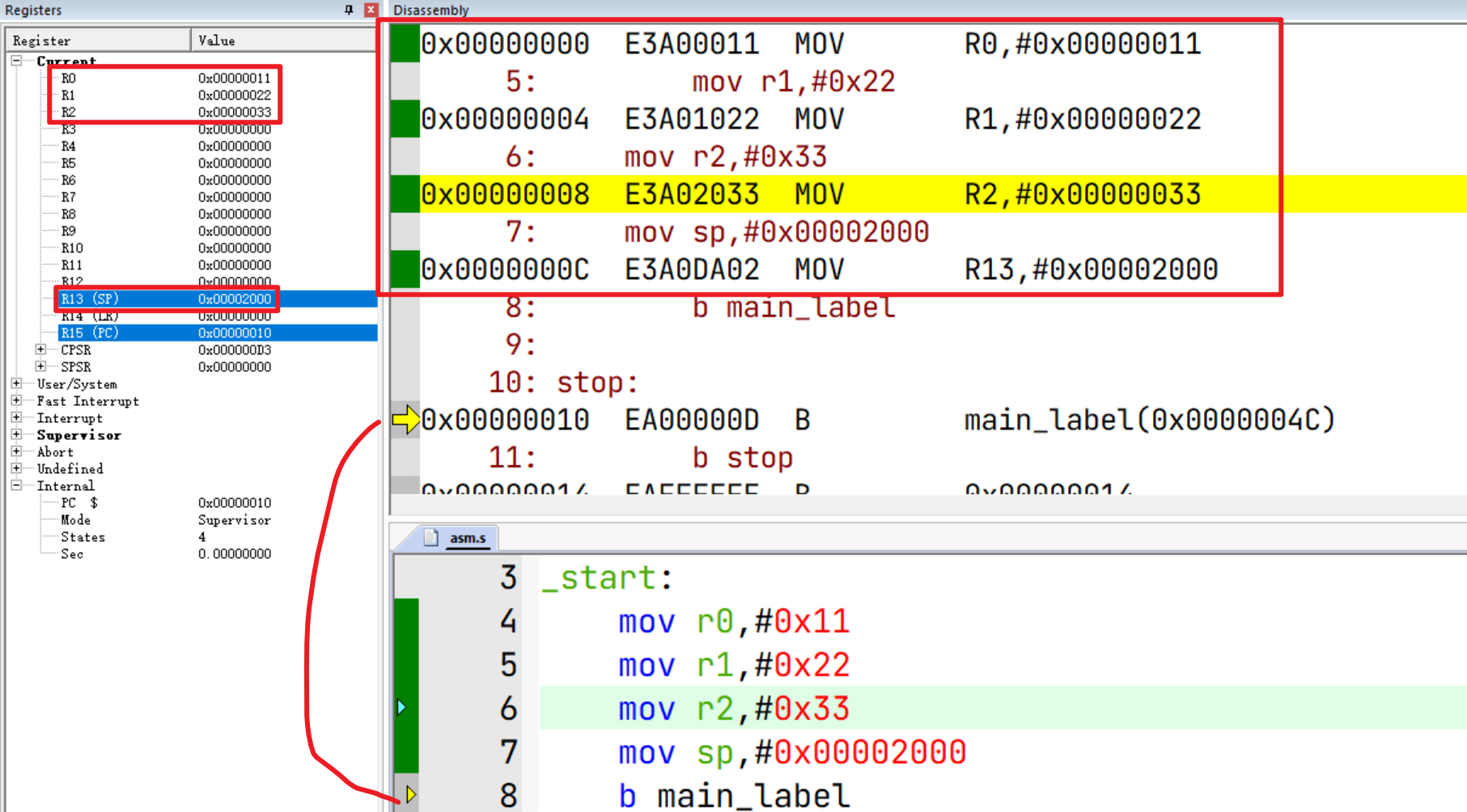
在 asm.s中,在调用 main_label函数之前,我们操作了下R0-R2,并设置了SP,模拟在调用函数前做了一些操作
.global _start
_start:
mov r0,#0x11
mov r1,#0x22
mov r2,#0x33
mov sp,#0x00002000
bl main_label
stop:
b stop
int add(int a, int b) {
return a + b;
}
int main_label(int argc, const char *argv[]) {
int i = 0;
int b = 0;
b = i++ + ++i;
add(i, b);
return 0;
}禁用编译优化
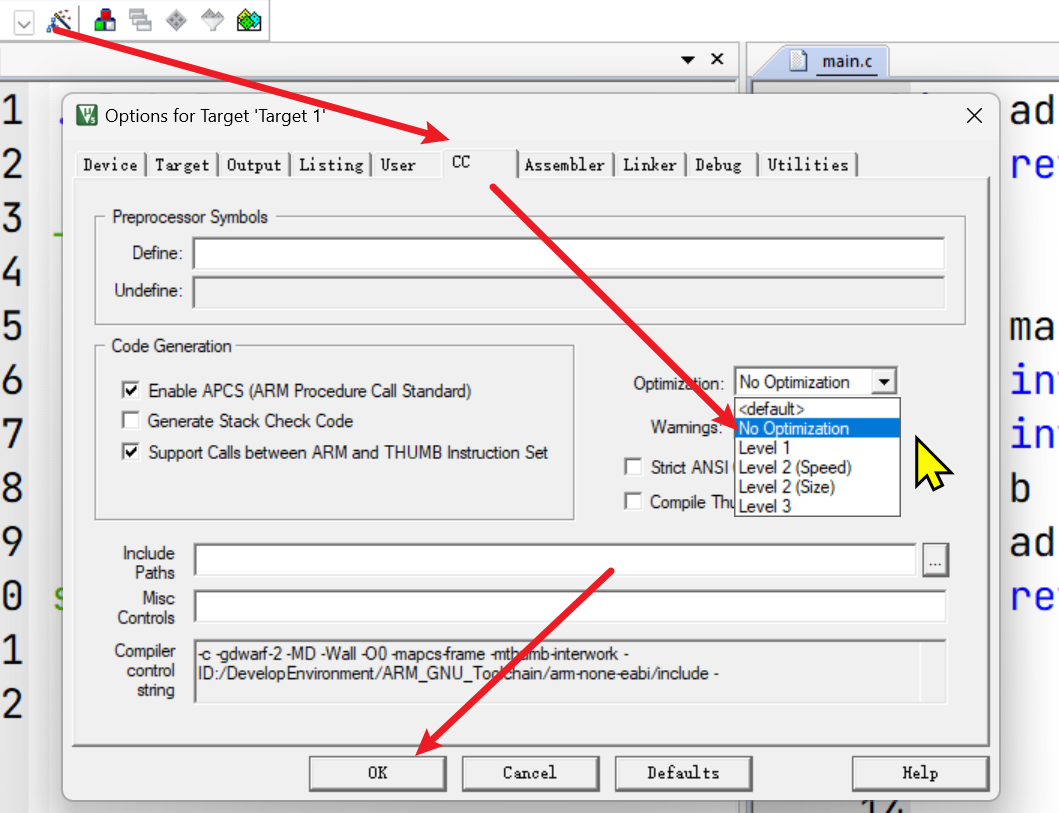
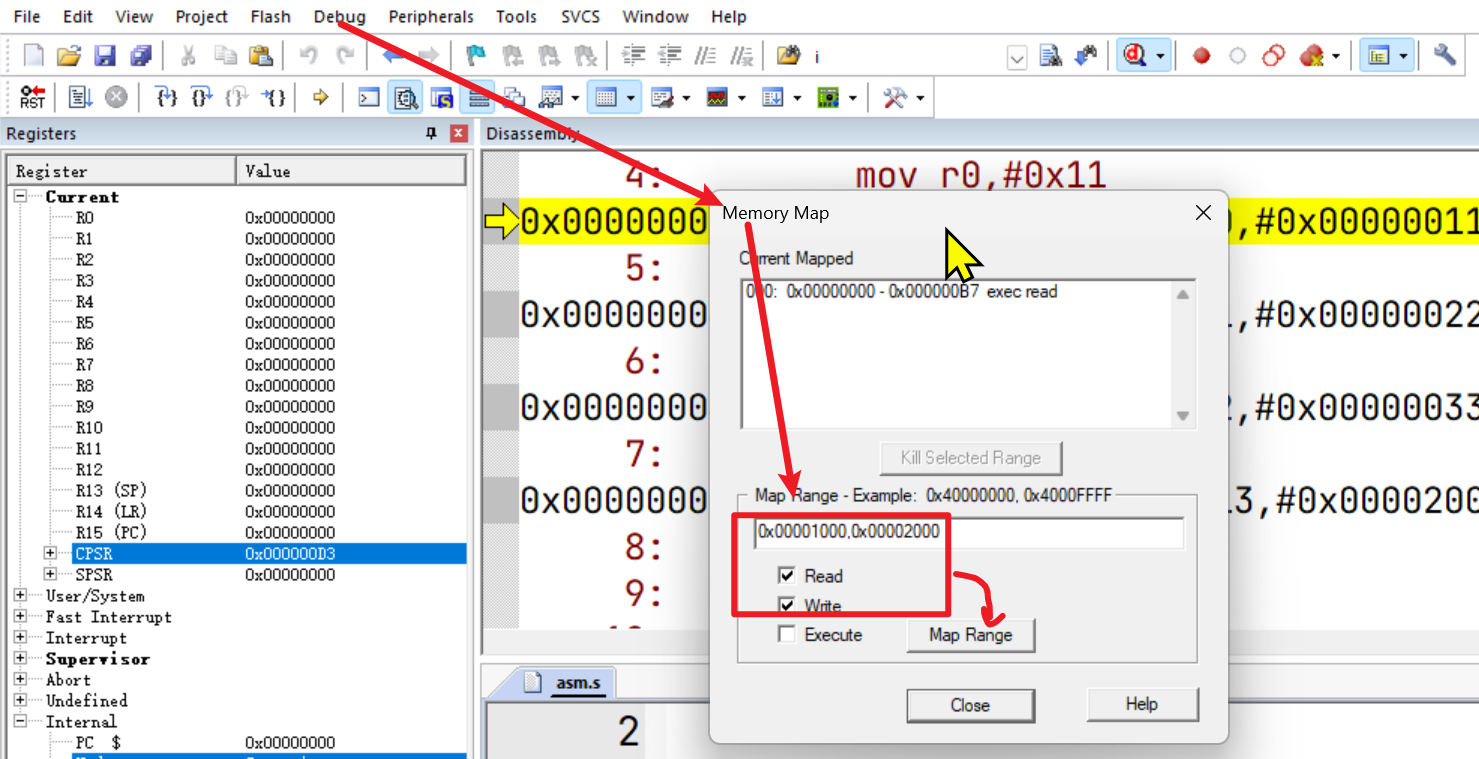
调试分析&内存映射
在点击debug后,步进之前,我们先添加一下内存映射 0x00001000,0x00002000,因为在 asm.s中我们有设置过SP mov sp,#0x00002000(注意每次点击debug后都需要手动映射下)
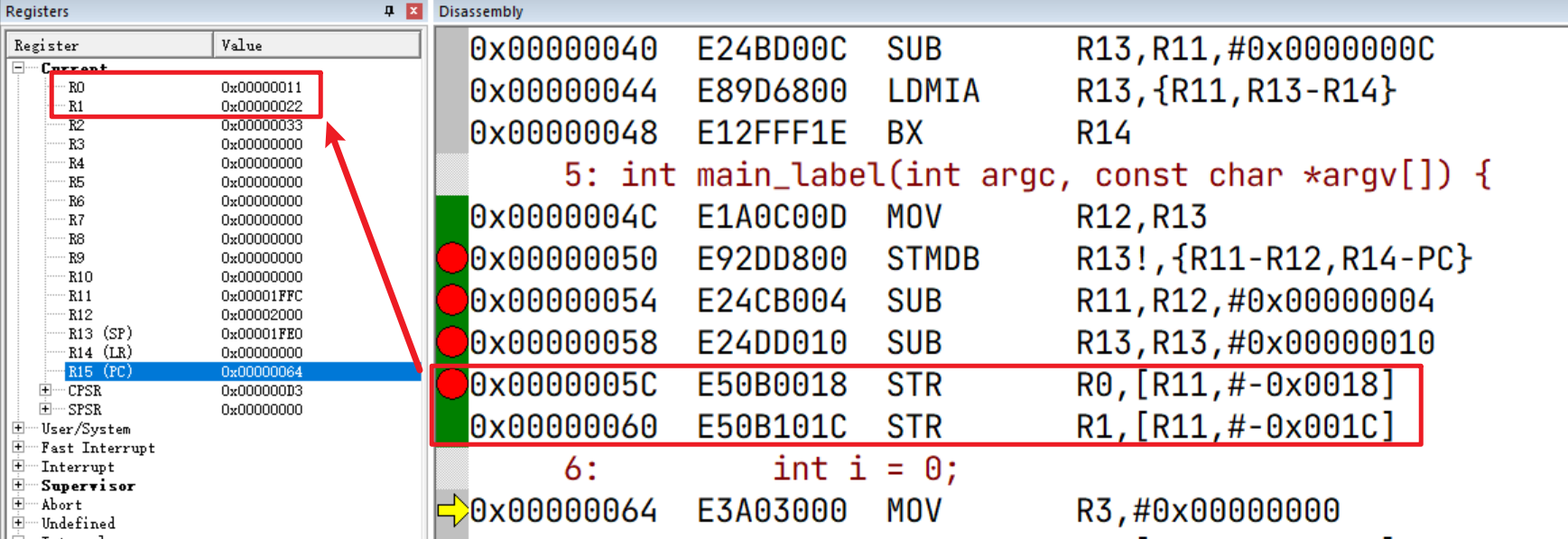
接着我们步进,在调用 main_label函数之前,对R0-R2,SP(R13)有所使用(模拟函数调用前操作过相关的寄存器):
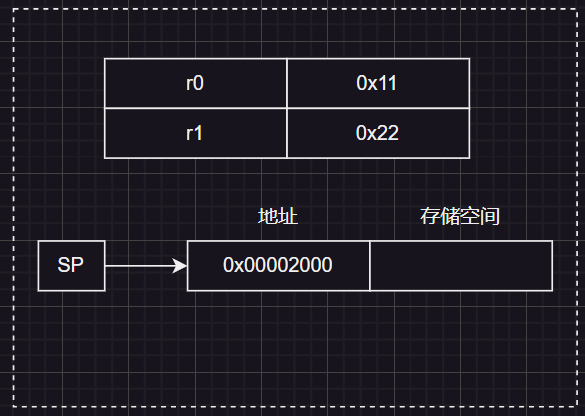
寄存器状态示例:
函数调用分析
