参考资料
- ARMv7-M Architecture Reference Manual
- Mastering the FreeRTOS Real Time Kernel - A Hands On Tutorial Guide
- 《The Definitive Guide to ARM Cortex-M3 and Cortex-M4 processors 3rd edition》
- 《清华开发者书库 ARM Cortex-M3与Cortex-M4权威指南》
- 百问网《FreeRTOS入门与工程实践-基于STM32F103》教程-基于DShanMCU-103(STM32F103)
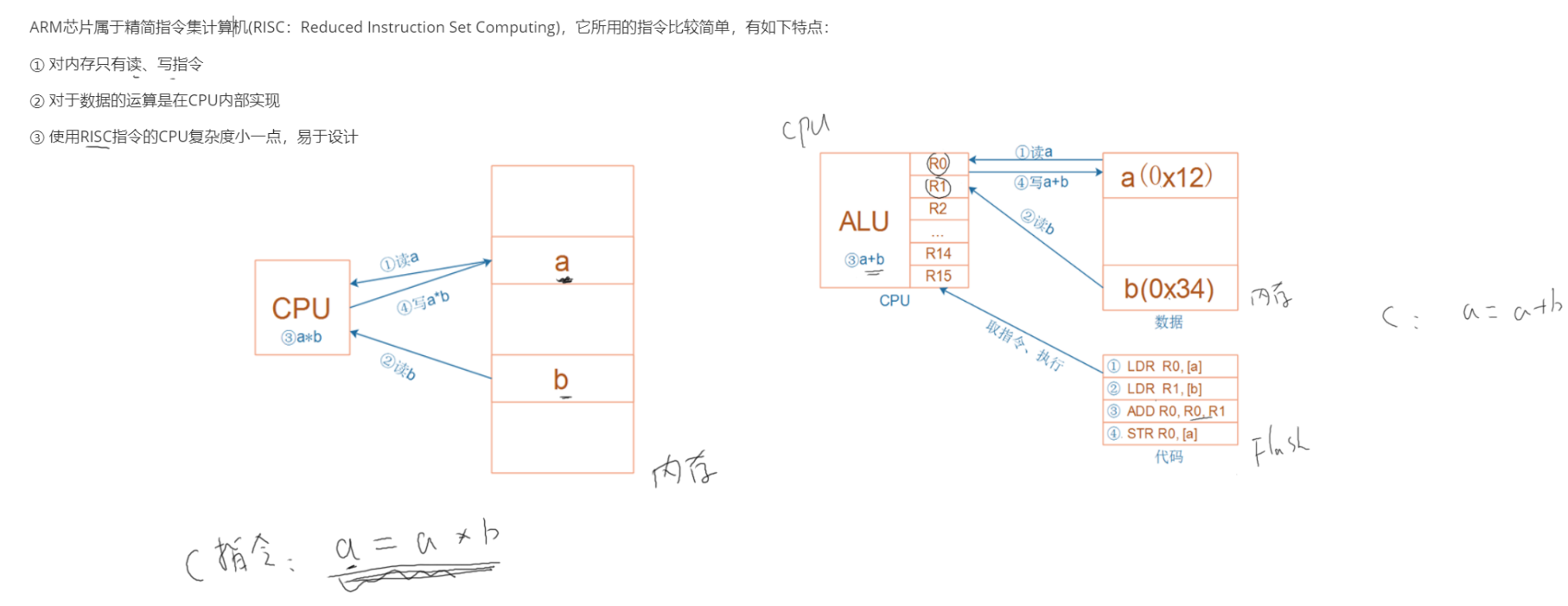
ARMv7-M架构
从C程序到汇编
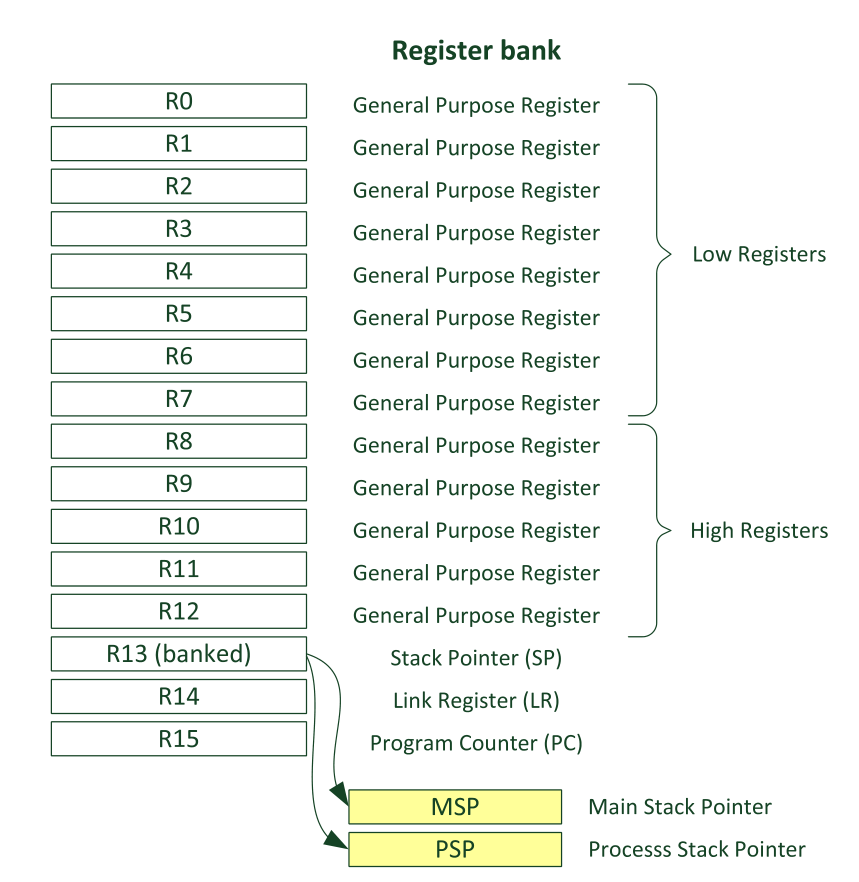
ARM核寄存器
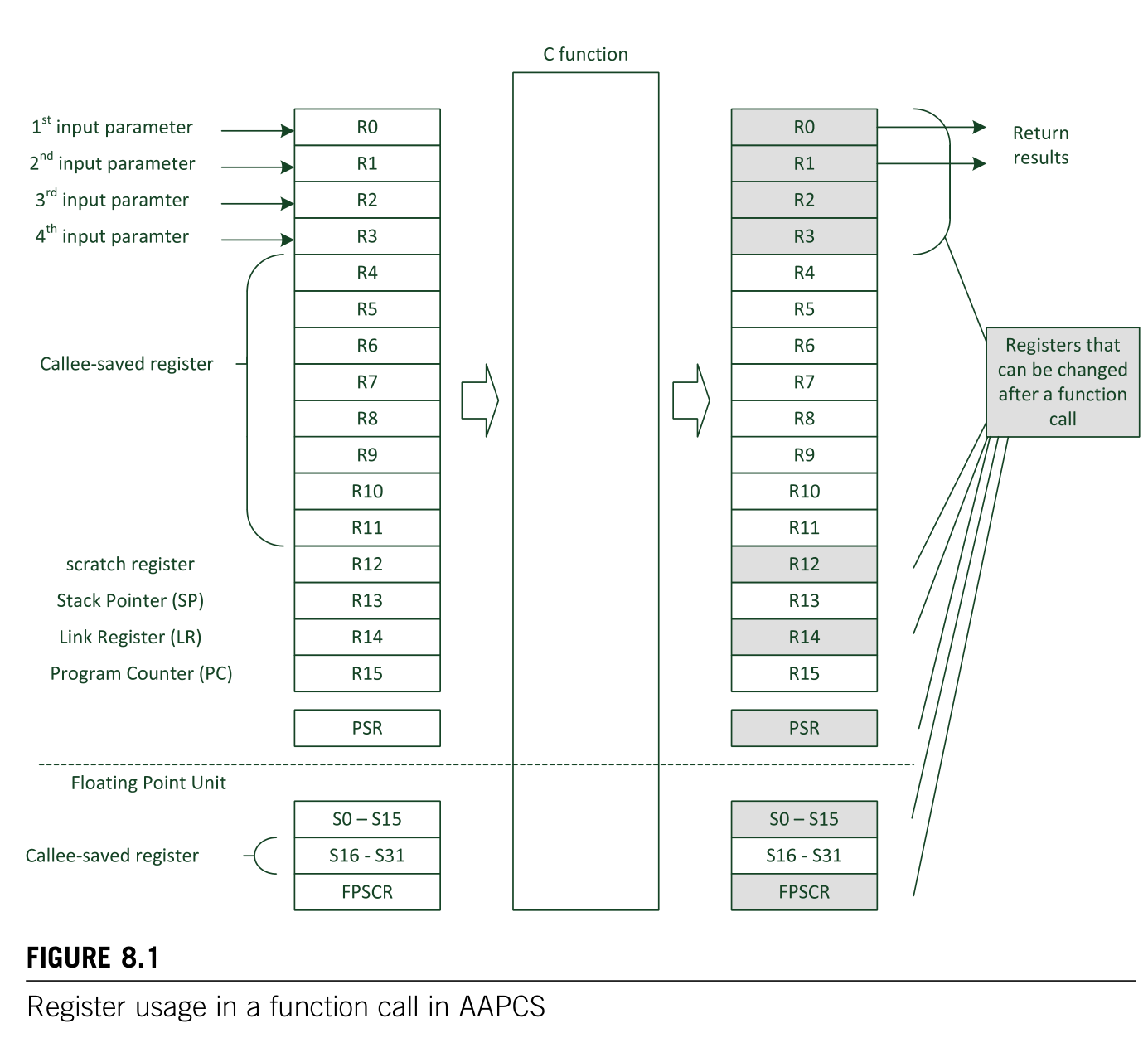
AAPCS(ARM架构过程调用标准)


异常处理
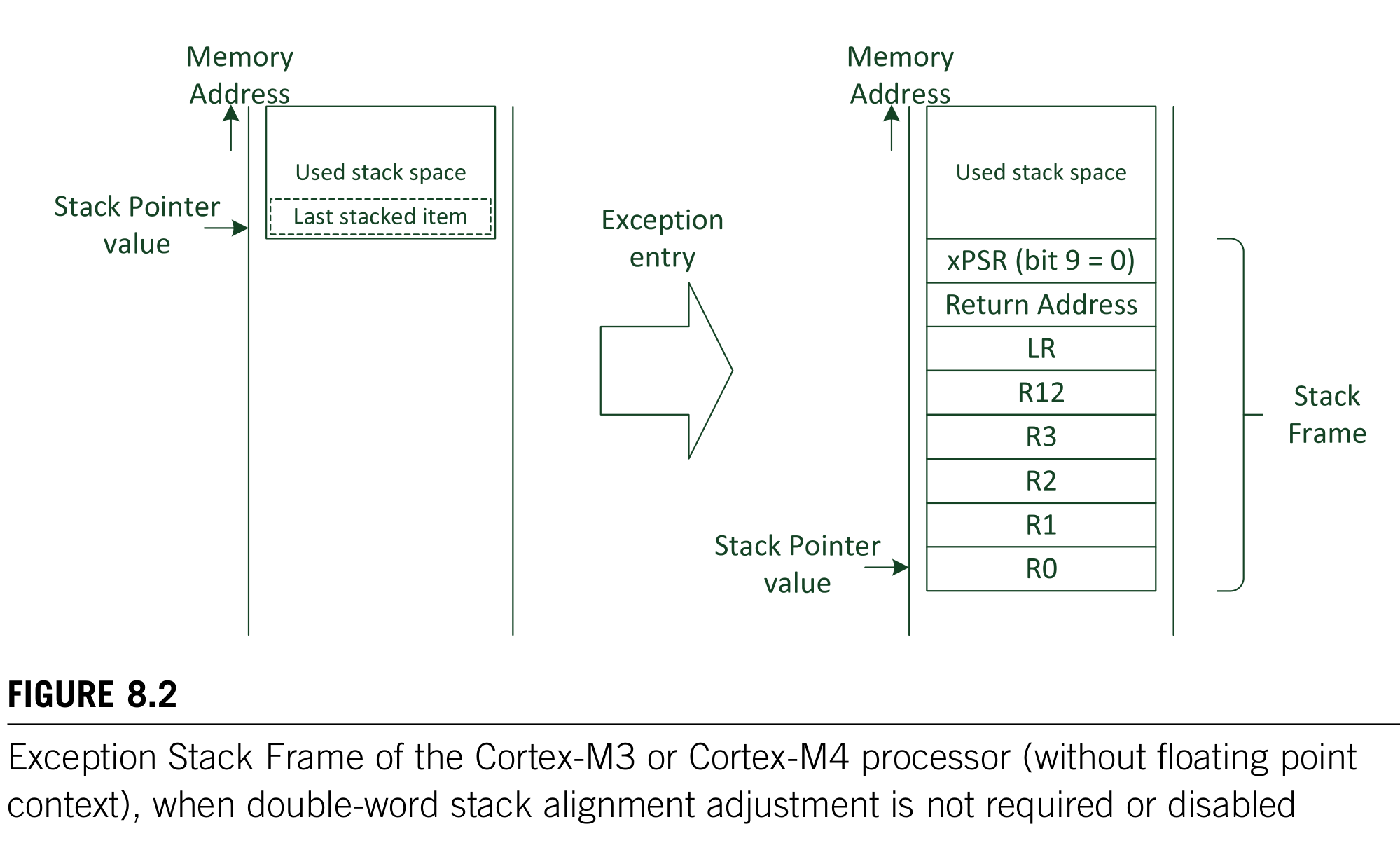
C函数调用反汇编分析
Keil生成反汇编
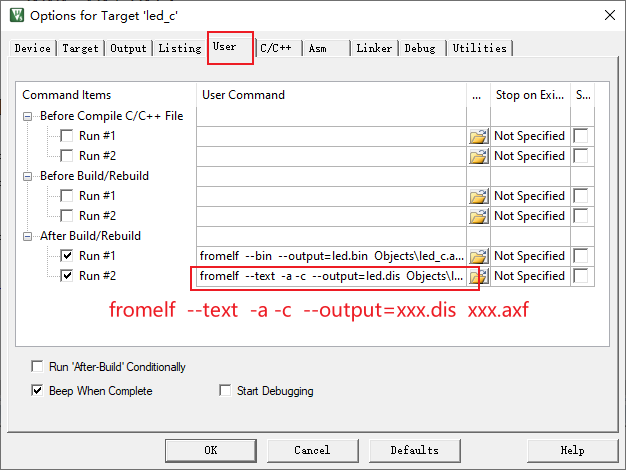
fromelf --text -a -c --output=xxx.dis xxx.axf
示例:fromelf --text -a -c --output=test.dis 01_freertos_template\01_freertos_template.axf结合AAPCS分析C函数调用