参照ATPCS标准,我们接着分析 main_label函数的执行。
将SP暂存到IP
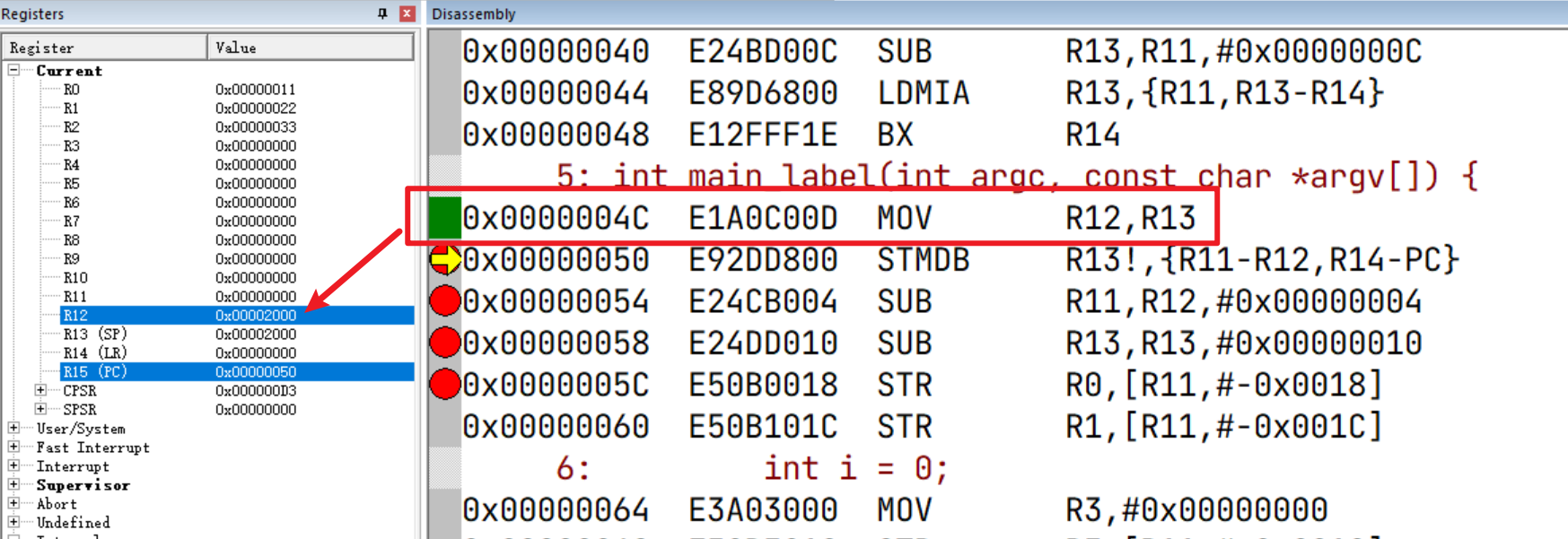
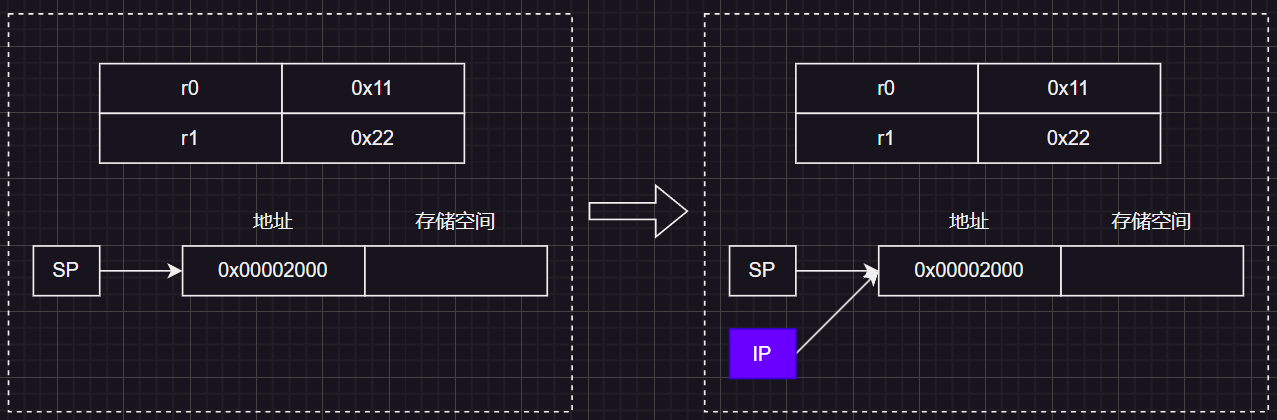
首先将R13(SP)送到了R12(IP)进行保存(这里可以看出IP的临时保存作用,将函数调用前的SP栈顶指针暂存起来以便后续恢复):
接着我们看下一条指令的执行:
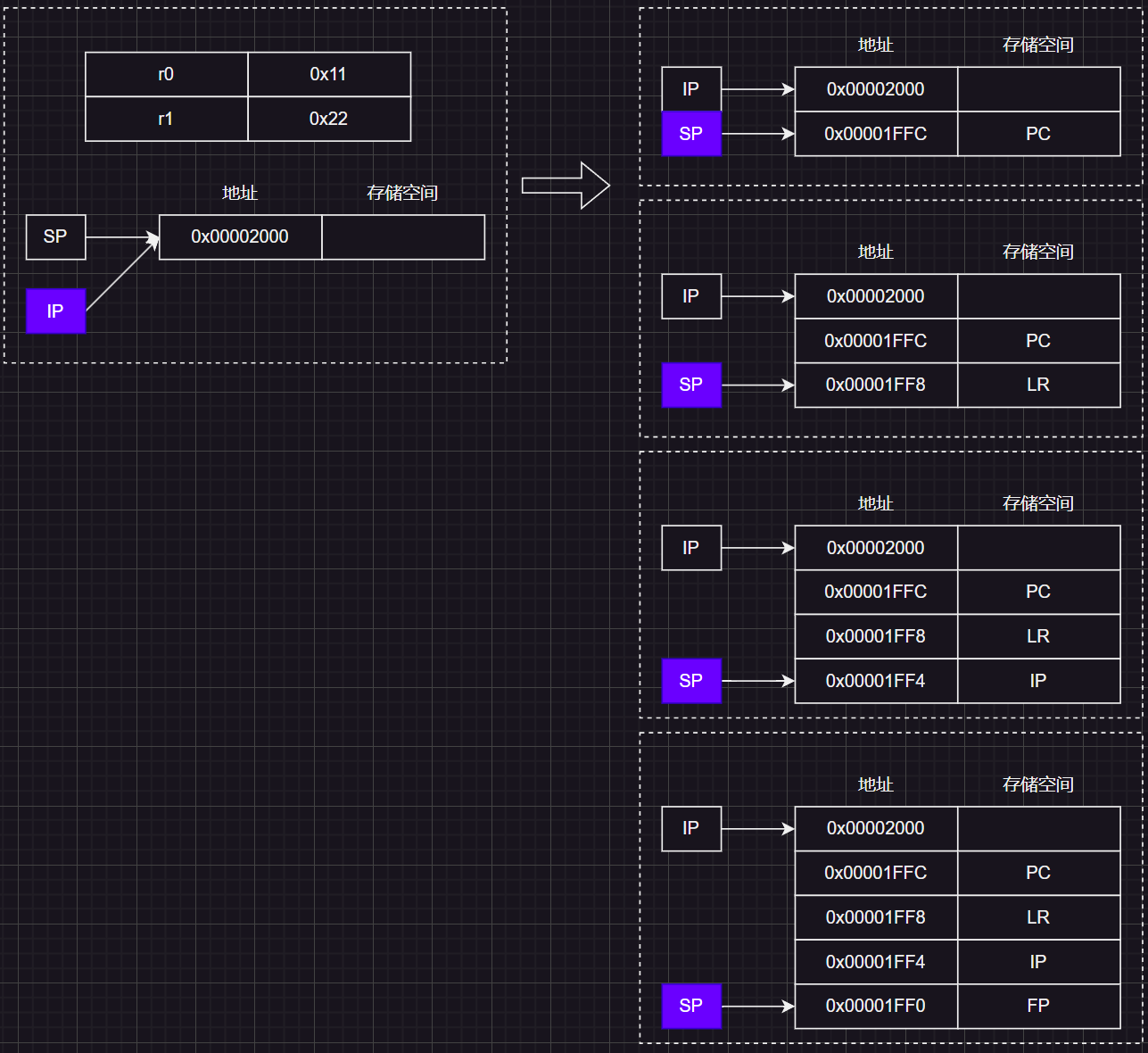
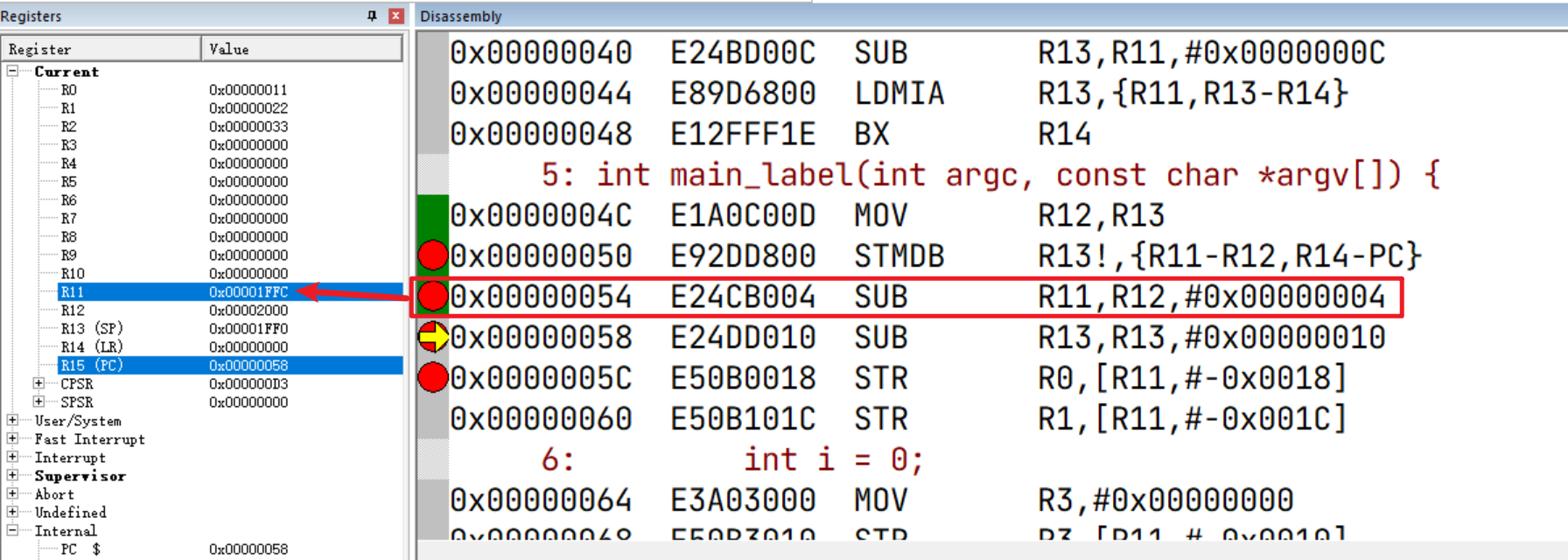
压栈PC,LR,IP,FP
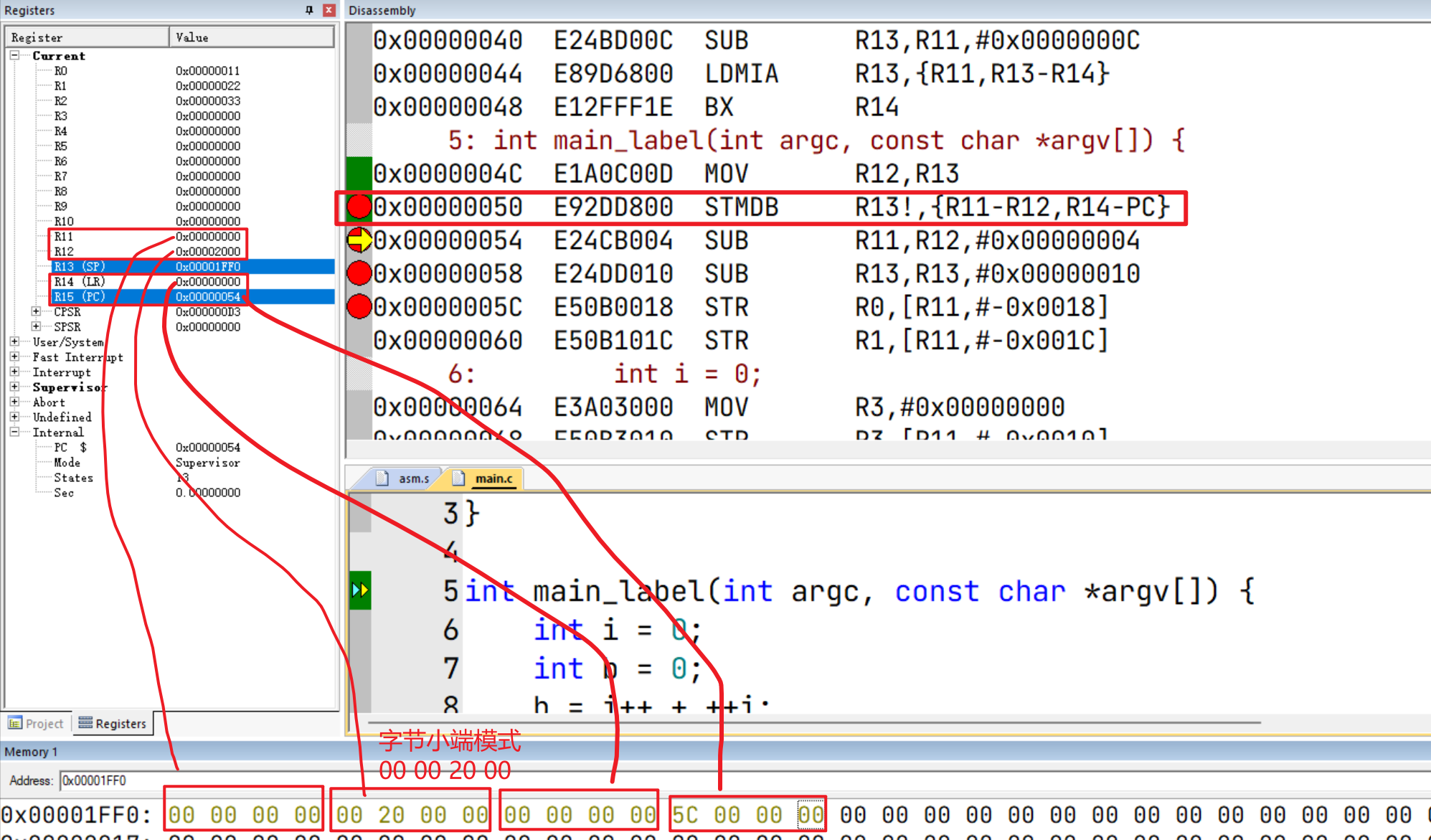
将R11(FP)、R12(IP)、R14(LR)、PC(R15)通过 STMDB指令进行压栈(参考另一篇文章《ARM核学习(二)指令集》),值得注意的是:
- ATPCS标准规定使用满减栈模式(从高地址向低地址增长,栈顶指针SP指向最后一个入栈的数据地址)
STM:多数据传输指令,同时将多个数据进行压栈DB: Decrease Before(先递减SP然后压栈数据),这里压栈4个寄存器(字宽4字节),所以SP会递减4*4=16- 同时压栈多个寄存器时,序号(Rn中的n)大的寄存器对应栈的高地址,序号小的则对应低地址
寄存器状态示意图:
设置栈基址FP(栈底数据的地址)
将R12(IP,之前保存了SP,即调用方caller的SP),通过 SUB指令减4,赋值给R11(FP,栈基值,被调方callee即 main_label函数的栈的起始地址)

寄存器示意图:
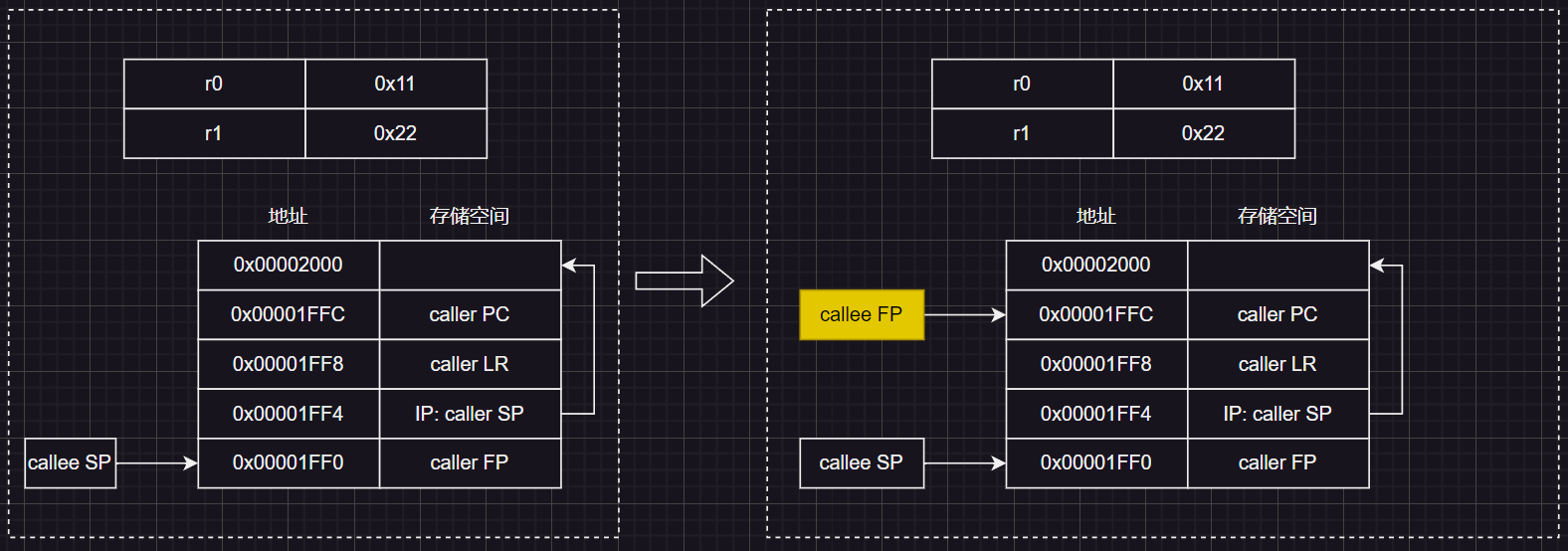
caller表示调用方,callee表示被调方
增加SP,扩大栈空间
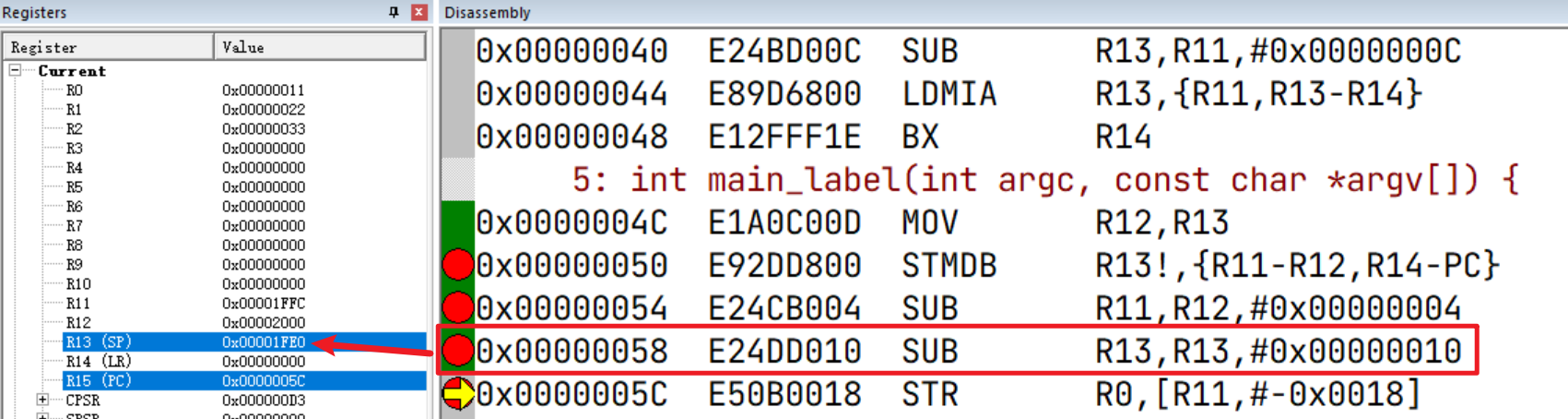
接着通过 SUB指令,将SP(R13)减去 0x00000010(即16字节,4个字),相当于将SP下移了四个存储单元
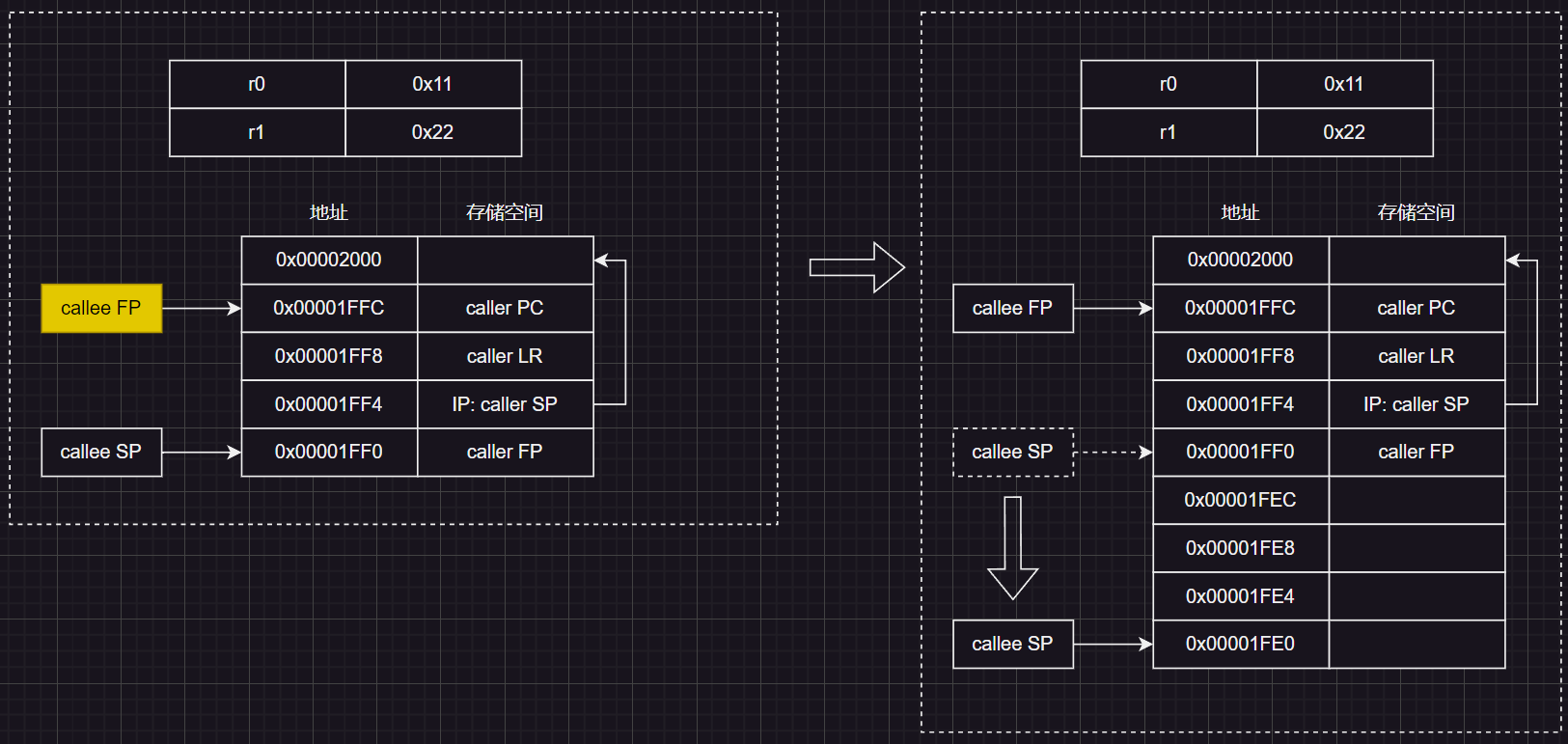
这样就相当于在栈中空出四个存储单元,为什么要这样做呢,我们接着往下看
函数入参压栈
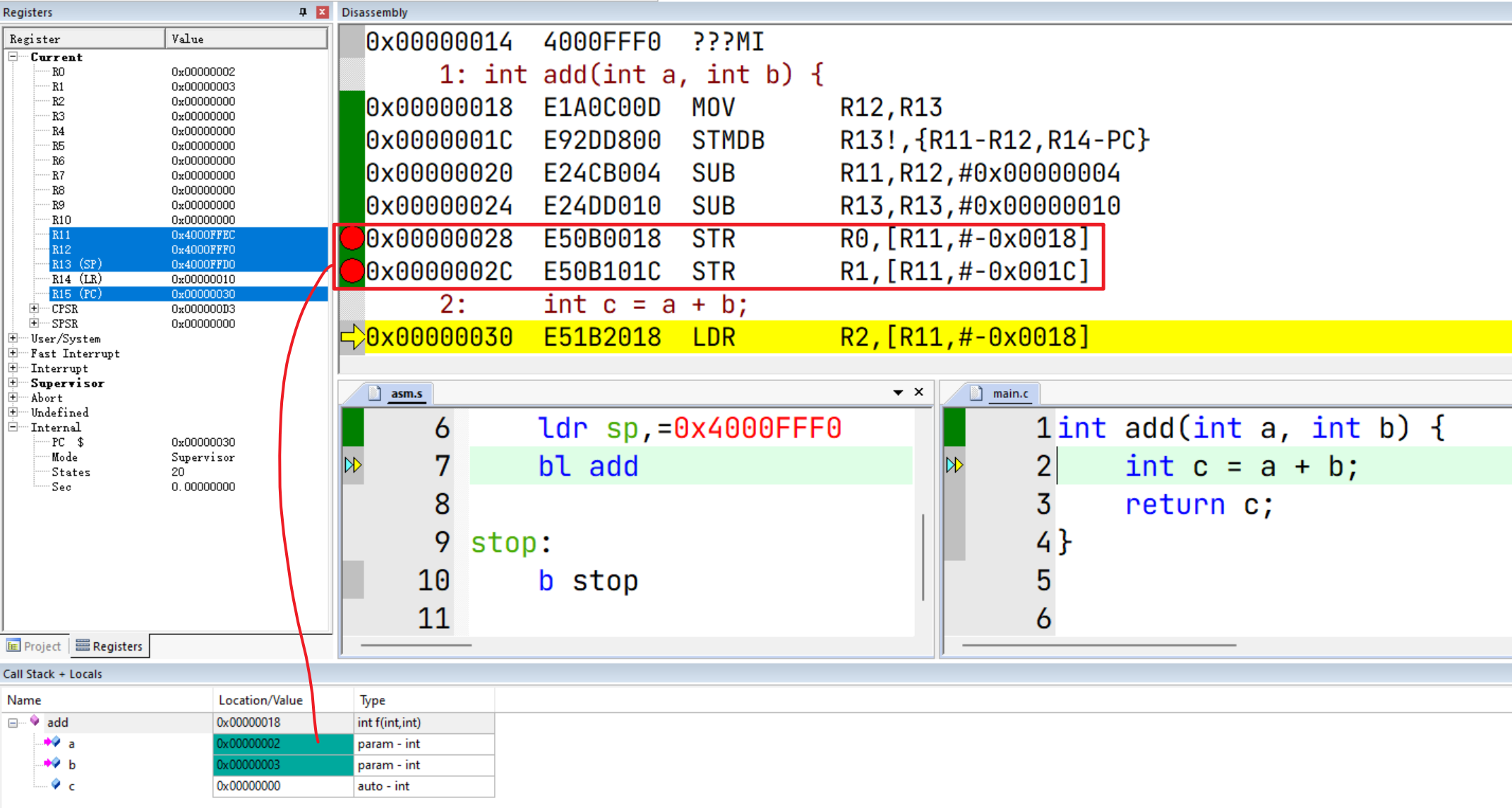
这里将R0写到R11(FP,栈基址)向下偏移 0x0018(即24字节,六个字)对应的存储单元中:
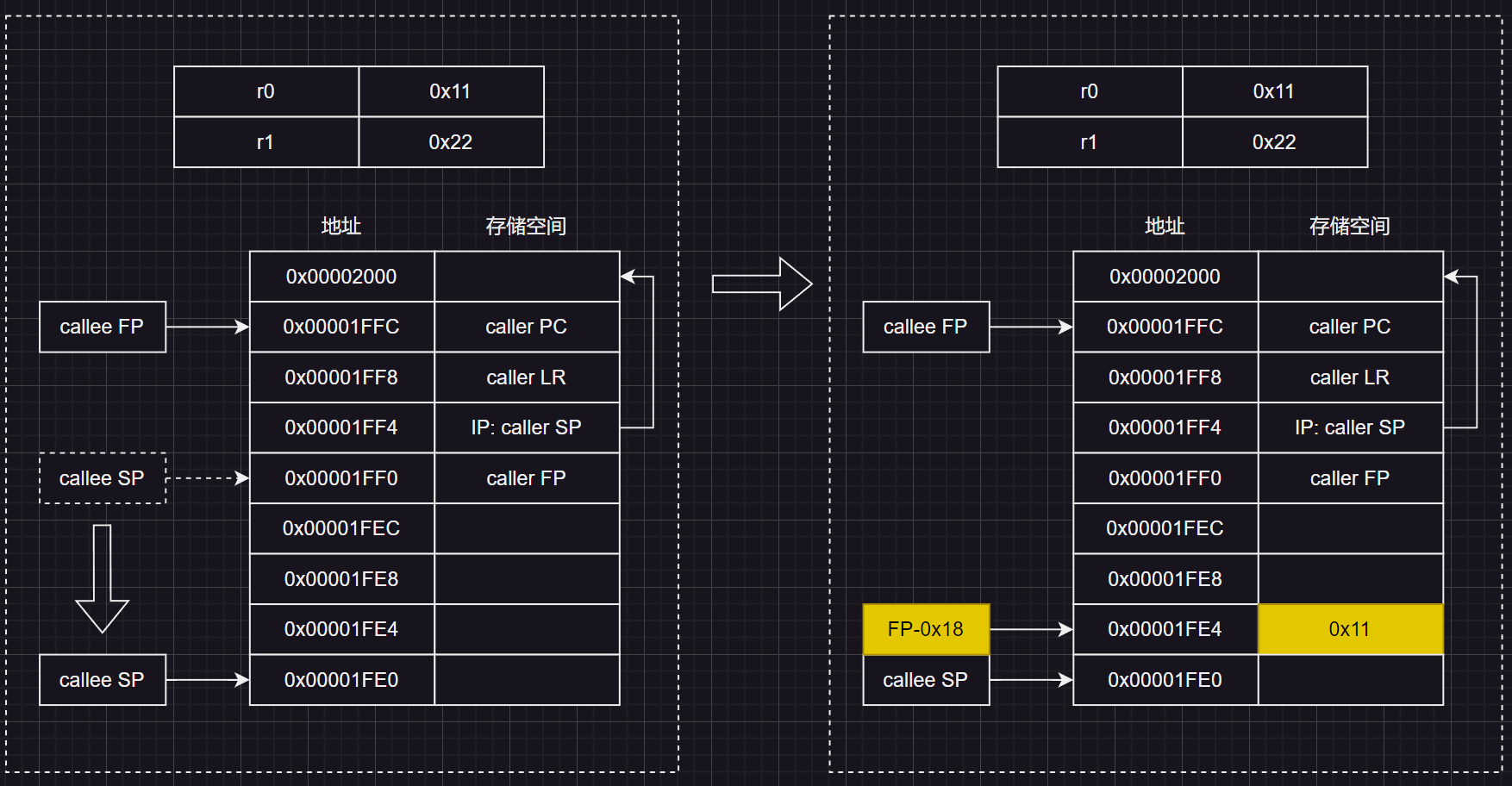
同样的,将R1写到FP向下偏移 0x001C(28个字节,7个字)的存储单元中:
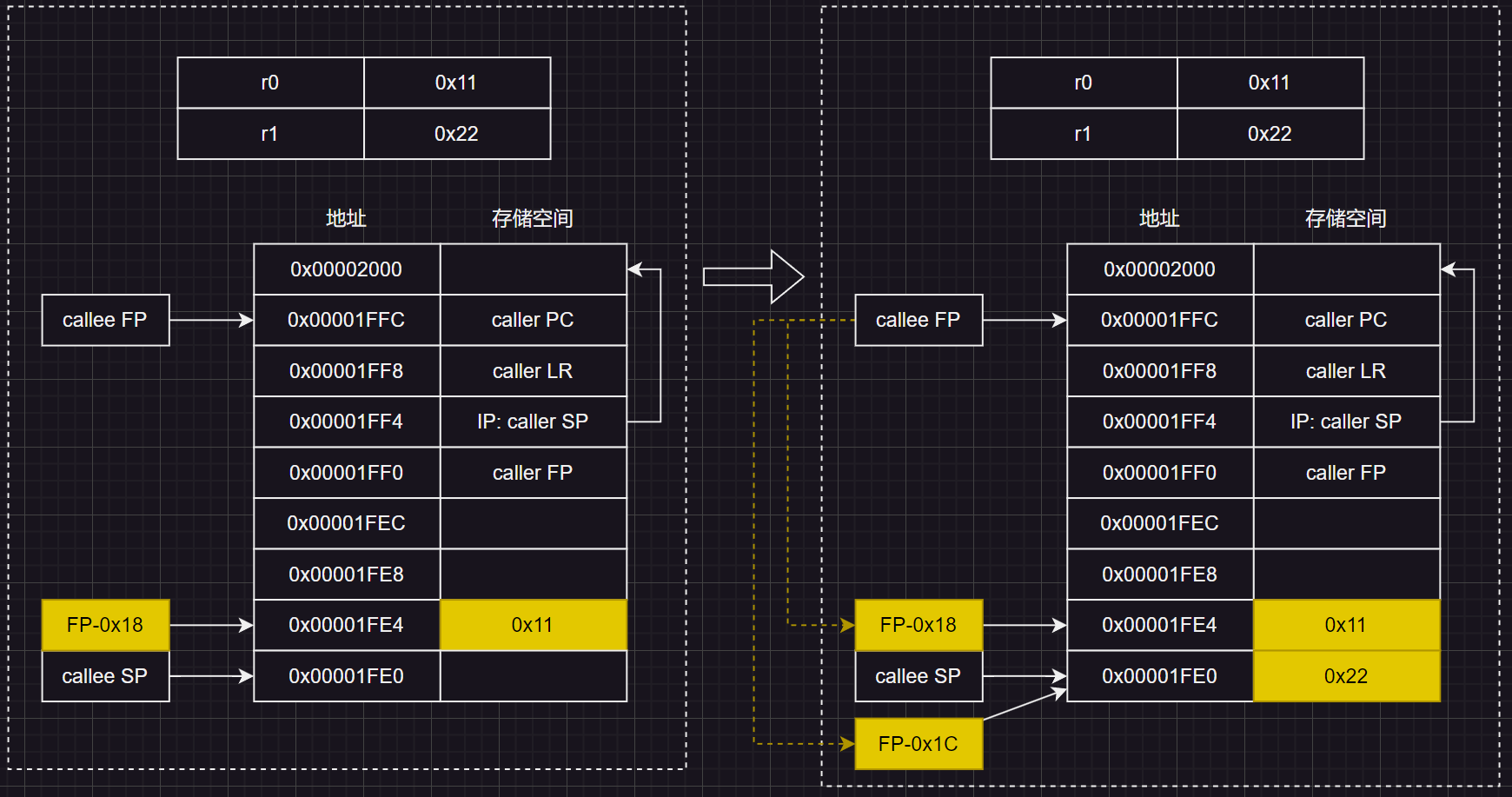
根据ATPCS标准的规范,r0通常用来传递第一个参数a1,r1通常用来传递第二个参数a2,因此上述操作起始就是将函数的两个入参 main_label(int argc, const char *argv[]) 压栈
函数局部变量压栈
对应 int i = 0
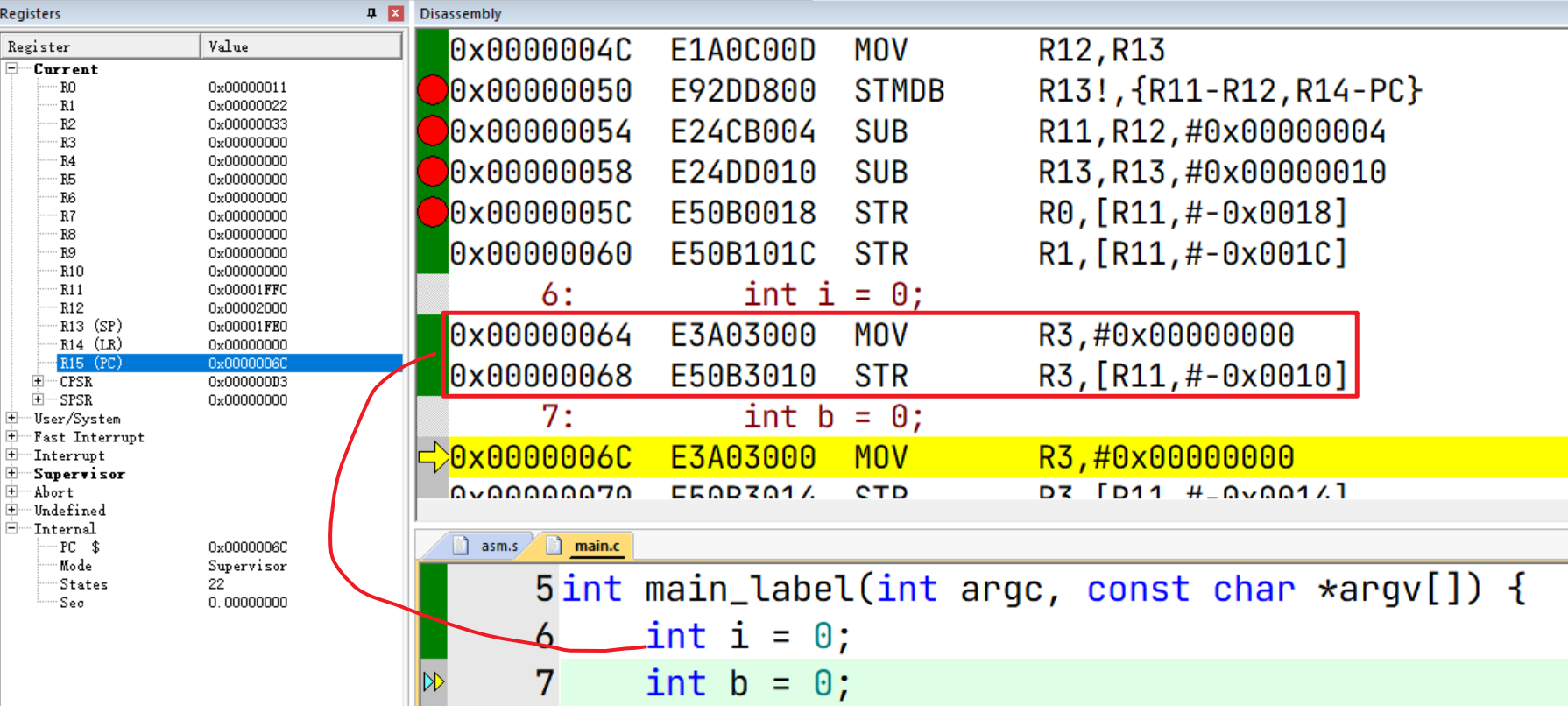
先将常量 0传输到寄存器R3中(这里R3作为通用寄存器存放临时的常量),再通过 STR指令压栈:
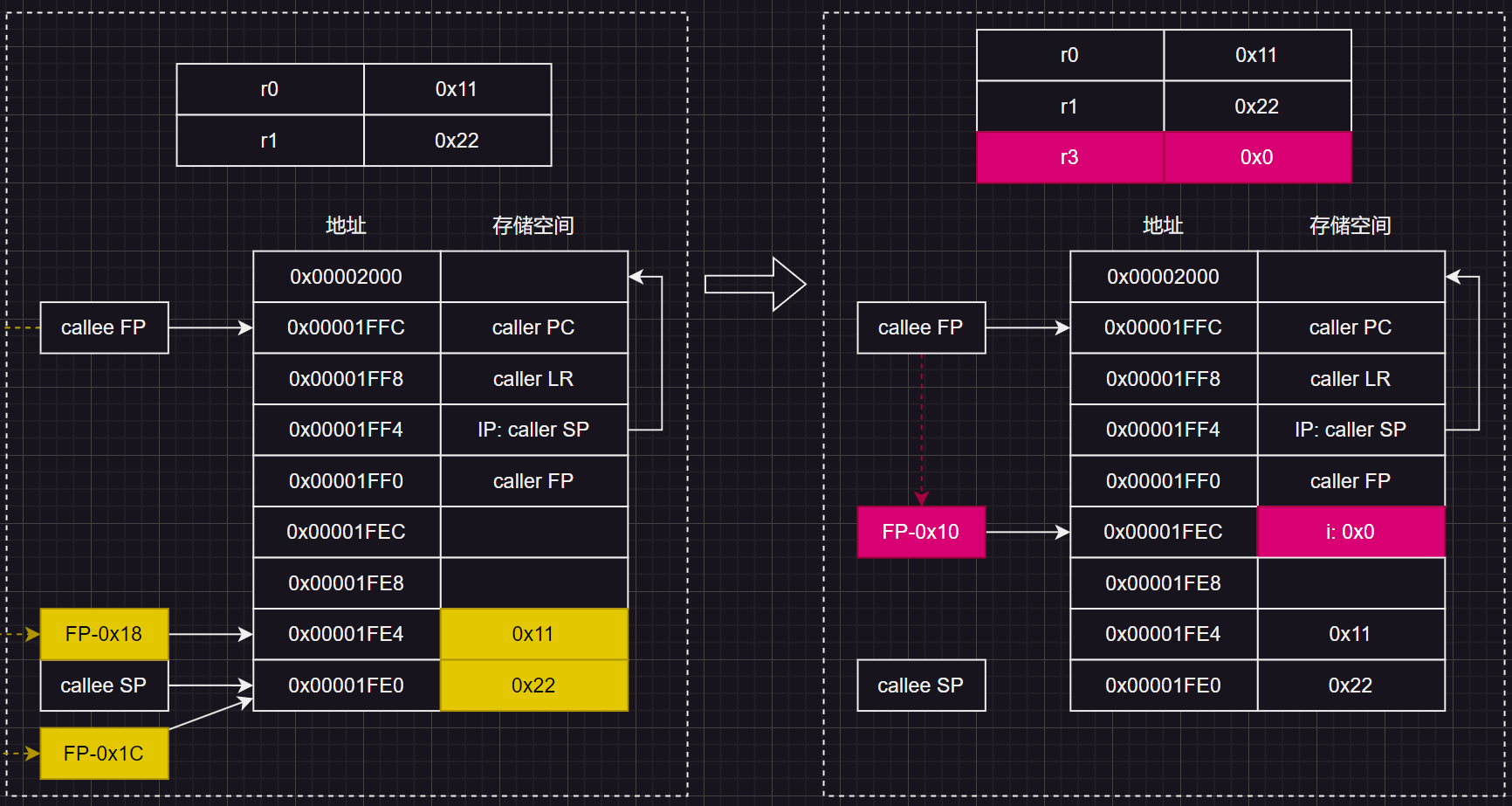
同样的,将局部变量 b压栈:
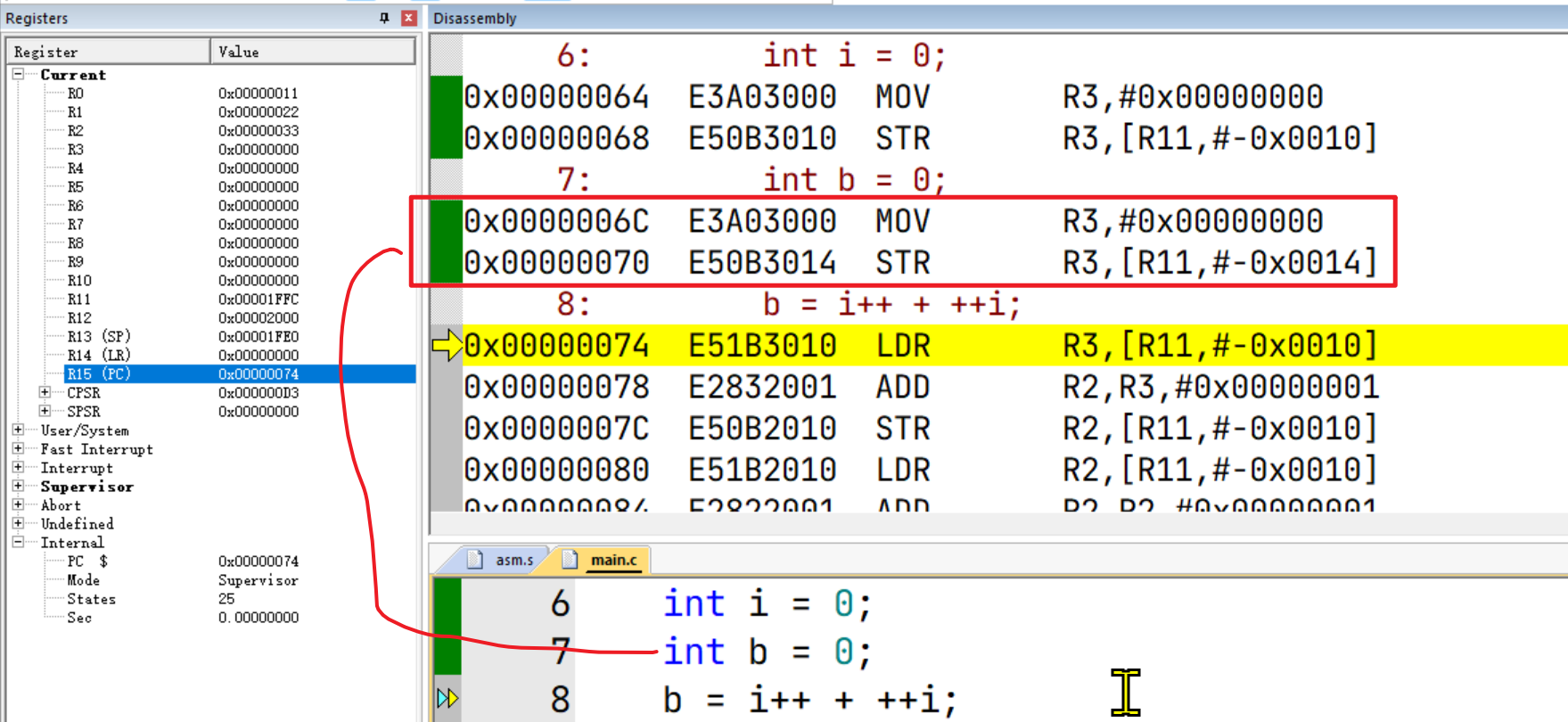
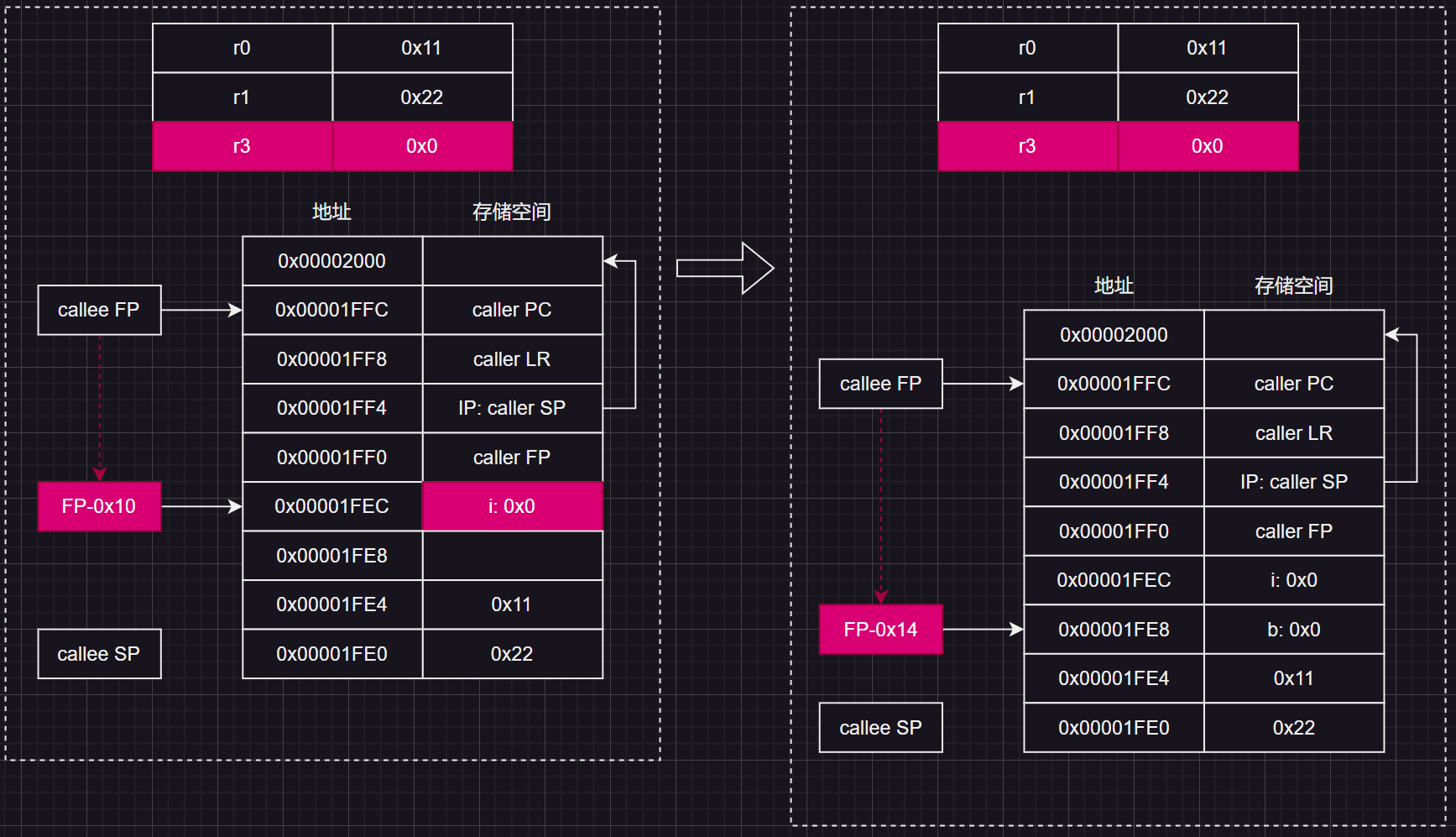
基于栈和寄存器做运算
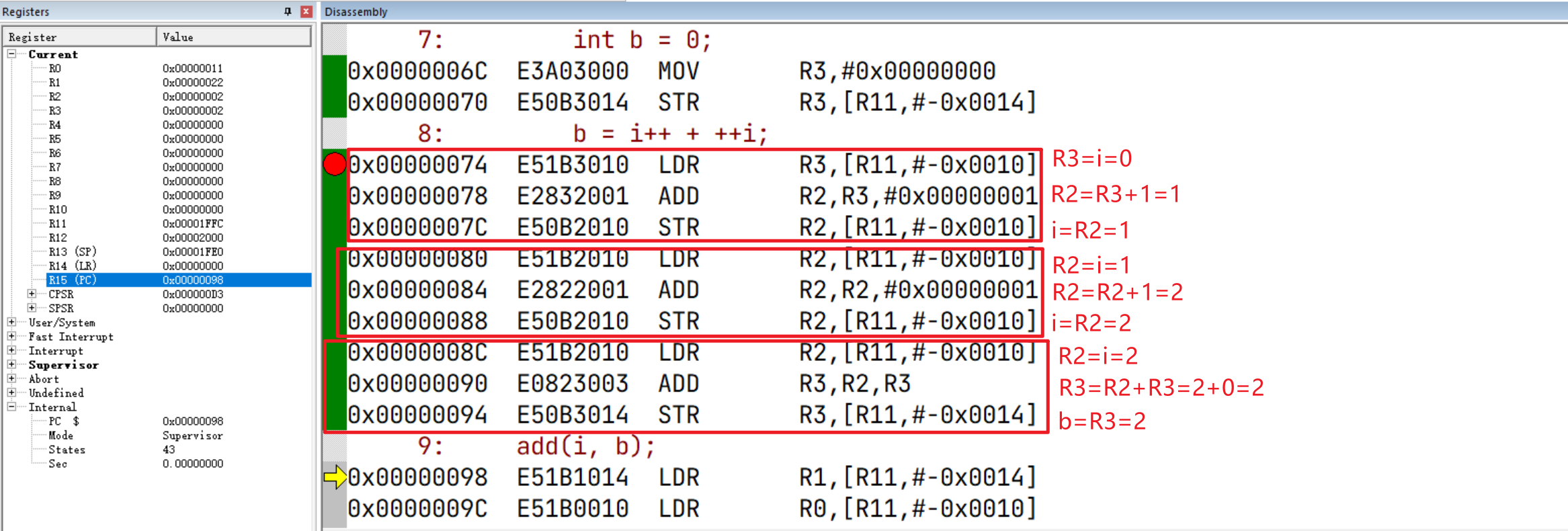
接着就到了 b = i++ + ++i;这一行代码的执行,它的过程是这样的:
++i;
b = i + i;
i++;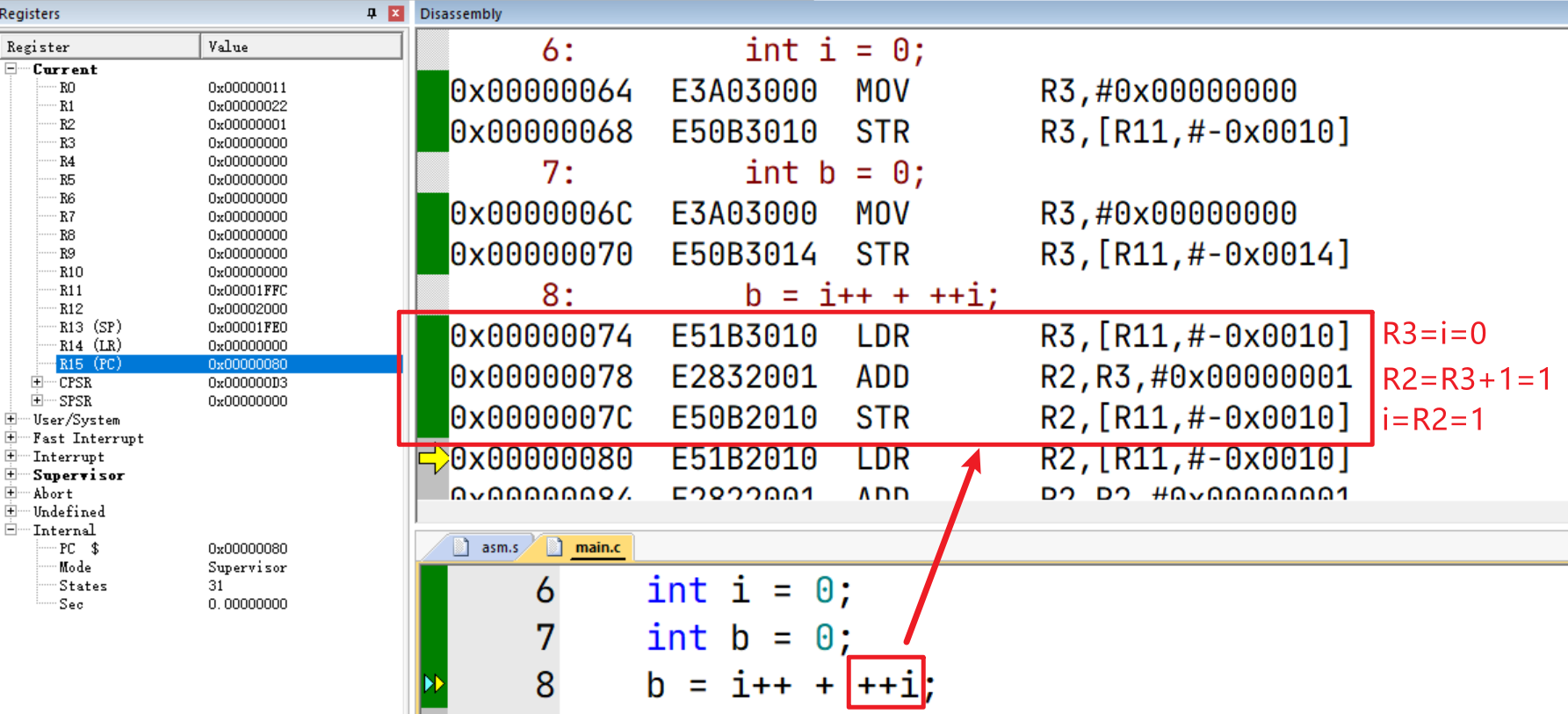
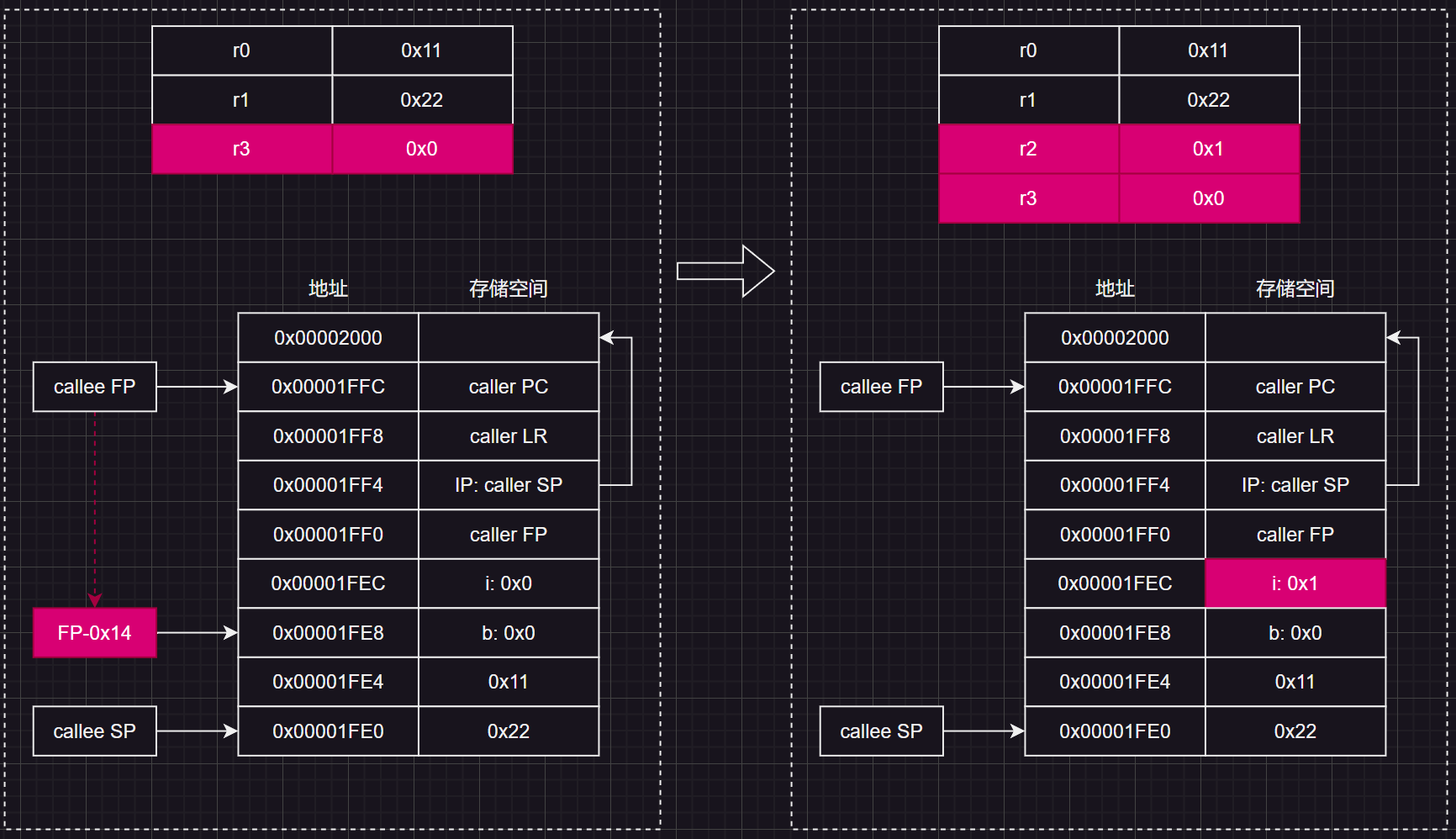
接着分析,我们会发现处理器的行为与我们在C语言的预期步骤是有出入的,这可能是因为指令重排序的原因,但无论怎样重排序,其结果与C语言的预期步骤得出的结果要保持一致。
调用子函数/子过程(subroutine)
这与我们从汇编开始调用 main_label的分析思路是一样的,这里不在赘述。
函数返回
接下来我们看一看 main_label函数的最后一行 return 0;都做了什么:
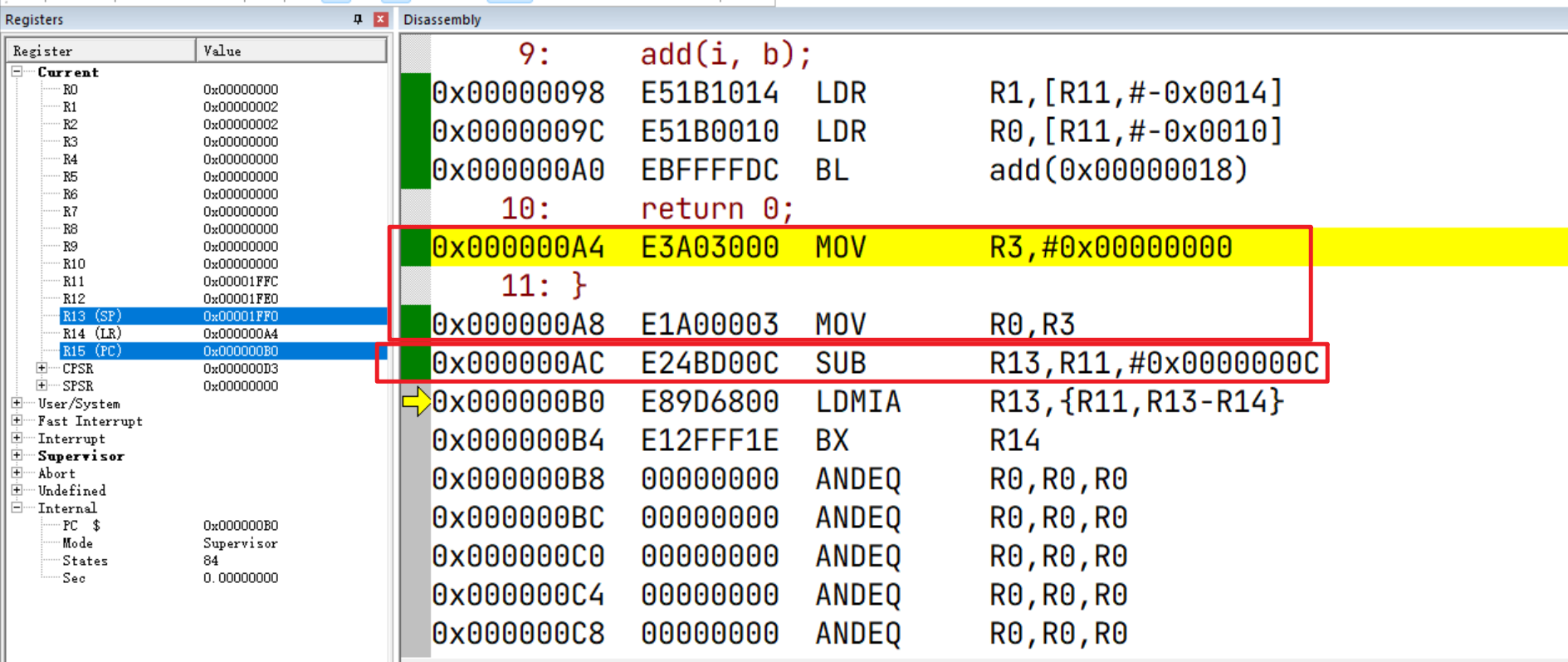
首先将常量 0(返回值)传输到R3进行临时保存;然后根据ATPCS标准,应该将返回值通过R0来传递,因此又将R3传输到了R0
接着通过 SUB,将R13(SP)指向R11(FP)向下偏移0xC的位置。如下图,SP指向这个位置后,相当于将函数参数和局部变量出栈释放了(对应图中灰色部分)
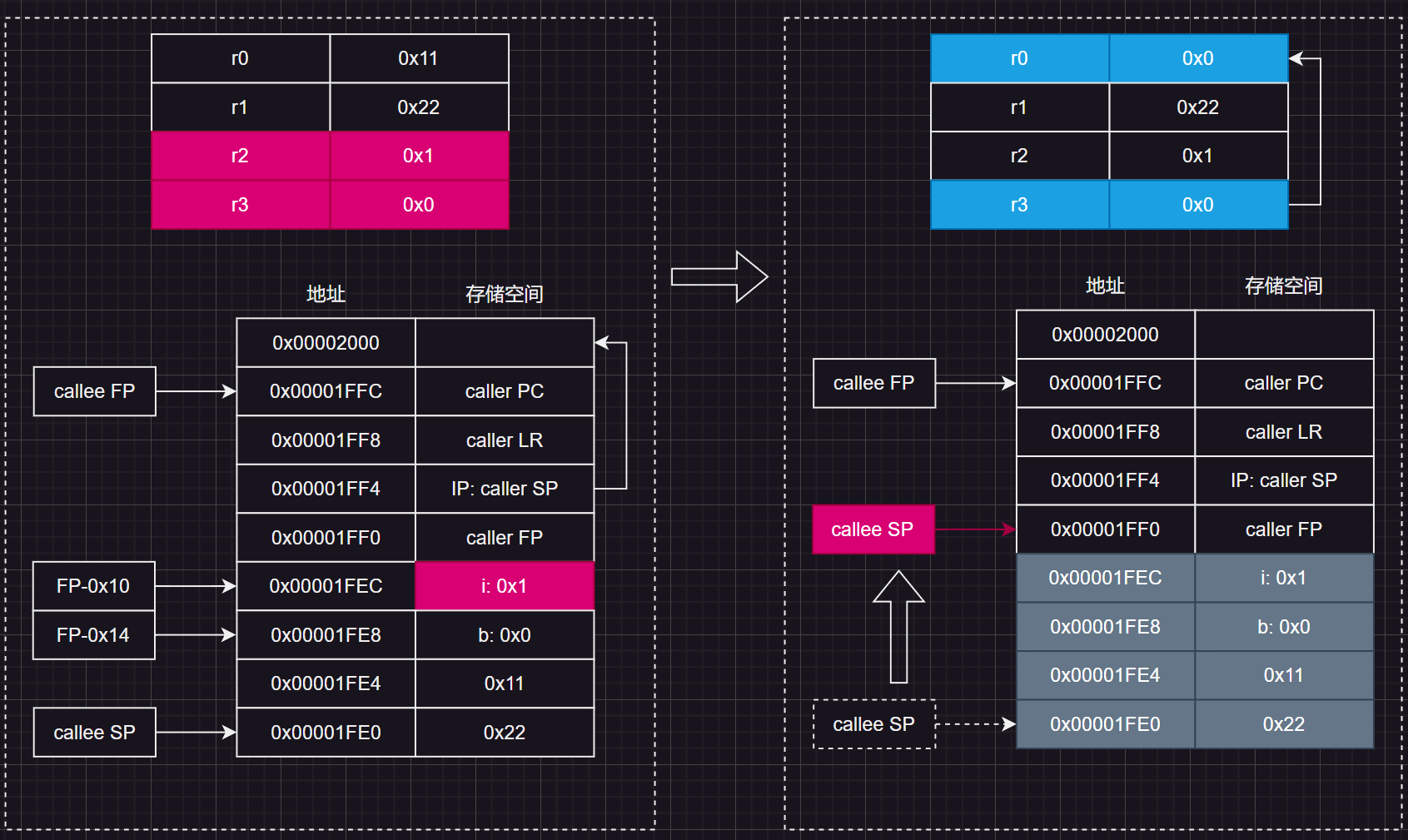