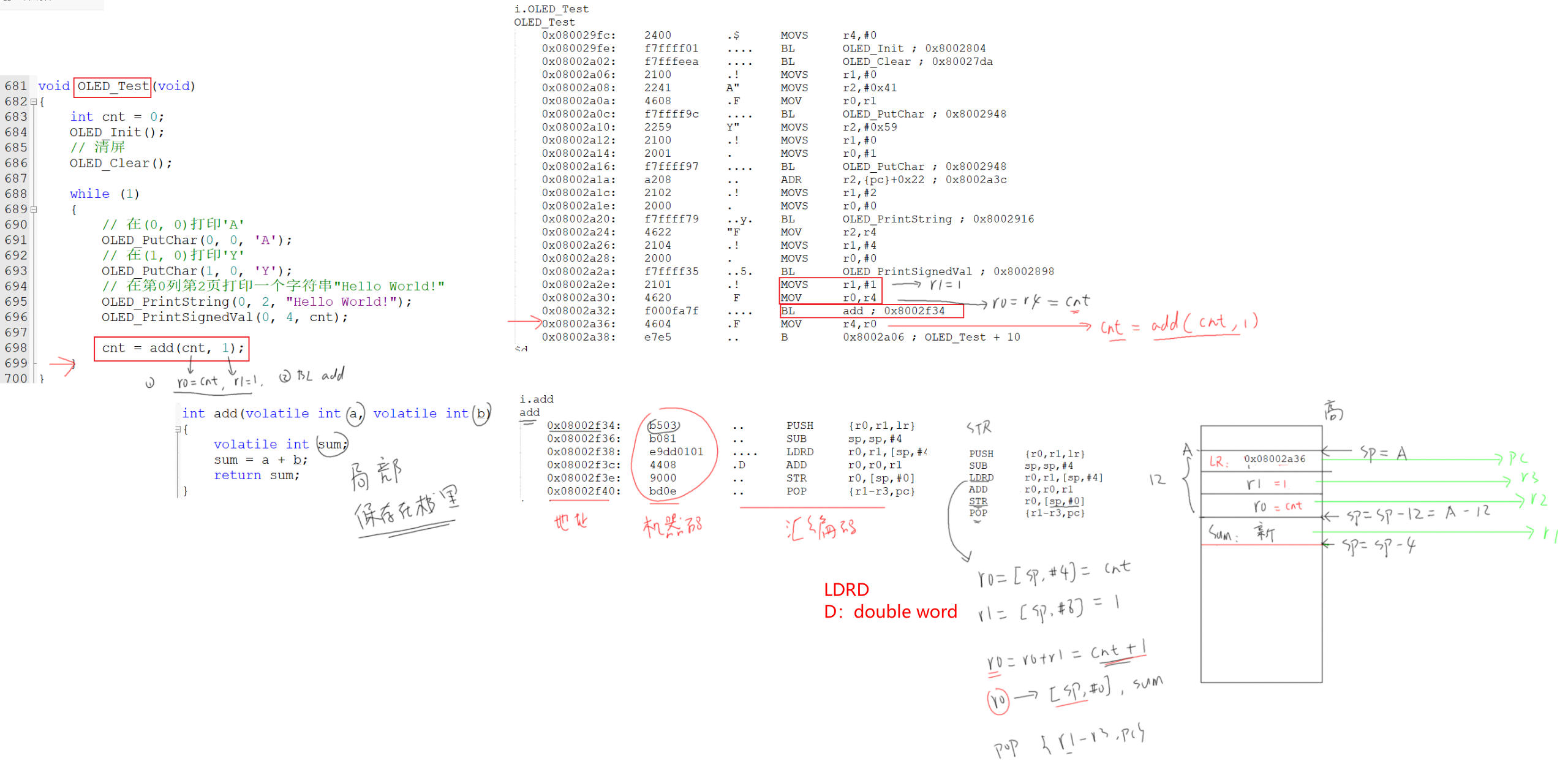
- 局部变量不一定保存在栈中,经过编译器优化后可能保存在Rn寄存器中;通过
volatile关键字可以强制将其保存在栈中
内存管理
为什么要自己实现内存管理
FreeRTOS中有内核对象:task、queue、semaphores和event group等。为了让FreeRTOS更容易使用,这些内核对象一般都是动态分配:用到时分配,不使用时释放。使用内存的动态管理功能,简化了程序设计:不再需要小心翼翼地提前规划各类对象,简化API函数的涉及,甚至可以减少内存的使用。
在C语言的库函数中,有mallc、free等函数,但是在FreeRTOS中,它们不适用:
- 不适合用在资源紧缺的嵌入式系统中
- 这些函数的实现过于复杂、占据的代码空间太大
- 并非线程安全的(thread- safe)
- 运行有不确定性:每次调用这些函数时花费的时间可能都不相同
- 内存碎片化
- 使用不同的编译器时,需要进行复杂的配置
- 有时候难以调试
堆管理算法
只分配不回收
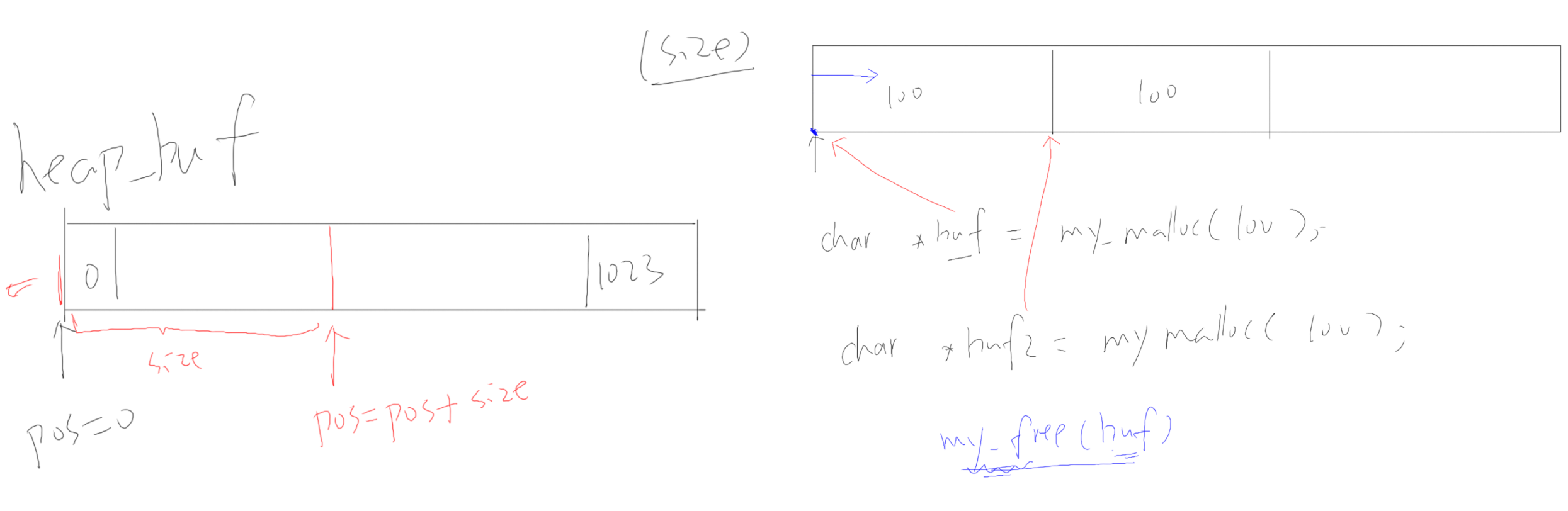
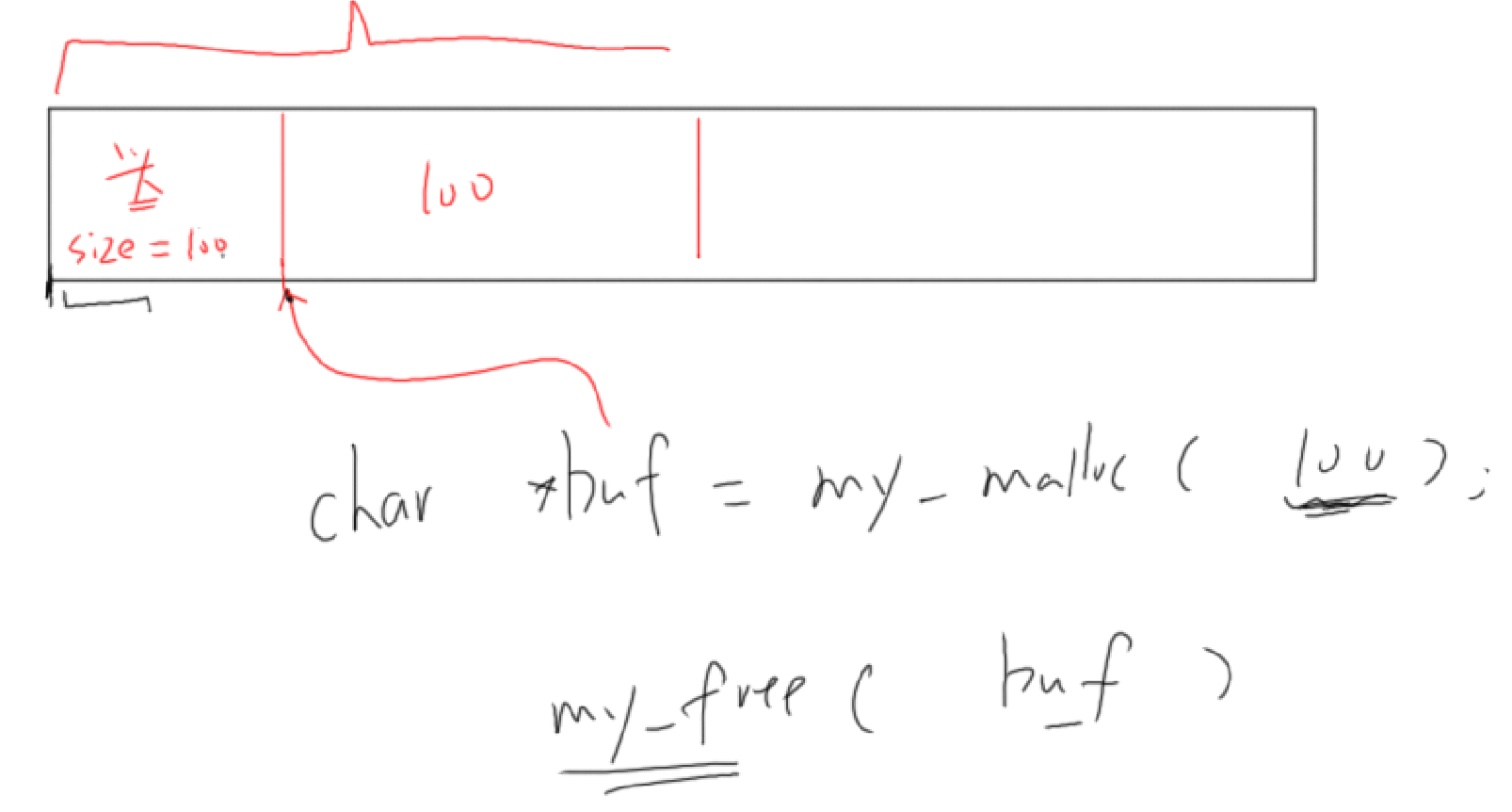
元数据header+空闲链表
堆和栈
注意:我们经常"堆栈"混合着说,其实它们不是同一个东西:
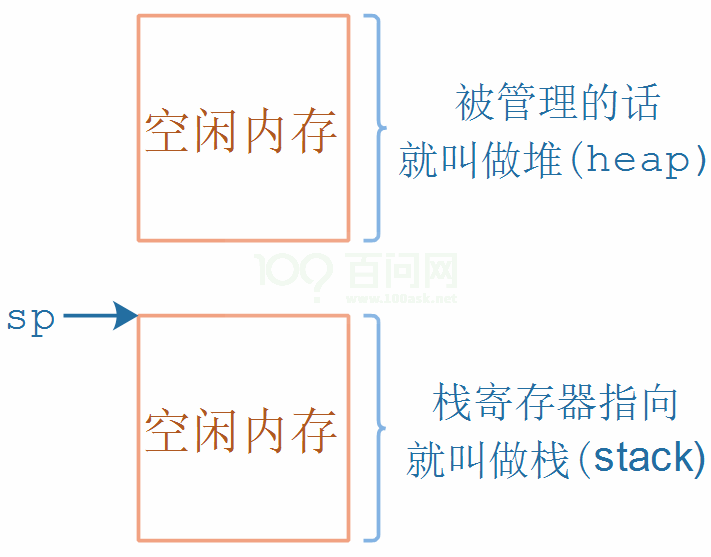
- 堆,heap,就是一块空闲的内存,需要提供管理函数
- malloc:从堆里划出一块空间给程序使用