接着通过 LDMIA将还保存在栈中的调用方的LR, SP, FP恢复到R14, R13, R11中
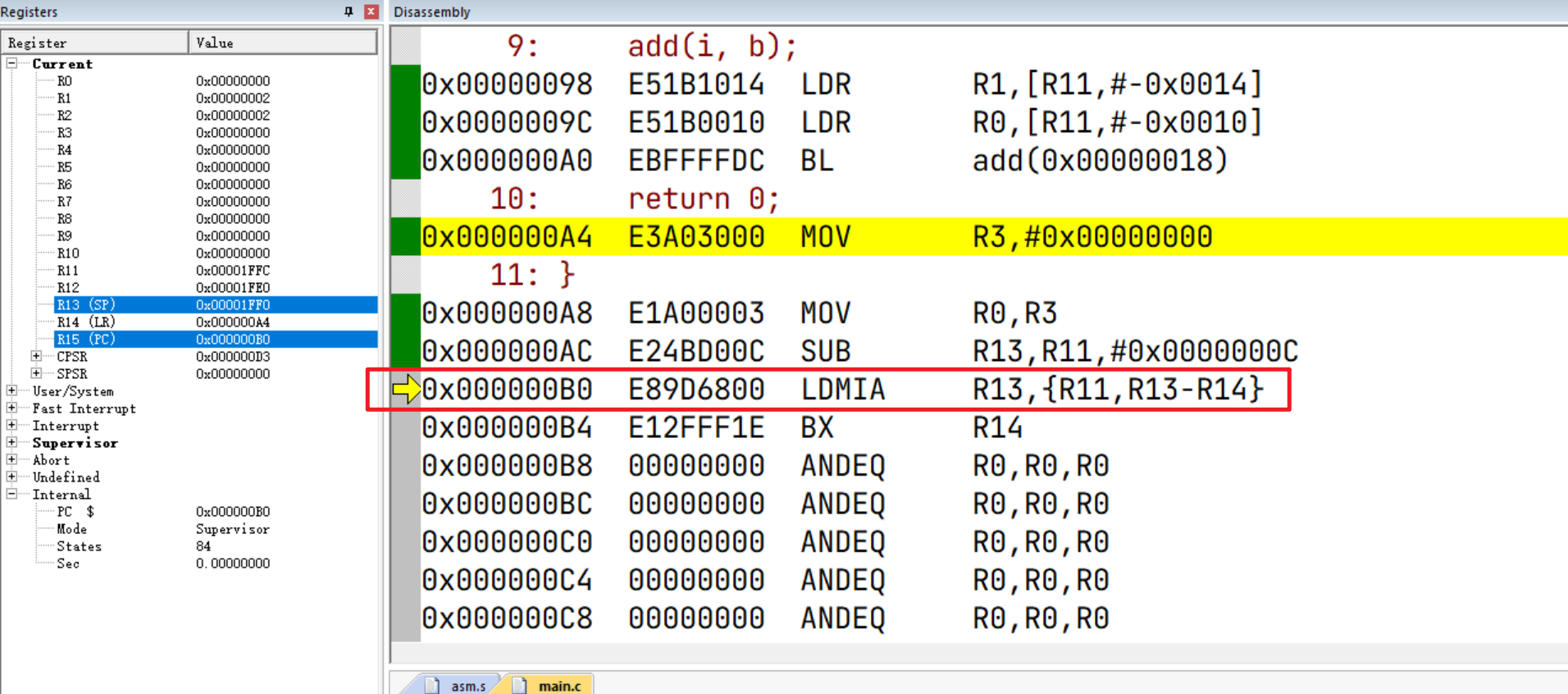
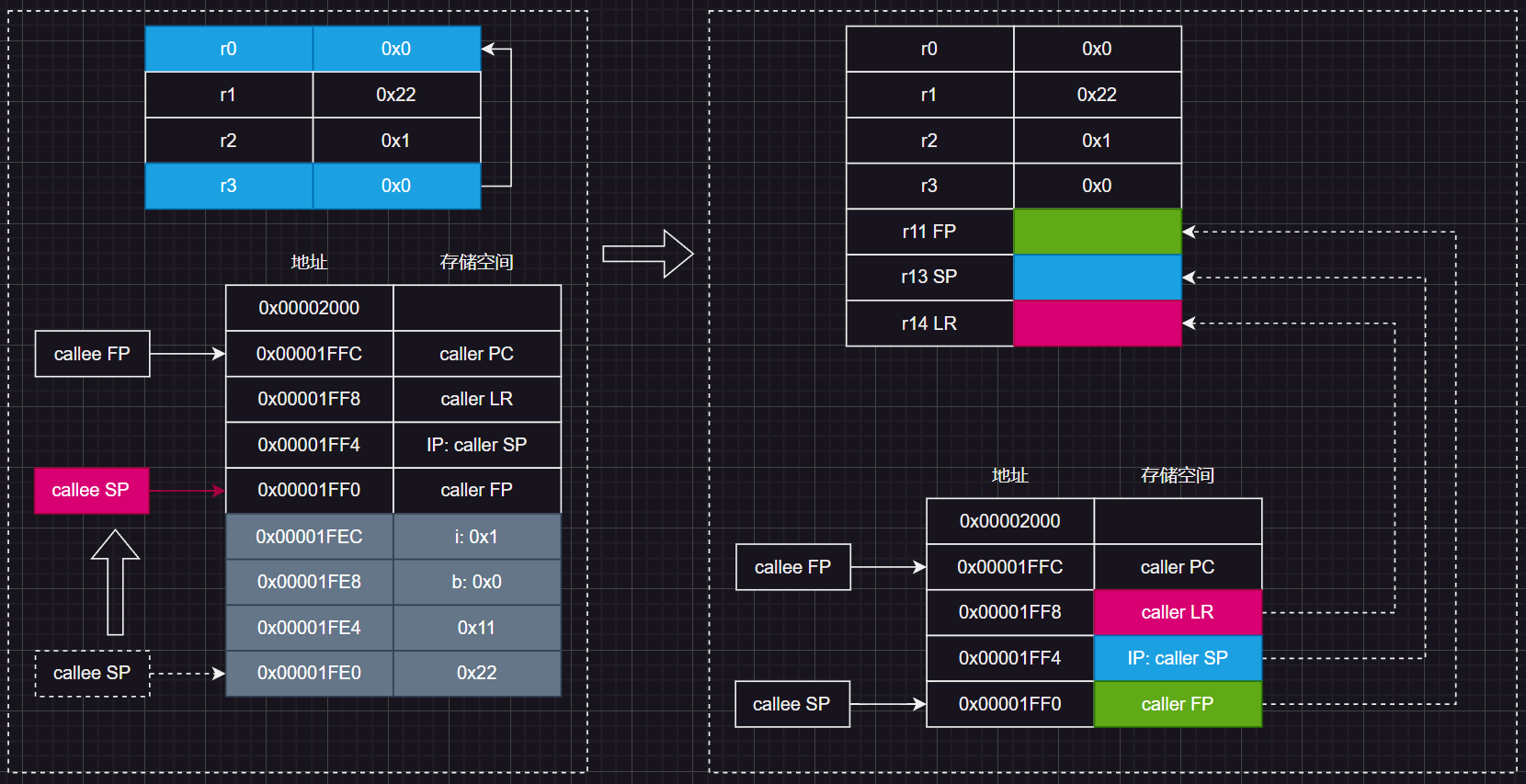
接着通过 BX指令根据LR(R14)跳转回调用方:
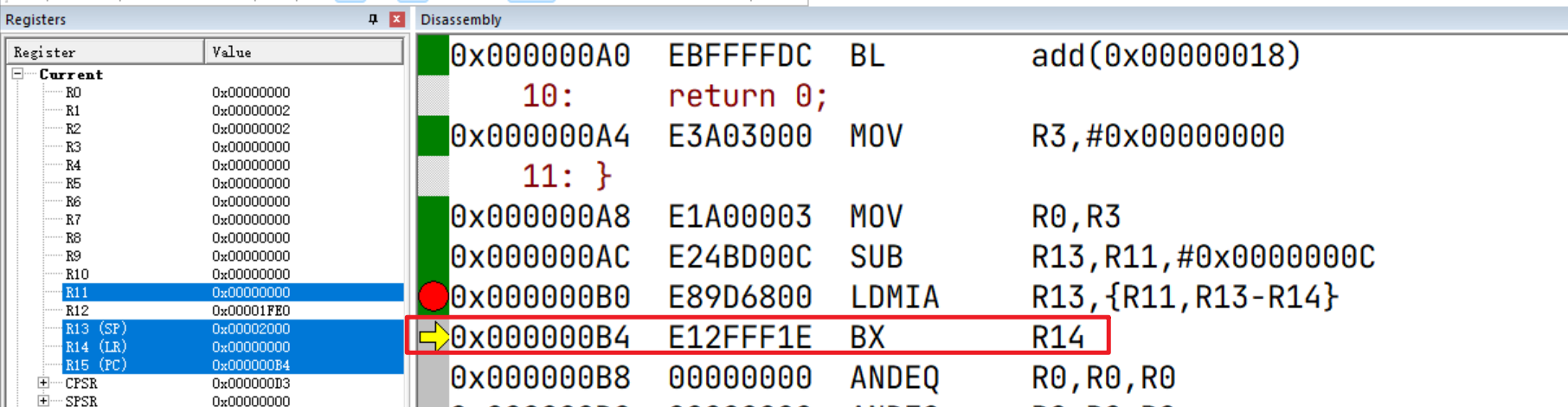
为什么通过LR可以跳转回去呢?
这是因为我们是通过 bl main_label跳转的,l后缀会将当前PC暂存到LR中,因此可以通过 BX R14跳转回去。
汇编与C混合编程
汇编语言调用C语言
再看C语言程序入口
C语言程序的入口是main函数吗?
经过上文的分析,我们知道C语言函数的执行过程是依赖栈的,在函数代码真正执行前需要将调用方程序状态相关的寄存器压栈保护(例如 LR, SP, FP)、函数参数压栈,如果有局部变量则也需要压栈,执行过程中的运算是基于栈和寄存器的配合来完成的。
因此每个函数的在执行前都需要设置栈的起始地址(SP),main当然也不例外,而这需要借助汇编来完成。
没有设置SP,函数无法正常执行
让我们来看下如下程序:
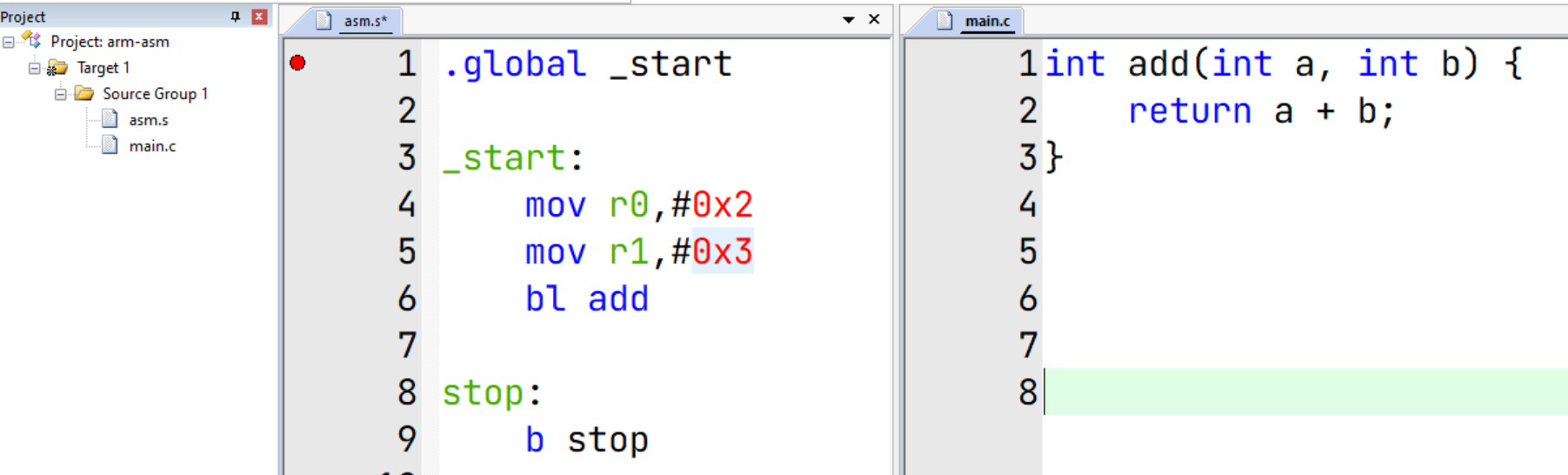
.global _start
_start:
mov r0,#0x2
mov r1,#0x3
bl add
stop:
b stop
int add(int a, int b) {
return a + b;
}调试前需要先禁用编译器优化并重新编译:
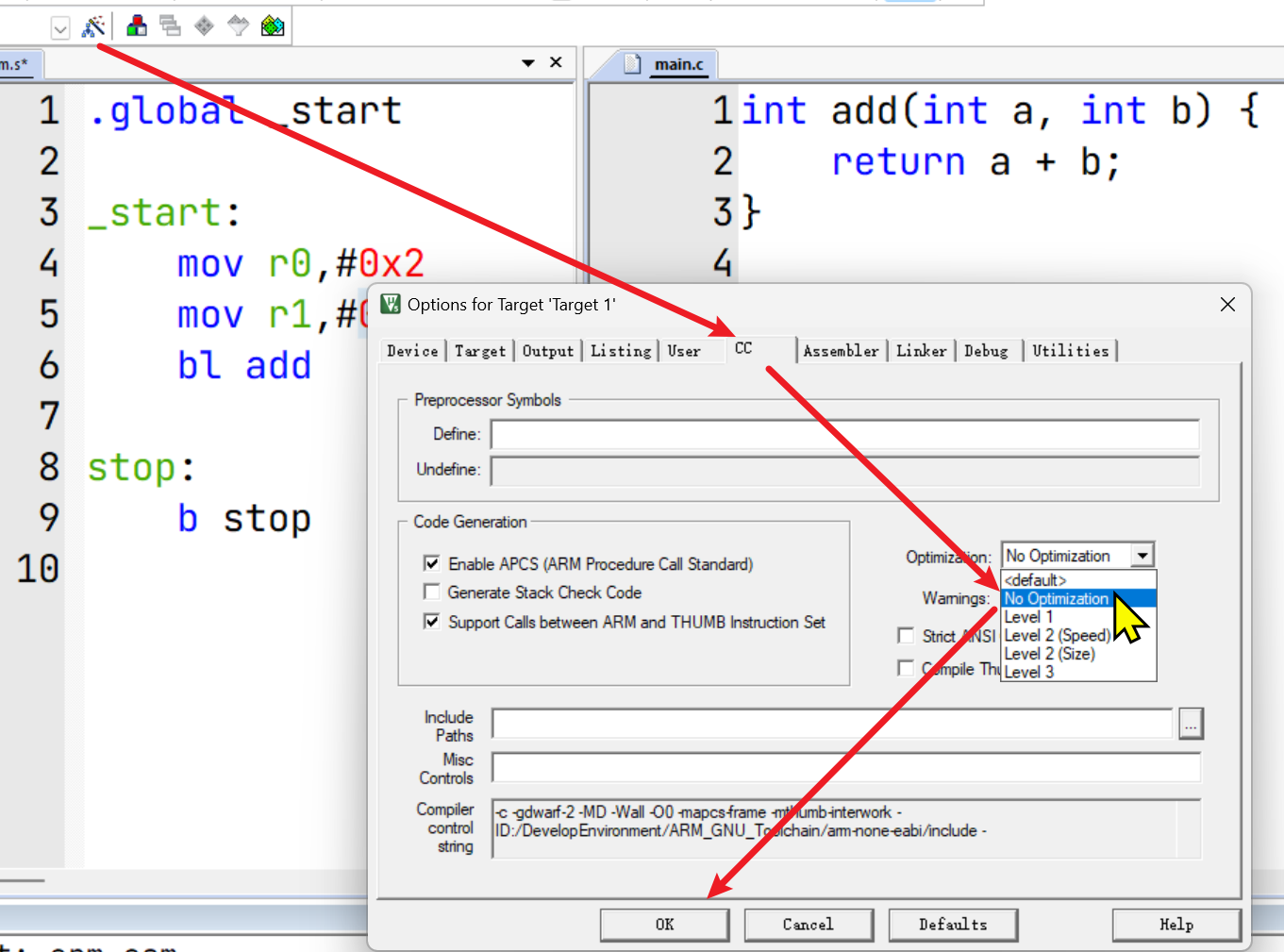
调试时会发现,函数执行前的压栈导致SP变成了0xFFFFFFF0,并且接着步进,程序无法按照预期结束。
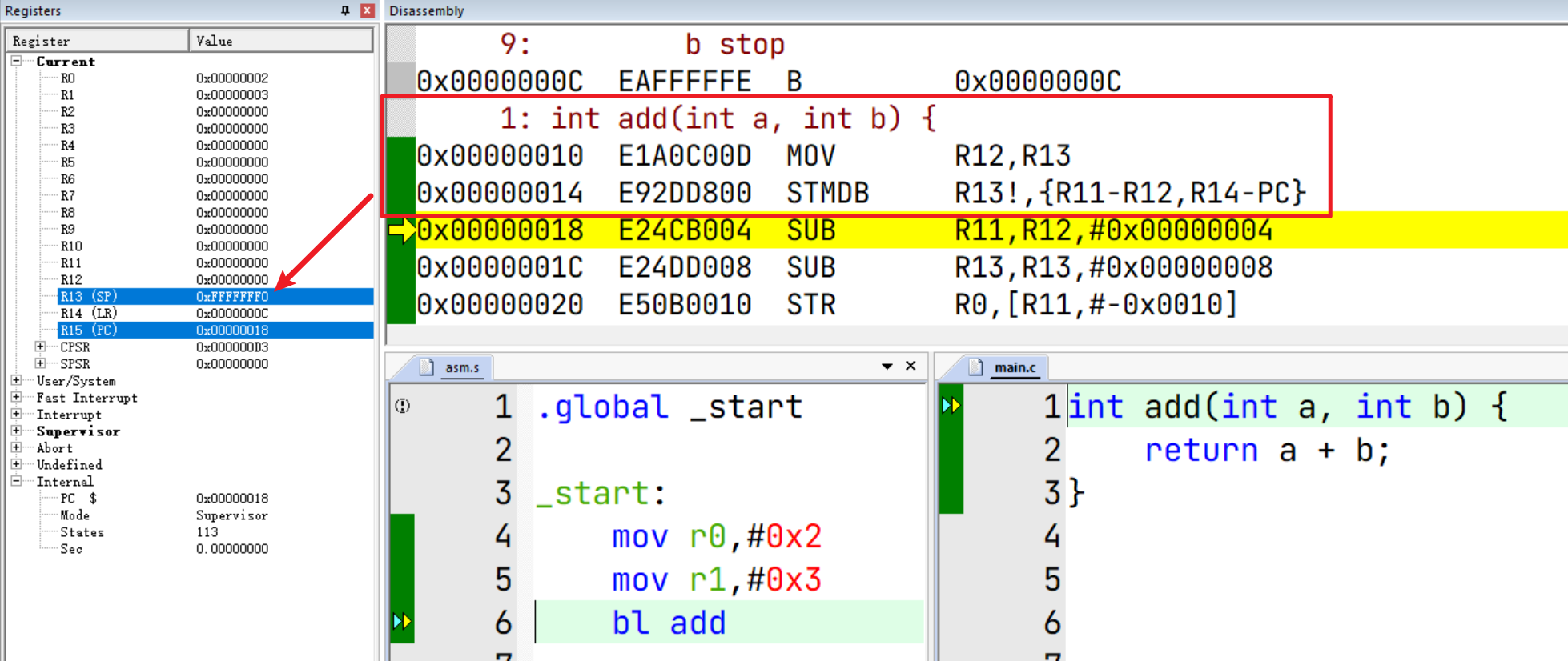
这是因为调用函数时没有设置SP,SP默认为零值:
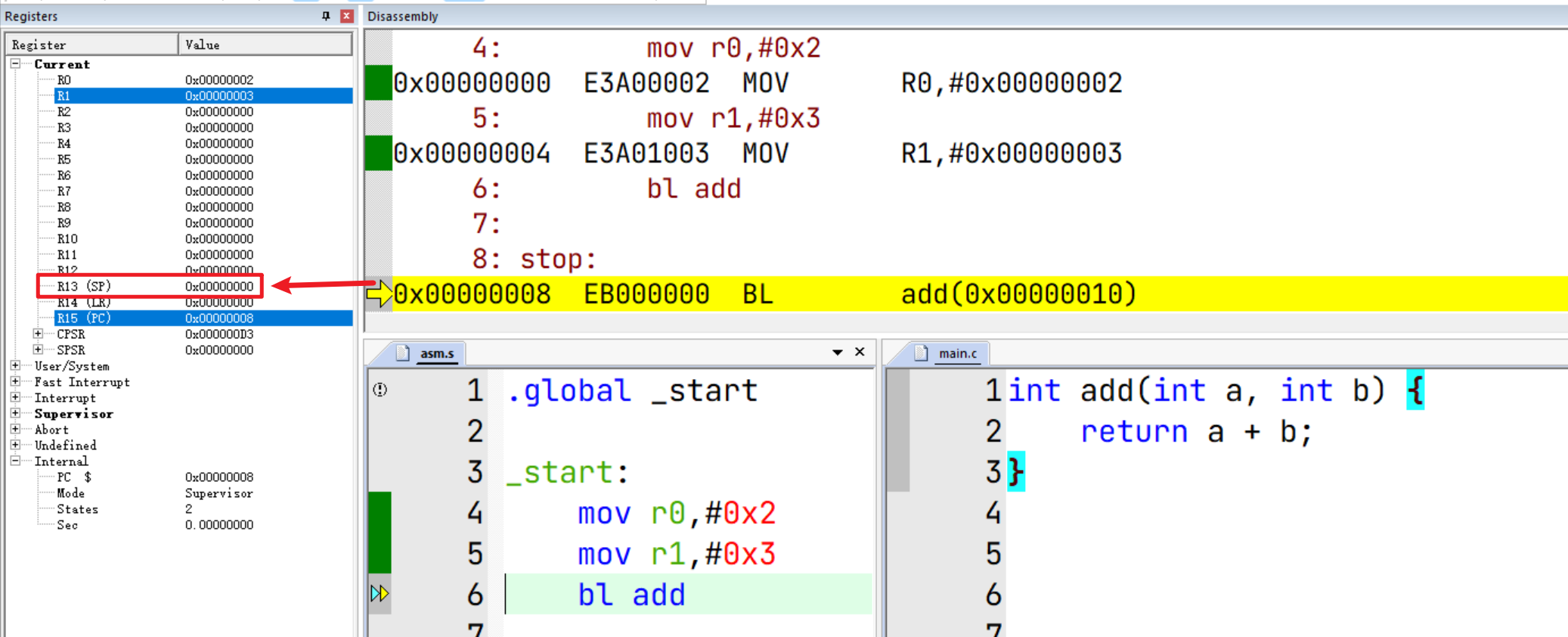
函数调用前需要正确设置SP
于是我们在函数调用前,设置一下栈指针SP,并将相应的内存范围映射一下
.global _start
_start:
mov r0,#0x2
mov r1,#0x3
ldr sp,=0x4000FFF0
bl add
stop:
b stop
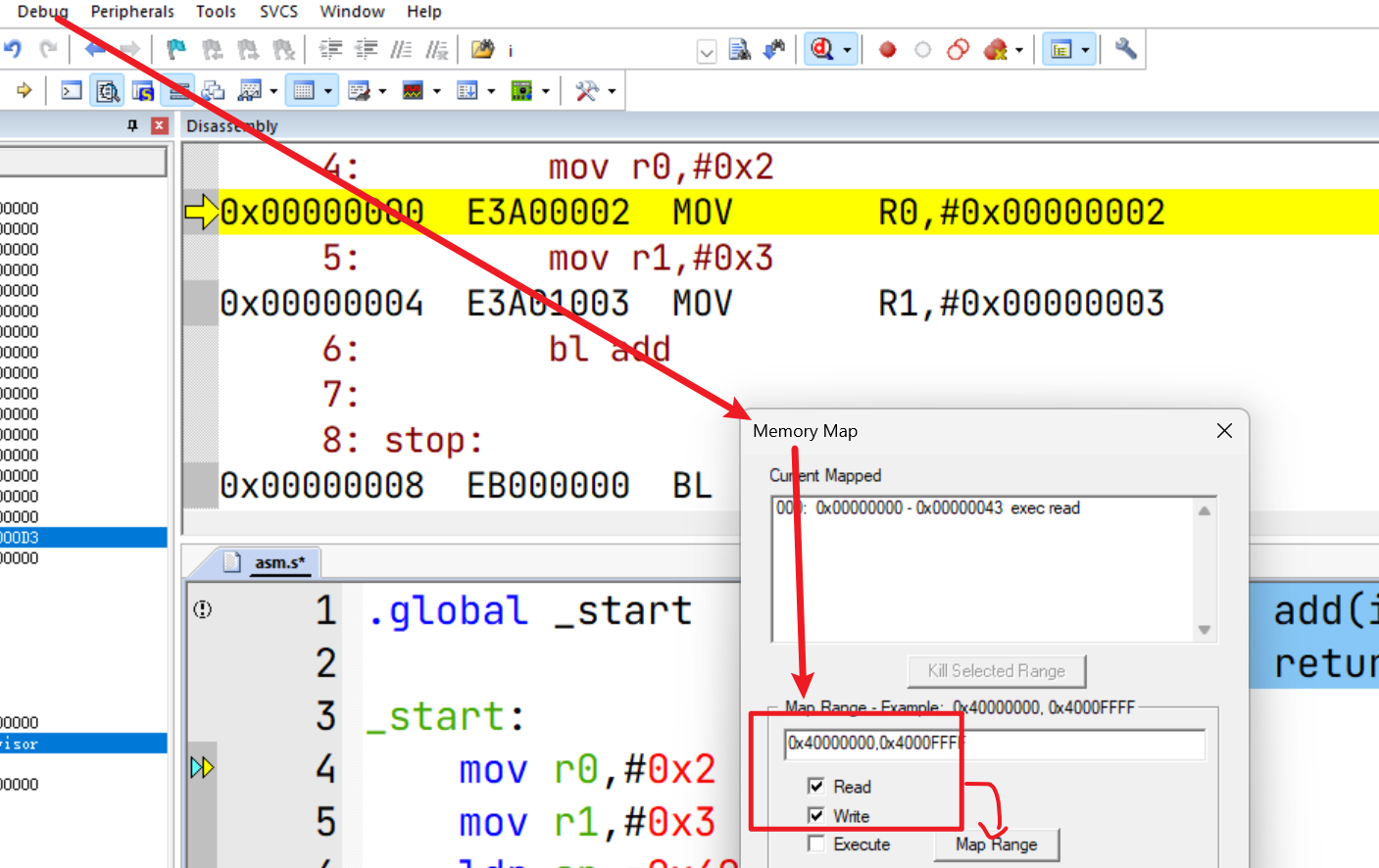
注意,这里要将SP设置为4的整数倍
0x40000000,0x4000FFFF
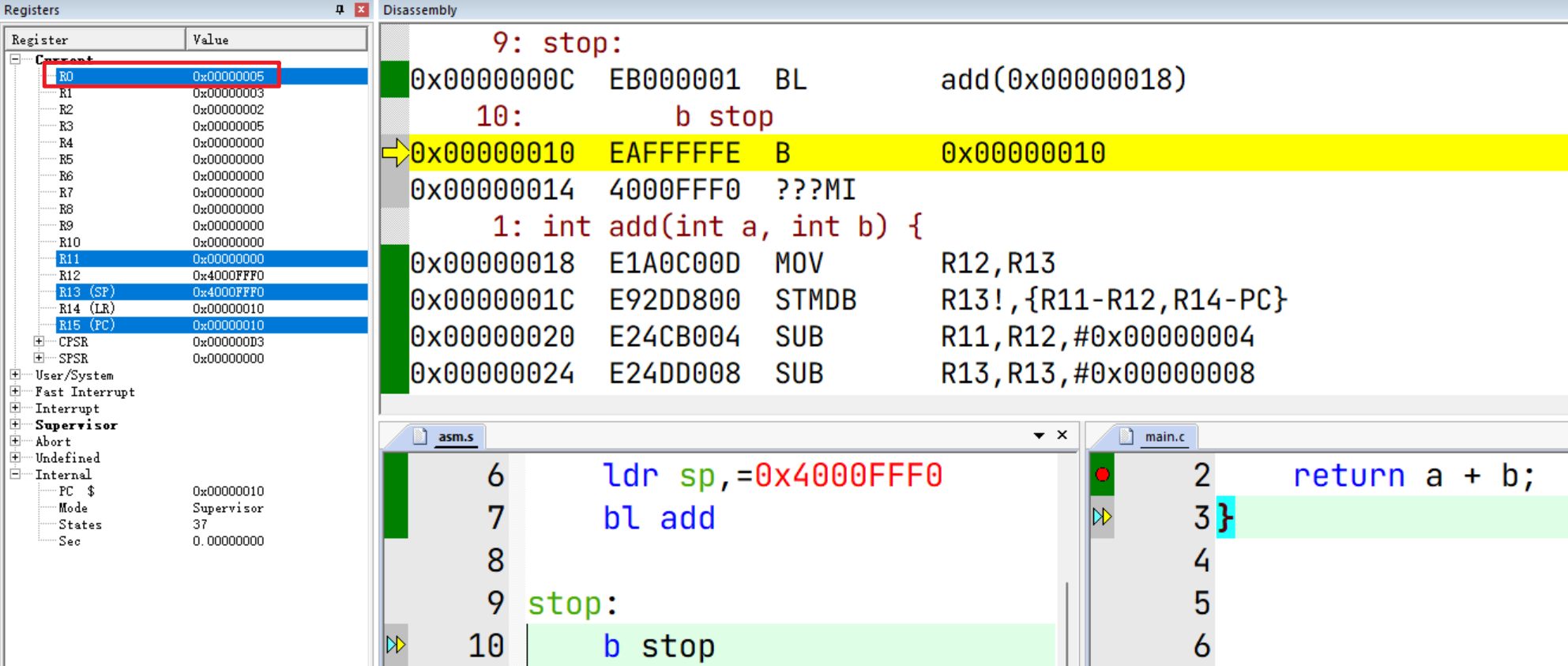
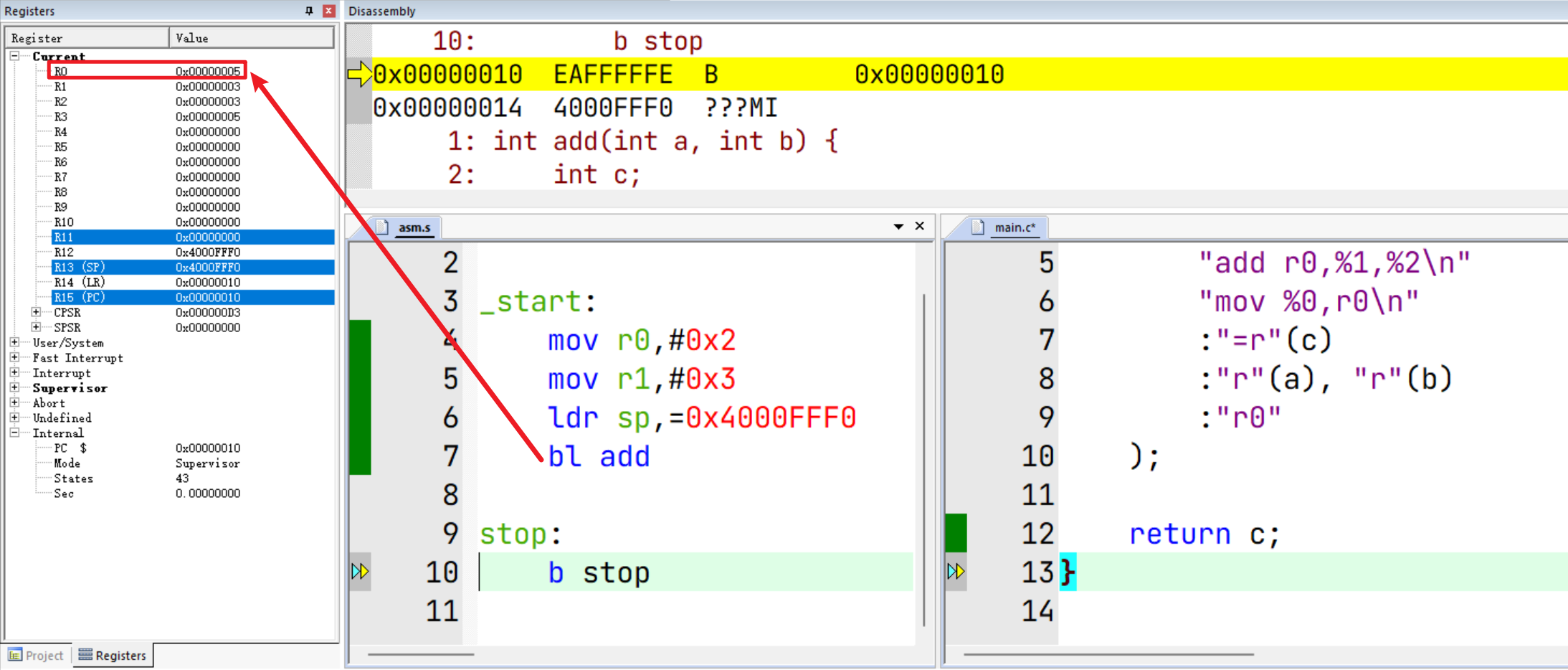
调整后发现可以正常执行到 stop,并且函数返回值 2+3=5也通过R0传递了过来
我们还可以打开函数调用栈窗口来更直观地观察入参压栈的过程:
C语言内嵌汇编
格式

示例
.global _start
_start:
mov r0,#0x2
mov r1,#0x3
ldr sp,=0x4000FFF0
bl add
stop:
b stop
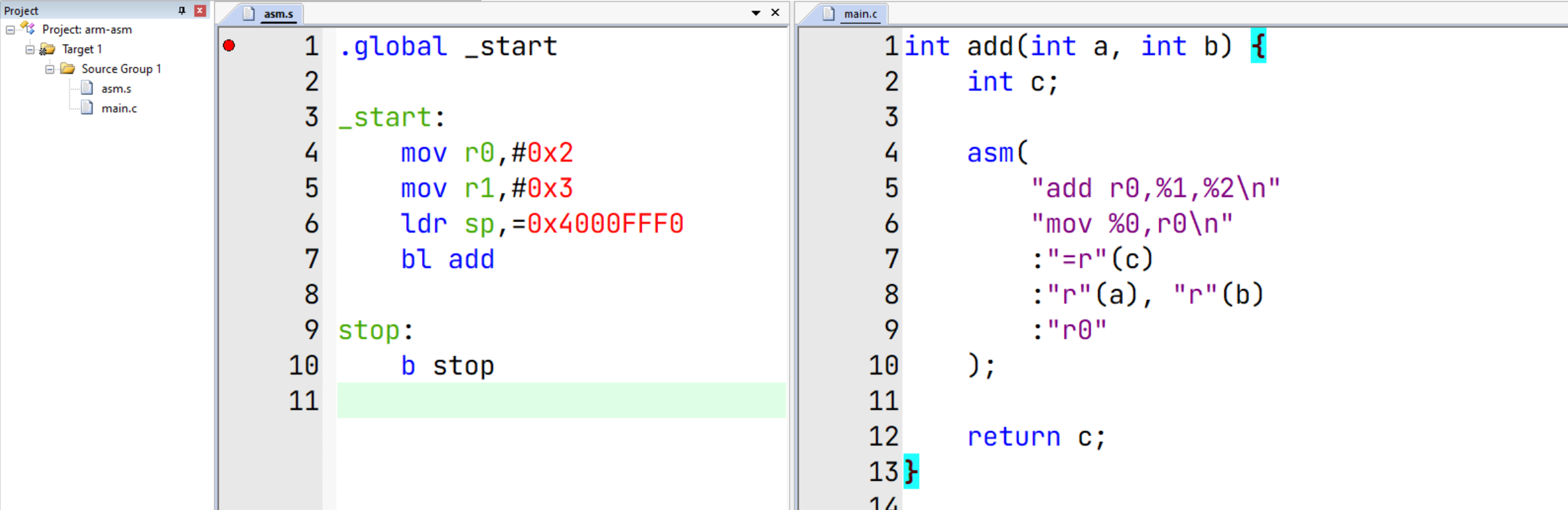
int add(int a, int b) {
int c;
asm(
"add r0,%1,%2\n"
"mov %0,r0\n"
:"=r"(c)