- free:用完后,再把它标记为"空闲"的,可以再次使用
- 栈,stack,函数调用时局部变量保存在栈中,当前程序的环境也是保存在栈中
- 可以从堆中分配一块空间用作栈
FreeRTOS中任务栈的创建和释放
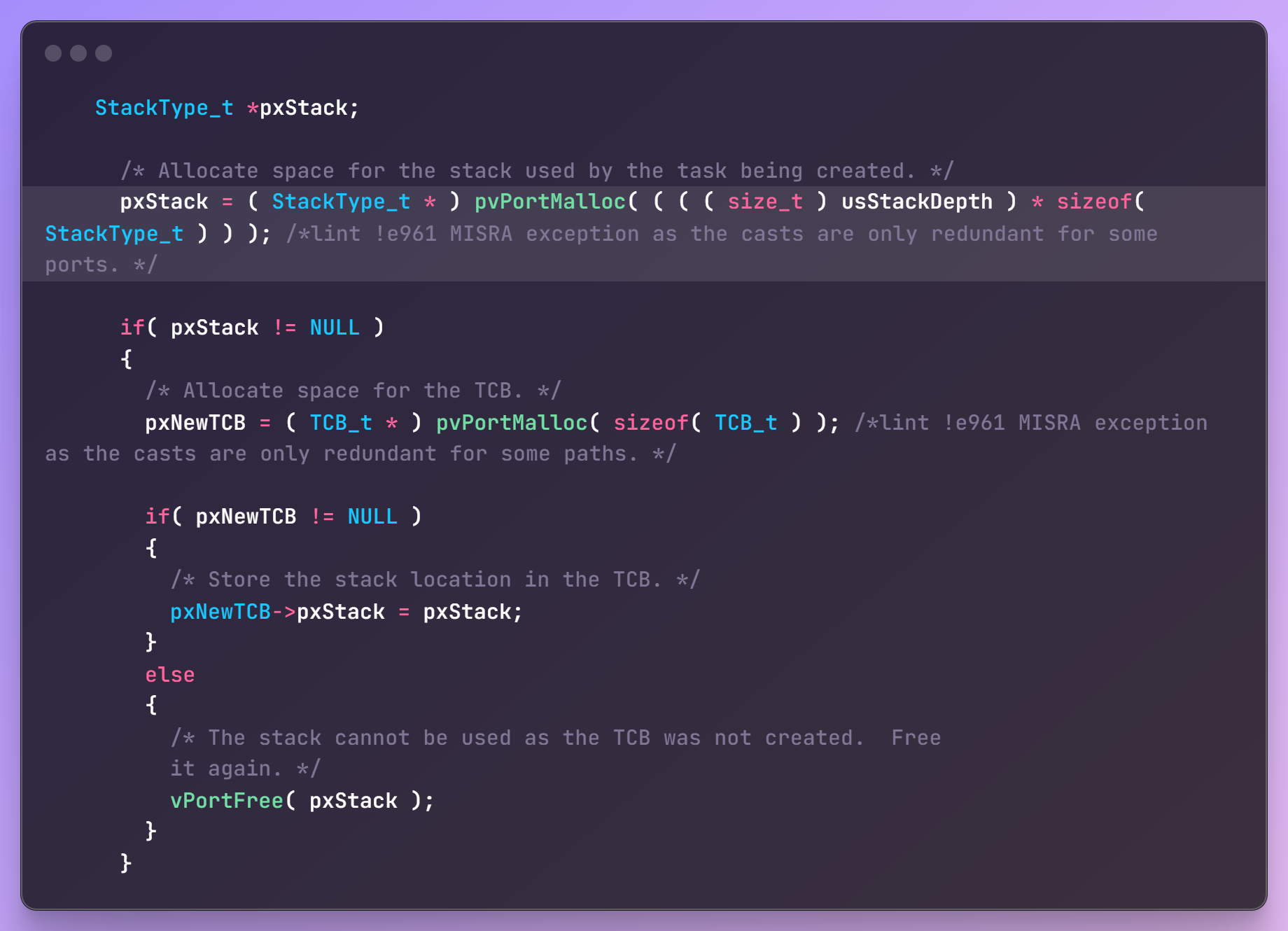
FreeRTOS中的内存管理
FreeRTOS中内存管理的接口函数为:pvPortMalloc 、vPortFree,对应于C库的malloc、free。 文件在FreeRTOS/Source/portable/MemMang下,它也是放在portable目录下,表示你可以提供自己的函数。
源码中默认提供了5个文件,对应内存管理的5种方法:
| 文件 | 优点 | 缺点 |
|---|---|---|
| heap_1.c | 分配简单,时间确定 | 只分配、不回收 |
| heap_2.c | 动态分配、最佳匹配 | 碎片、时间不定 |
| heap_3.c | 调用标准库函数 | 速度慢、时间不定 |
| heap_4.c | 相邻空闲内存可合并 | 可解决碎片问题、时间不定 |
| heap_5.c | 在heap_4基础上支持分隔的内存块 | 可解决碎片问题、时间不定 |
heap_1
它只实现了pvPortMalloc,没有实现vPortFree。
如果你的程序不需要删除内核对象,那么可以使用heap_1:
- 实现最简单
- 没有碎片问题
- 一些要求非常严格的系统里,不允许使用动态内存,就可以使用
heap_1
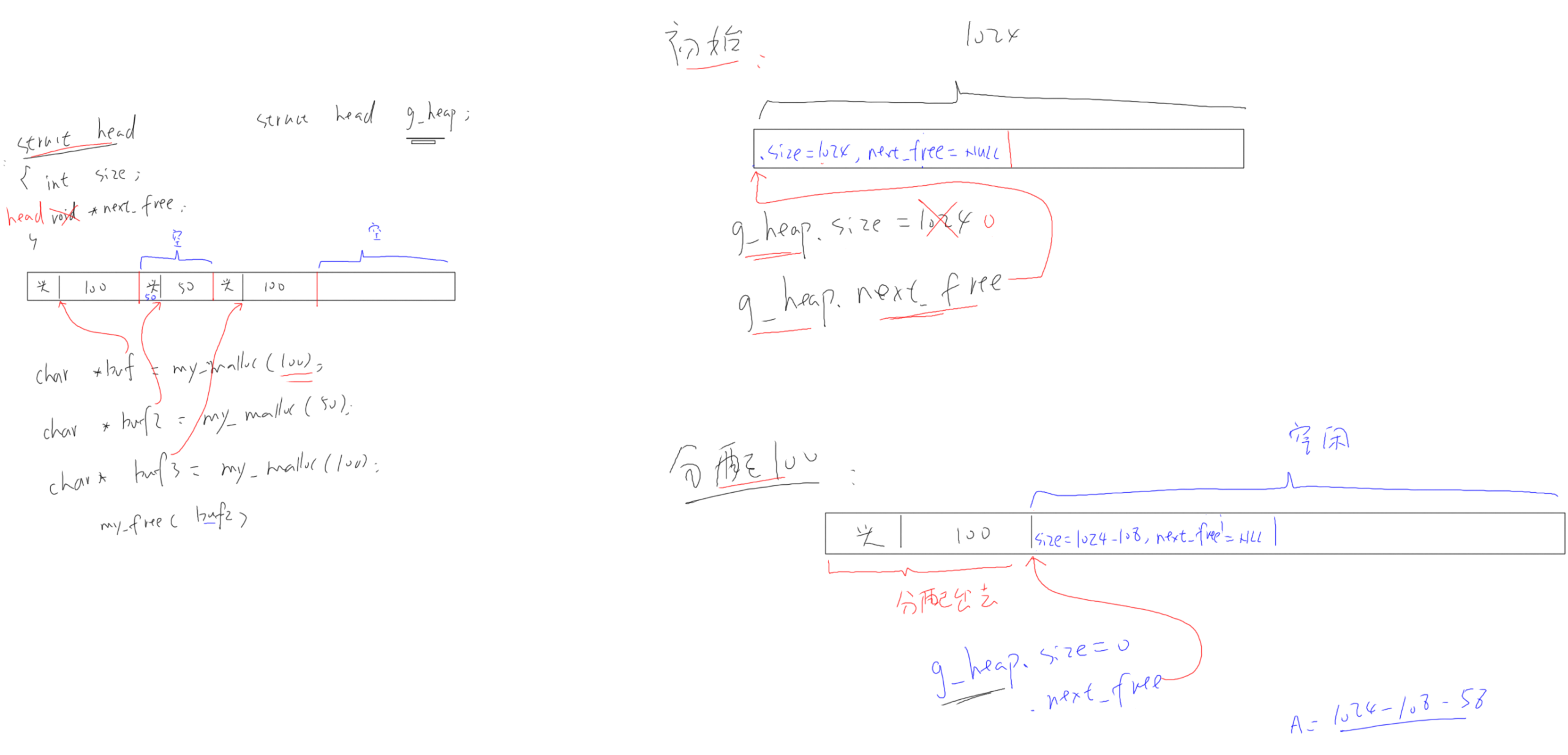
它的实现原理很简单,首先定义一个大数组:
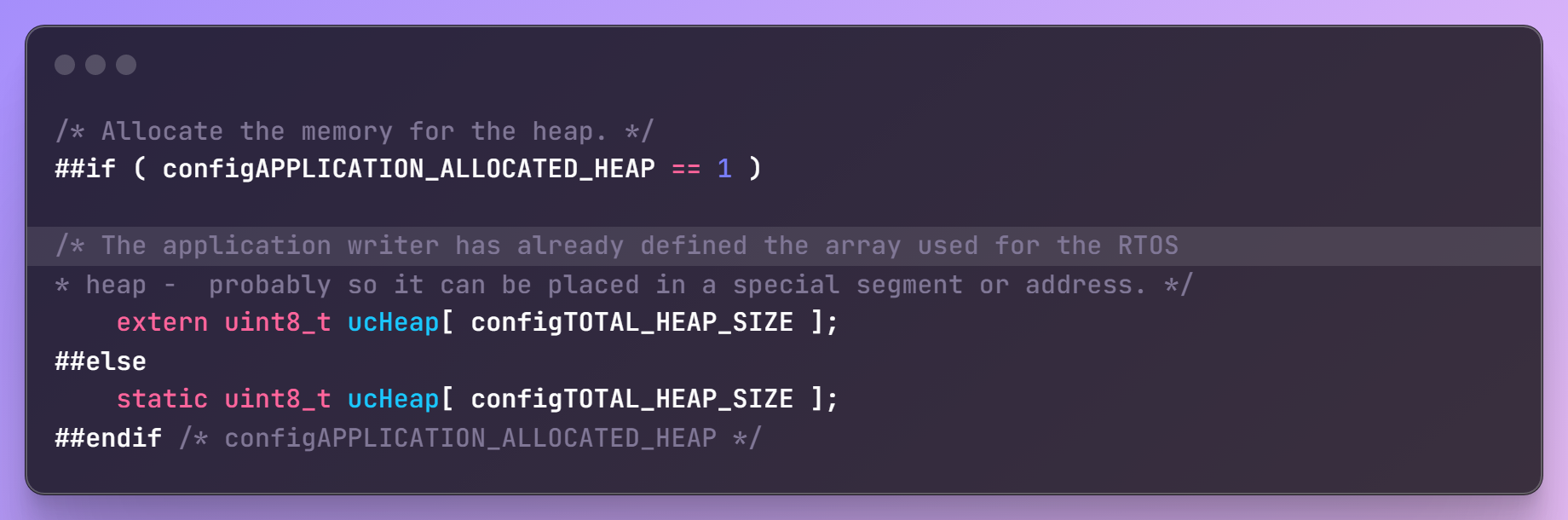
然后,对于pvPortMalloc调用时,从这个数组中分配空间。
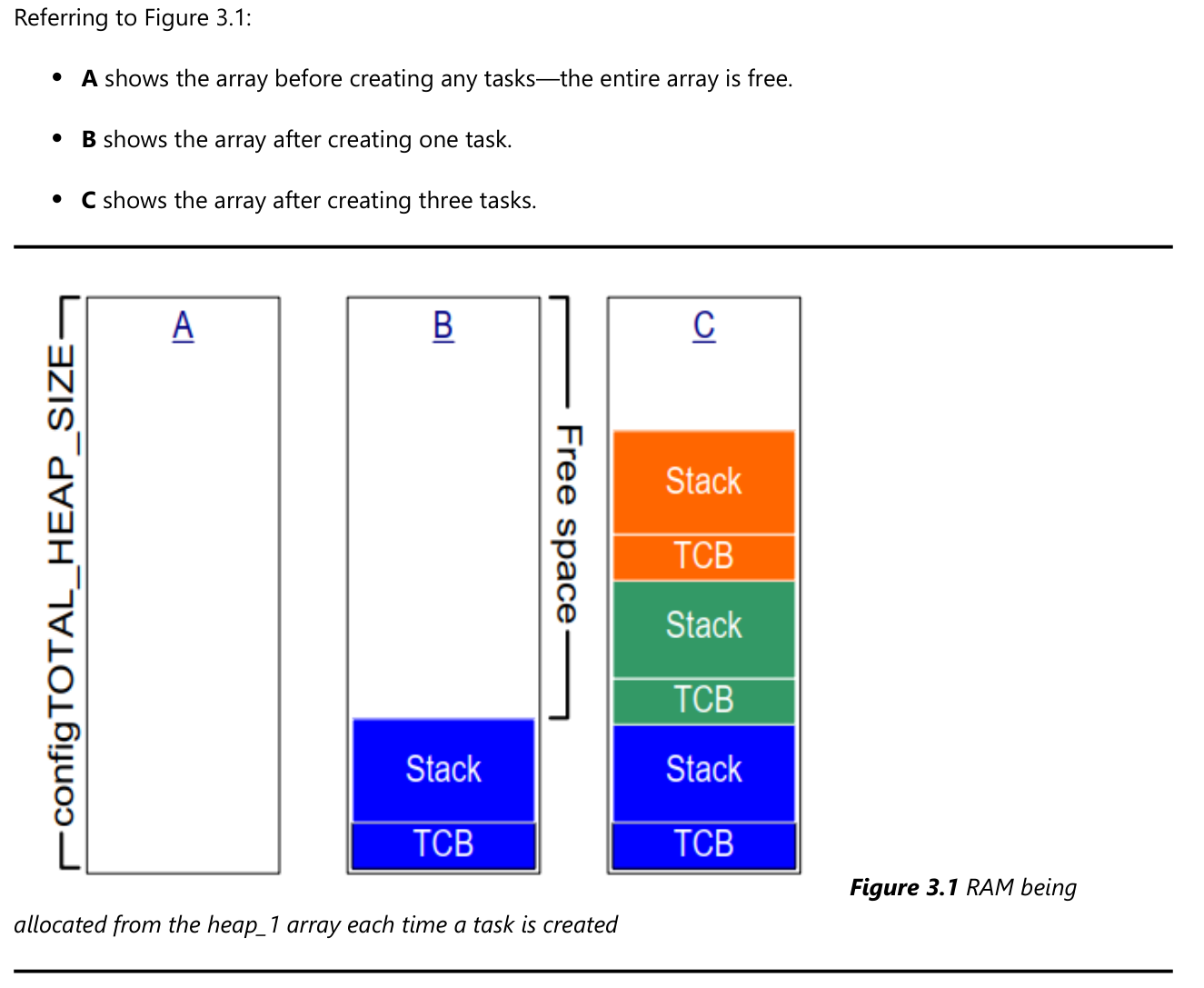
FreeRTOS在创建任务时,需要2个内核对象:task control block(TCB)、stack。 使用heap_1时,内存分配过程如下图所示:
- A:创建任务之前整个数组都是空闲的
- B:创建第1个任务之后,蓝色区域被分配出去了
- C:创建3个任务之后的数组使用情况
heap_2
Heap_2之所以还保留,只是为了兼容以前的代码。新设计中不再推荐使用Heap_2。建议使用Heap_4来替代Heap_2,更加高效。
Heap_2也是在数组上分配内存,跟Heap_1不一样的地方在于:
- Heap_2使用**最佳匹配算法(best fit)**来分配内存
- 它支持vPortFree
最佳匹配算法:
- 假设heap有3块空闲内存:5字节、25字节、100字节
- pvPortMalloc想申请20字节
- 找出最小的、能满足pvPortMalloc的内存:25字节
- 把它划分为20字节、5字节
- 返回这20字节的地址
- 剩下的5字节仍然是空闲状态,留给后续的pvPortMalloc使用
与Heap_4相比,Heap_2不会合并相邻的空闲内存,所以Heap_2会导致严重的"碎片化"问题。
但是,如果申请、分配内存时大小总是相同的,这类场景下Heap_2没有碎片化的问题。所以它适合这种场景:频繁地创建、删除任务,但是任务的栈大小都是相同的(创建任务时,需要分配TCB和栈,TCB总是一样的)。