:"r"(a), "r"(b)
:"r0"
);
return c;
}
注意:可以通过%n引用输入列表、输出列表中的寄存器,从输出列表开始编号,输出列表的编号接着输入列表的最后一个
-
通过
asm关键字内嵌一段汇编代码 -
:"r"(a), "r"(b):输入列表,声明将C程序中哪些变量输入到内嵌汇编的通用寄存器中(具体哪个寄存器是无法预知的,可以通过%进行引用)。如果没有输入,则留一个空的冒号即可,但不能去掉该行。 -
"add r0,%1,%2\n":汇编指令,通过%1、%2引用输入列表的中的变量a、b对应的寄存器,并通过add指令将这两个寄存器相加,结果存入r0;注意,换行是不可省略的,标示这条指令结束 -
:"=r"(c):输出列表,声明将C程序的哪些变量的值由内嵌汇编输出。=标示了该汇编结束时需要将寄存器写入变量中。 -
"mov %0,r0\n":汇编指令,将r0中的值输入到%0引用的寄存器中,由于引用编号是从输出列表开始的,因此引用的就是变量c关联的寄存器

调试前别忘了映射下内存 0x40000000,0x4000FFFF
volatile关键字
gcc编译优化
示例程序
.global _start
_start:
ldr sp,=0x4000FFF0
bl add
stop:
b stop
int global_a = 0x3;
int global_b = 0x4;
int add() {
int c = global_a + global_b;
if(global_a > global_b) {
c++;
}
return c;
}
开启编译器优化
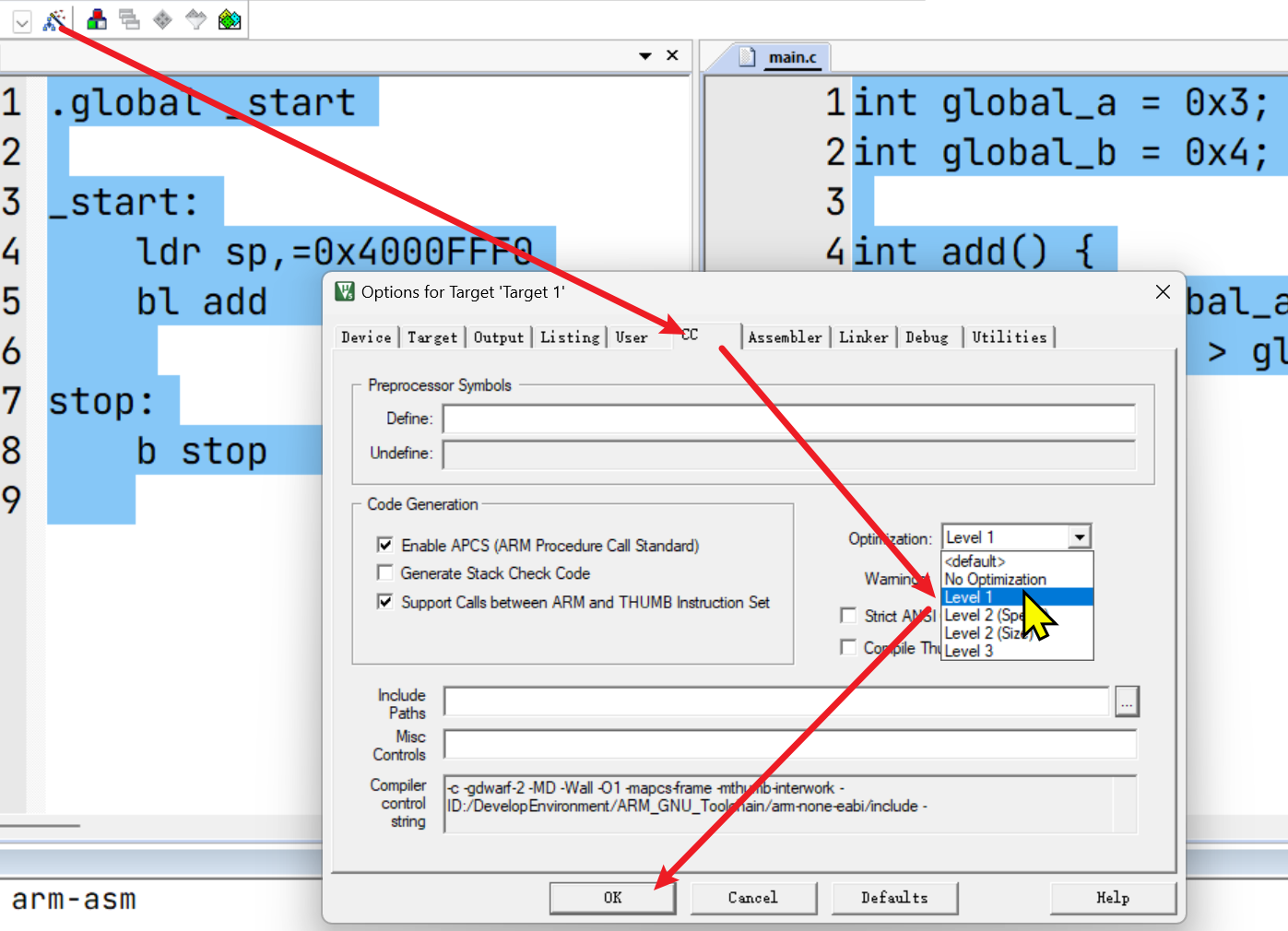