虽然不再推荐使用heap_2,但是它的效率还是远高于malloc、free。
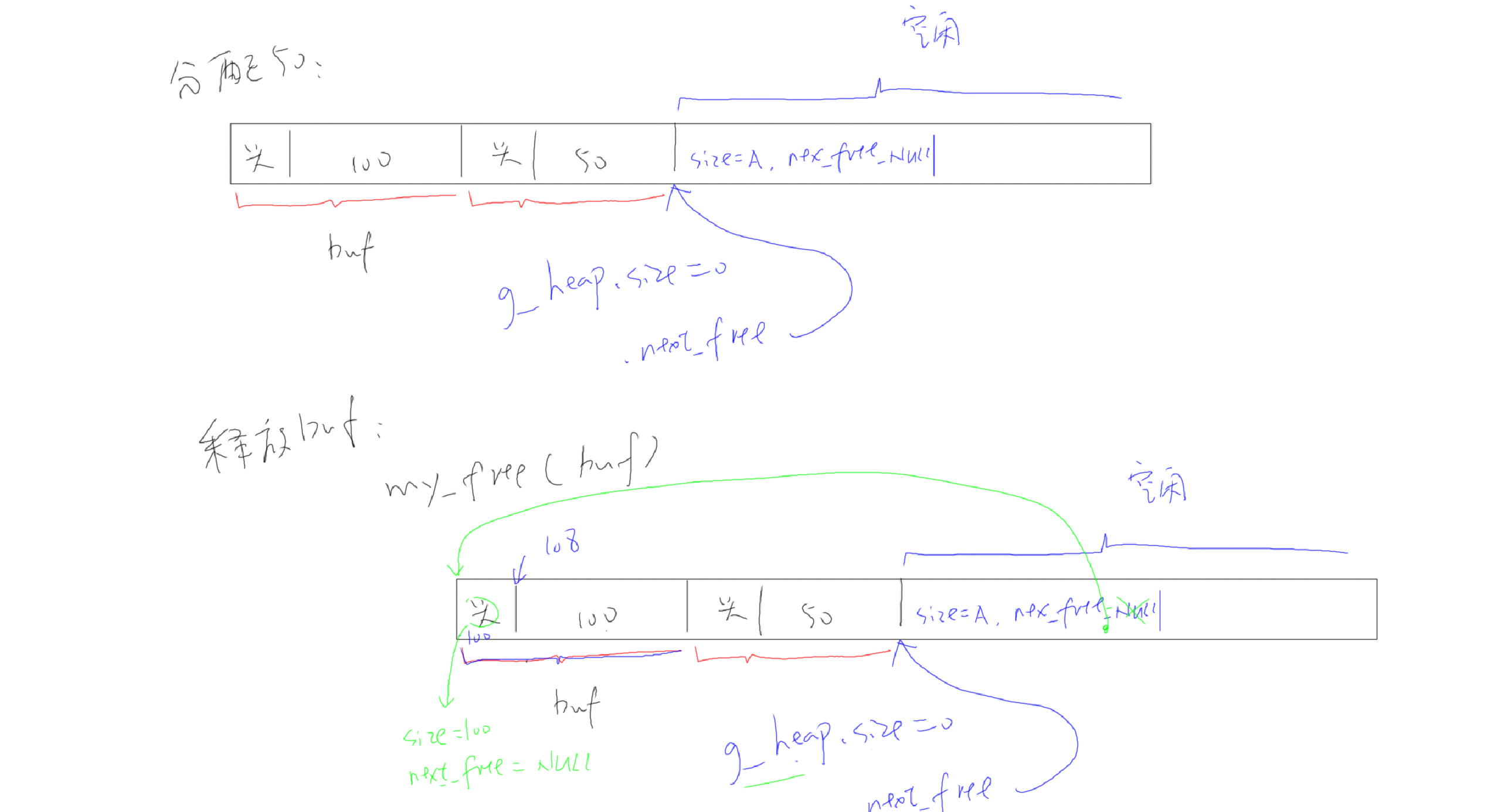
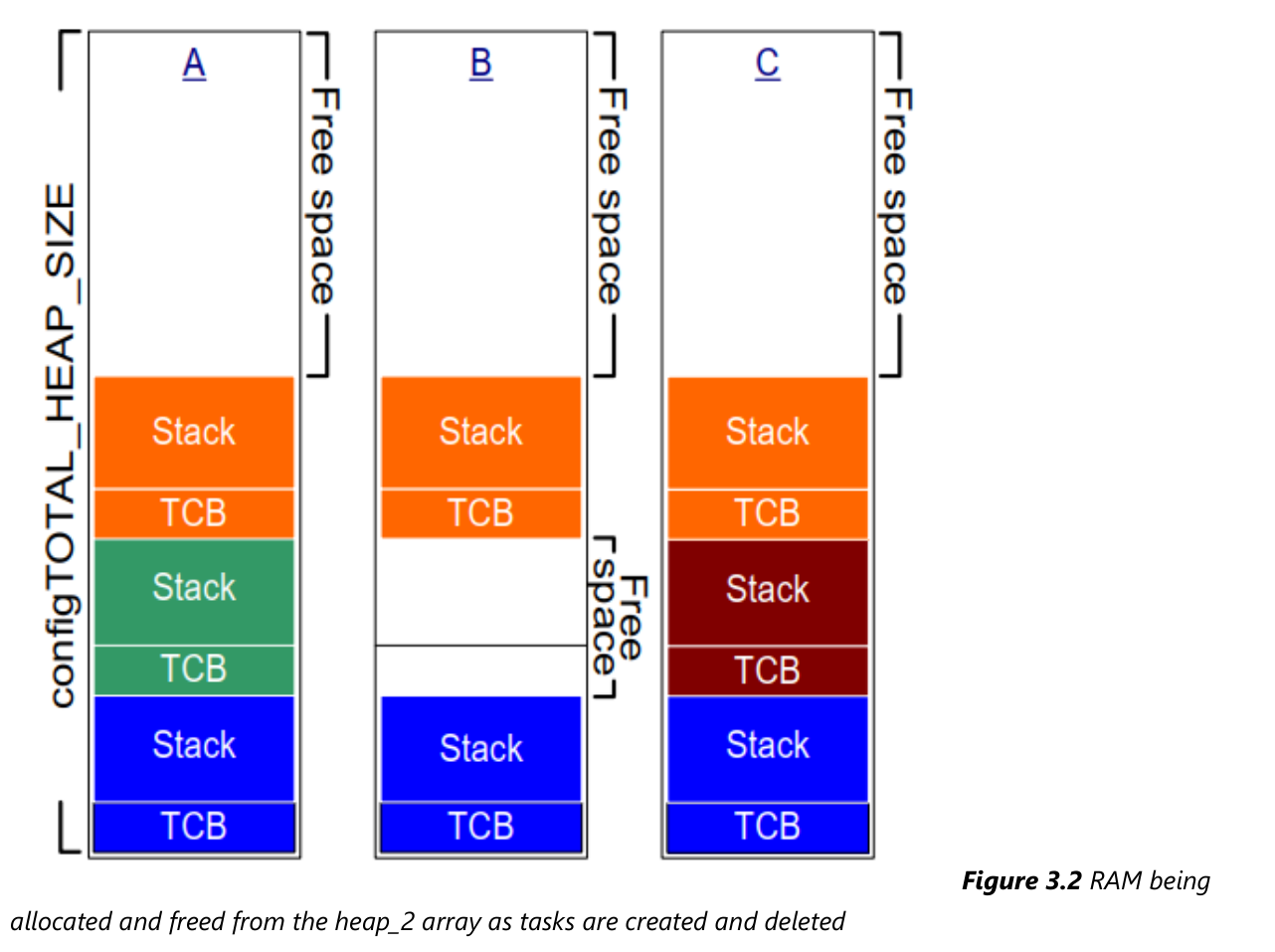
使用heap_2时,内存分配过程如下图所示:
- A:创建了3个任务
- B:删除了一个任务,空闲内存有3部分:顶层的、被删除任务的TCB空间、被删除任务的Stack空间
- C:创建了一个新任务,因为TCB、栈大小跟前面被删除任务的TCB、栈大小一致,所以刚好分配到原来的内存
heap_3
Heap_3使用标准C库里的malloc、free函数,所以堆大小由链接器的配置决定,配置项configTOTAL_HEAP_SIZE不再起作用。
C库里的malloc、free函数并非线程安全的,Heap_3中先暂停FreeRTOS的调度器,再去调用这些函数,使用这种方法实现了线程安全。
heap_4
跟Heap_1、Heap_2一样,Heap_4也是使用大数组来分配内存。
Heap_4使用 首次适应算法(first fit)来分配内存 。它还会把相邻的空闲内存合并为一个更大的空闲内存,这有助于较少内存的碎片问题。
首次适应算法:
- 假设堆中有3块空闲内存:5字节、200字节、100字节
- pvPortMalloc想申请20字节
- 找出第1个能满足pvPortMalloc的内存:200字节
- 把它划分为20字节、180字节
- 返回这20字节的地址
- 剩下的180字节仍然是空闲状态,留给后续的pvPortMalloc使用
Heap_4会把相邻空闲内存合并为一个大的空闲内存,可以较少内存的碎片化问题。适用于这种场景:频繁地分配、释放不同大小的内存。
Heap_4的使用过程举例如下:
- A:创建了3个任务
- B:删除了一个任务,空闲内存有2部分:
- 顶层的
- 被删除任务的TCB空间、被删除任务的Stack空间合并起来的
- C:分配了一个Queue,从第1个空闲块中分配空间
- D:分配了一个User数据,从Queue之后的空闲块中分配
- E:释放的Queue,User前后都有一块空闲内存
- F:释放了User数据,User前后的内存、User本身占据的内存,合并为一个大的空闲内存

heap_5
Heap_5分配内存、释放内存的算法跟Heap_4是一样的。
相比于Heap_4,Heap_5并不局限于管理一个大数组:它可以管理多块、分隔开的内存。
在嵌入式系统中,内存的地址可能并不连续,这种场景下可以使用Heap_5。
既然内存是分隔开的,那么就需要进行初始化:确定这些内存块在哪、多大:
- 在使用
pvPortMalloc之前,必须先指定内存块的信息 - 使用
vPortDefineHeapRegions来指定这些信息
怎么指定一块内存?使用如下结构体:

怎么指定多块内存?使用一个HeapRegion_t数组,在这个数组中,低地址在前、高地址在后。 比如:

vPortDefineHeapRegions函数原型如下:

heap相关的函数
pvPortMalloc/vPortFree
函数原型:
void * pvPortMalloc( size_t xWantedSize );
void vPortFree( void * pv );作用:分配内存、释放内存。