优化后的汇编指令分析
内存映射:0x40000000,0x4000FFFF
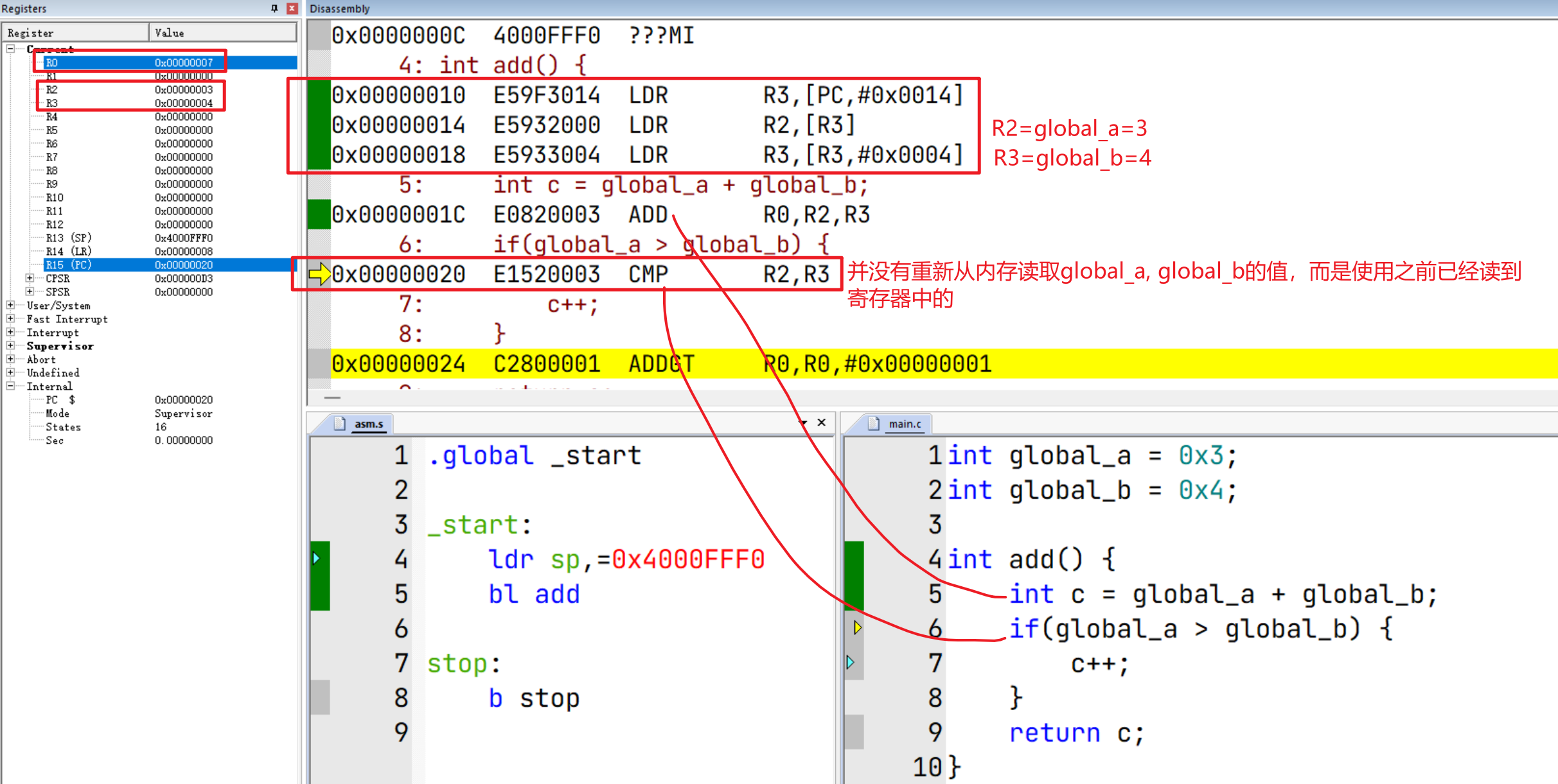
可以发现在执行 int c = global_a + global_b;时从内存读取 global_a和 global_b的值到R2, R3中;但是执行 if(global_a > global_b),并没重新从内存读取 global_a和 global_b的值,而是使用了此前R2, R3的快照。
编译器优化思想及弊端
[!NOTE]
根据另一篇文章《ARM核学习(三)指令流水线分析及伪指令》的分析,这是因为内存访问操作较低,无法发挥指令流水线的最佳性能,因此编译器优化会使用寄存器快照代替内存访问
那么在并发场景下,如果在执行 if(global_a > global_b)时发生了上下文切换,并且全局变量 global_a和 global_b的值被修改,那么 R2, R3中的值就不是最新的,因而会产生并发问题。
volatile关键字的作用
[!TIP]
volatile关键字的语意是易变的,被该关键字修饰的变量在读写时能够禁止编译器优化,从而使得每次读volatile变量强制从内存读取最新值(在CPU Cache模型中每次写volatile变量 也会立即将寄存器中的值刷新到内存)
下面我们给 global_a和 global_b加上 volatile修饰后再来调试下:
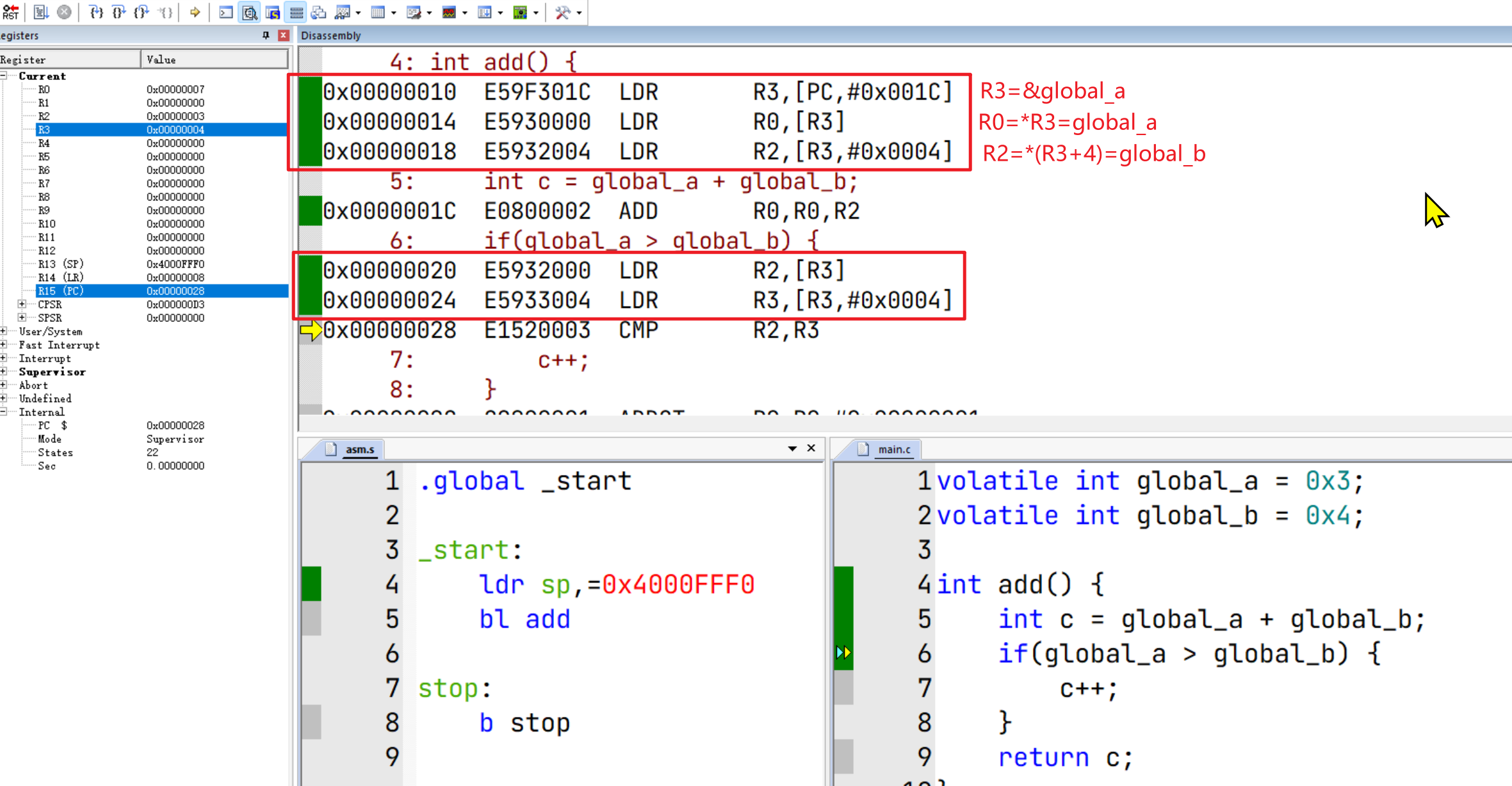
可以发现 if(global_a > global_b)时,通过 LDR指令,强制从内存读值了。