如果分配内存不成功,则返回值为NULL。
xPortGetFreeHeapSize
函数原型:
size_t xPortGetFreeHeapSize( void );当前还有多少空闲内存,这函数可以用来优化内存的使用情况。比如当所有内核对象都分配好后,执行此函数返回2000,那么configTOTAL_HEAP_SIZE就可减小2000。
注意:在heap_3中无法使用。
xPortGetMinimumEverFreeHeapSize
函数原型:
size_t xPortGetMinimumEverFreeHeapSize( void );返回:程序运行过程中,空闲内存容量的最小值。
注意:只有heap_4、heap_5支持此函数。
malloc失败的钩子函数
在pvPortMalloc函数内部:
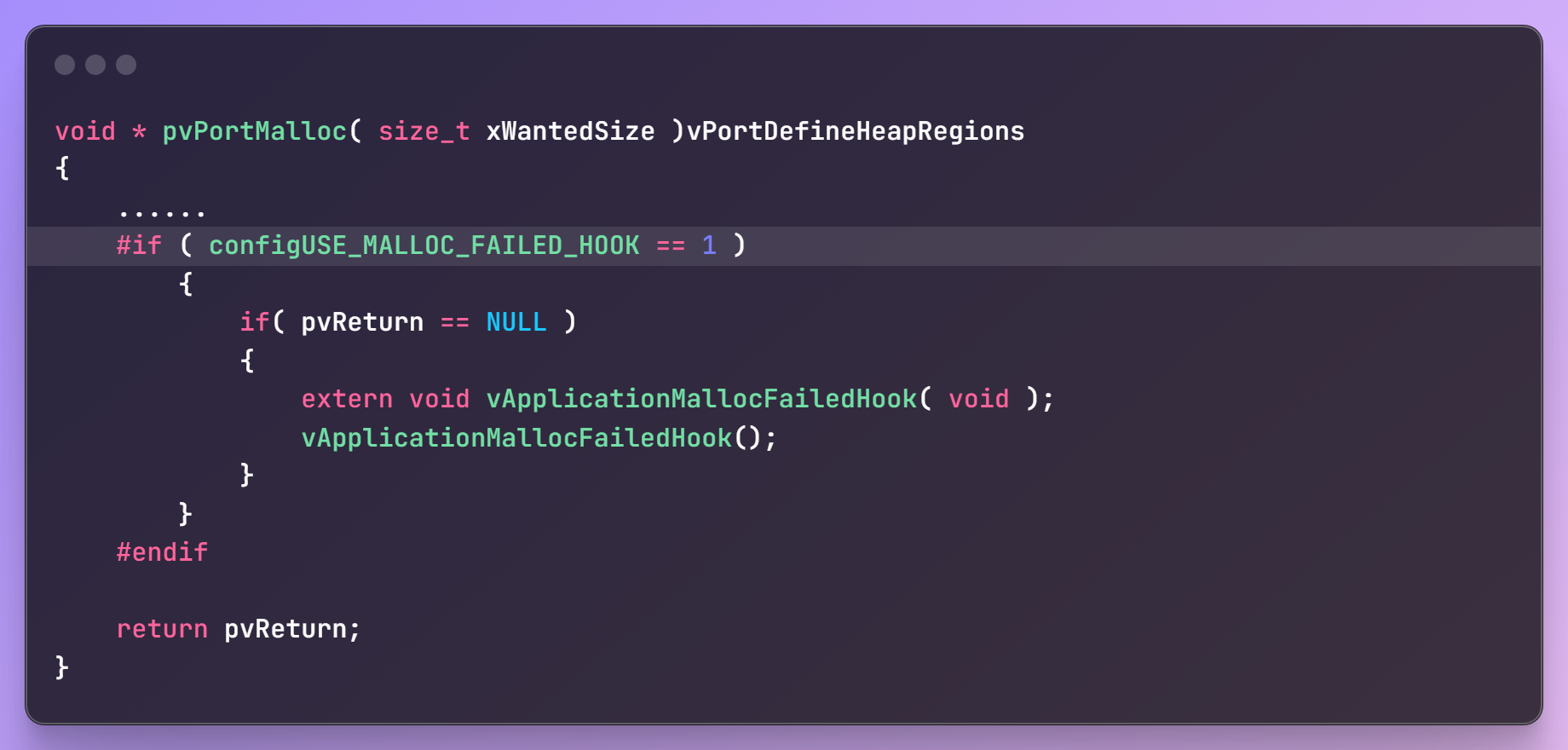
所以,如果想使用这个钩子函数:
- 在
FreeRTOSConfig.h中,把configUSE_MALLOC_FAILED_HOOK定义为1 - 提供
vApplicationMallocFailedHook函数 pvPortMalloc失败时,才会调用此函数
栈
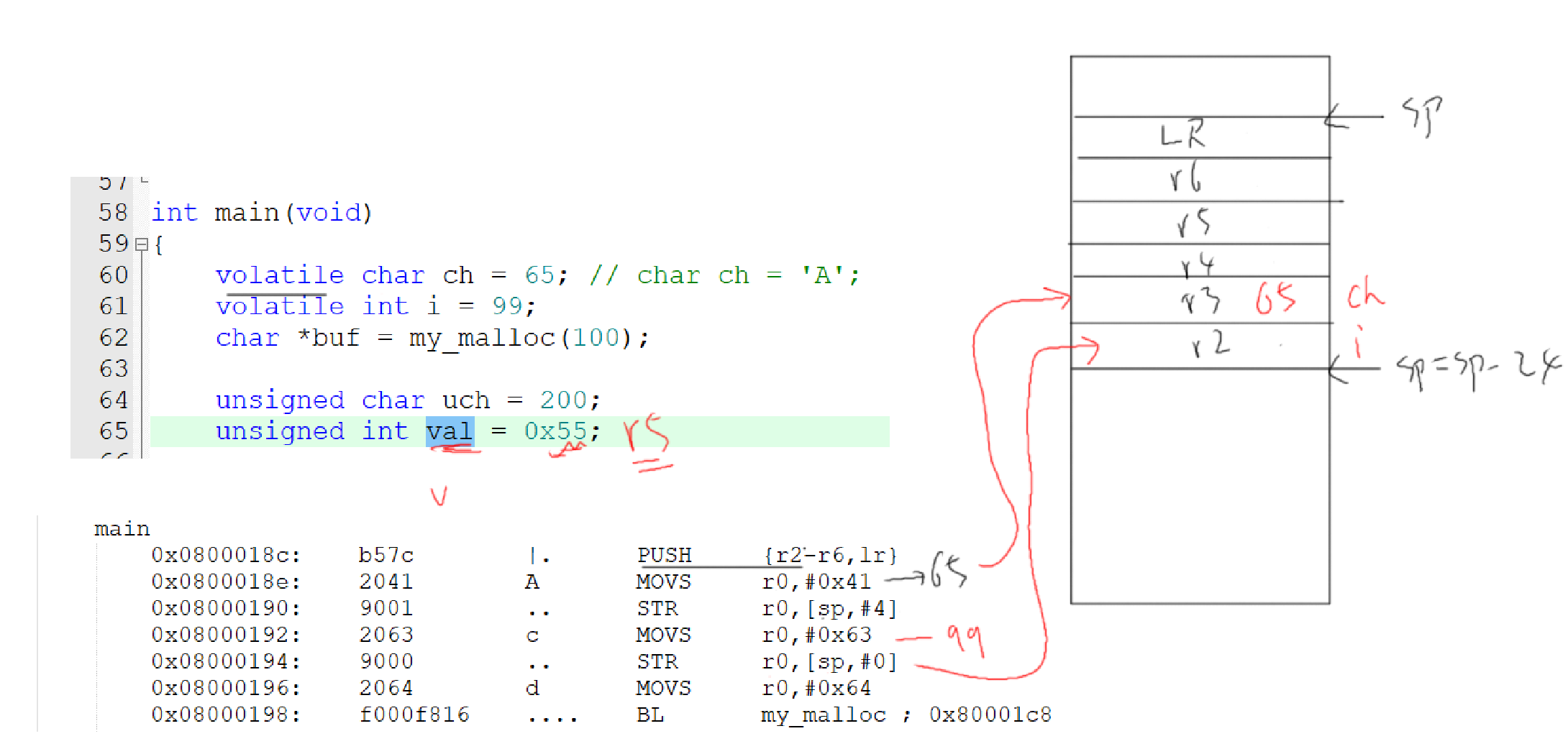
局部变量保存在栈里?如何体现?
- 编译器优化后,局部变量可能保存在Rn寄存器中
- 使用
volatile可以强制编译器从内存中读写变量

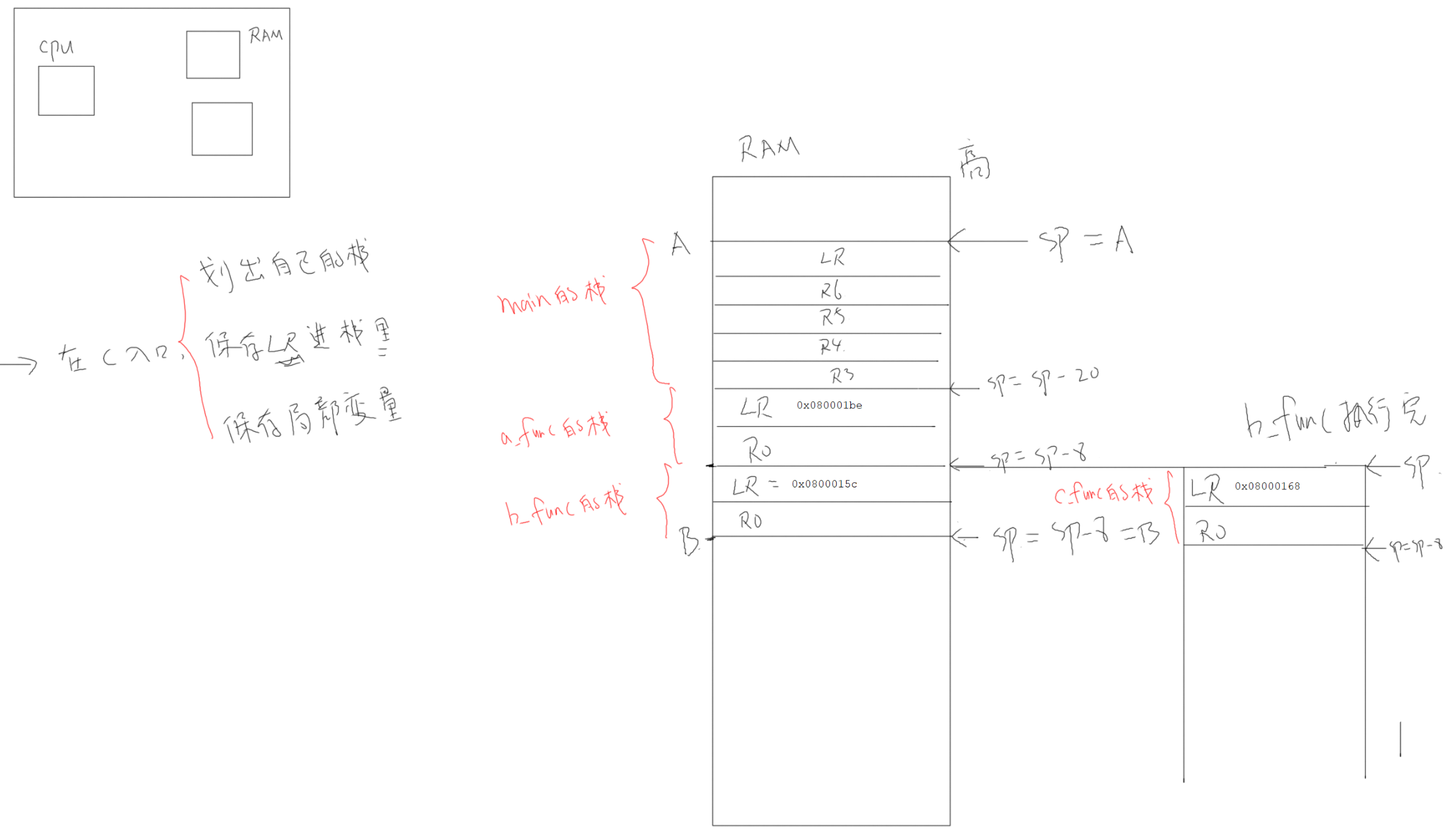
函数调用对应压栈/出栈?

为何每个任务要有自己的栈?
- 函数的调用关系/调用深度,调用者需要按需保护的寄存器:R0~R2、R12、LR、PSR
- 函数的局部变量
- 通用寄存器不够用时,局部变量在栈中分配
volatile变量在栈中分配
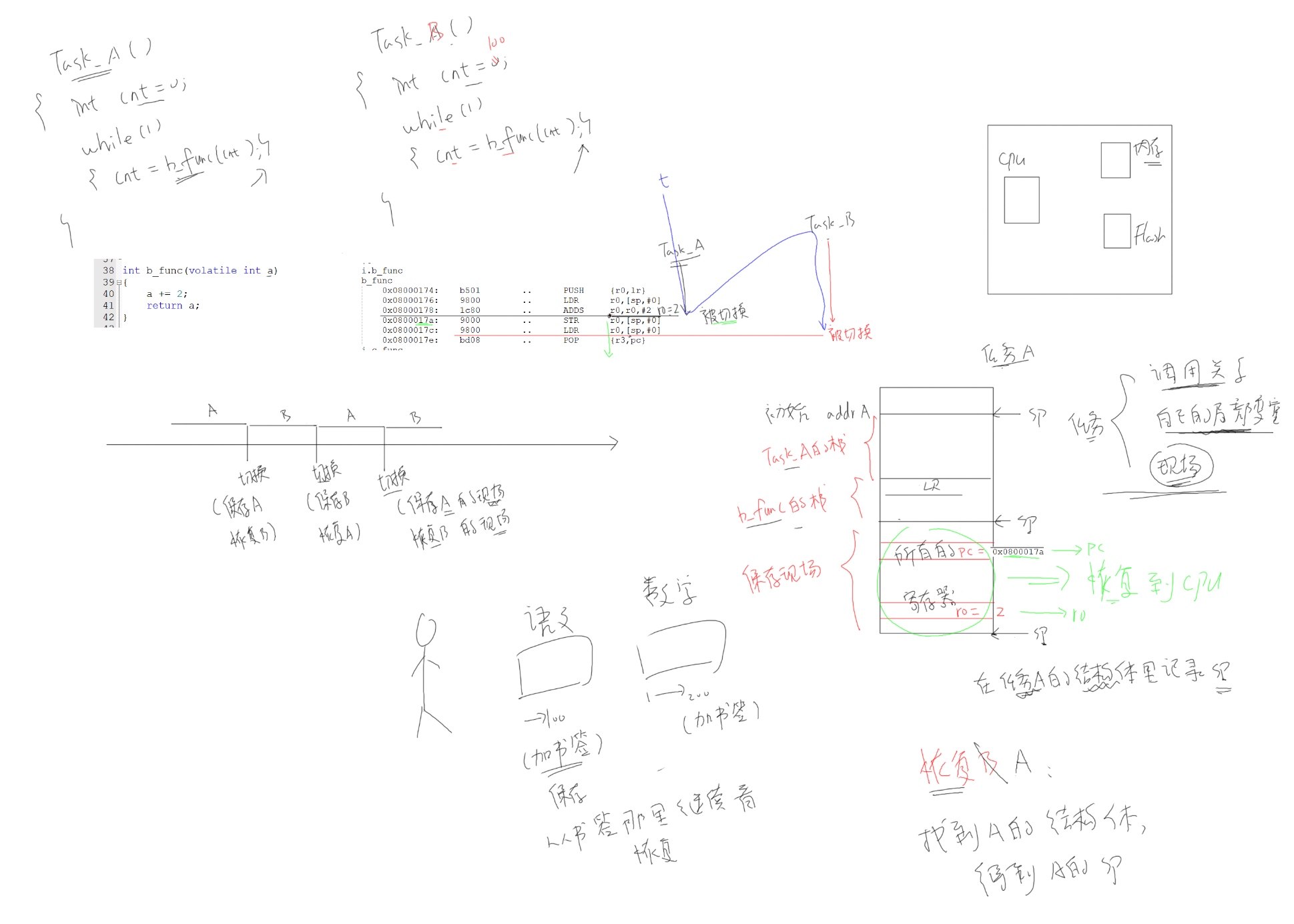
- 被切换前任务的执行现场
- 进入PendSV异常,在执行ISR之前,ARM架构异常机制会按照AAPCS标准保护调用者需要保存的寄存器:R0~R2、R12、LR、PSR、PC(这些都由硬件自动完成)
- FreeRTOS的
xPortPendSVHandler中,将剩余的R4~R11也都一并保存起来,这样任务的执行现场就都保存到任务的栈中了
任务管理
任务的创建
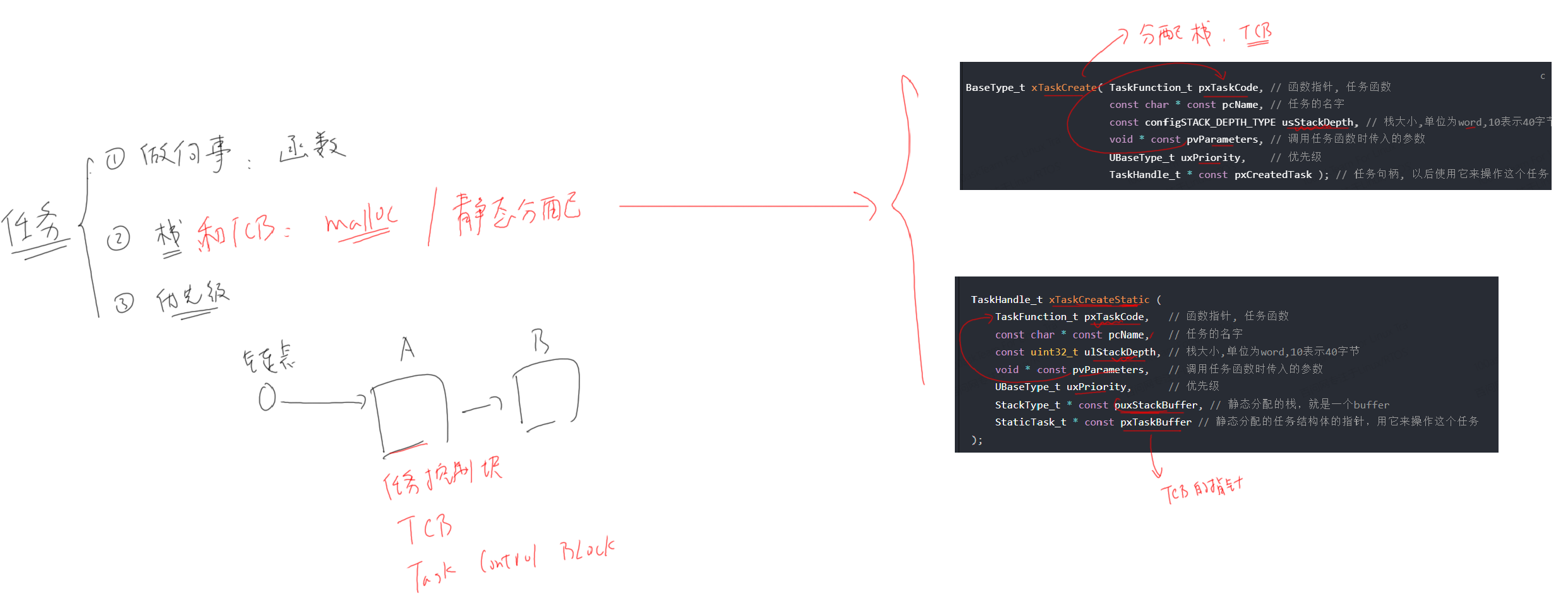
评估任务栈大小
- 函数调用链
- 每个调用方需要按照AAPCS按需保存自己所用到的R0~R3、R12、LR、PSR
- 每个函数的局部变量
- 任务执行现场
- 进入PendSV时由硬件保存:R0~R3、R12、LR、PSR、PC
- FreeRTOS的
xPortPendSVHandler保存:R4~R11


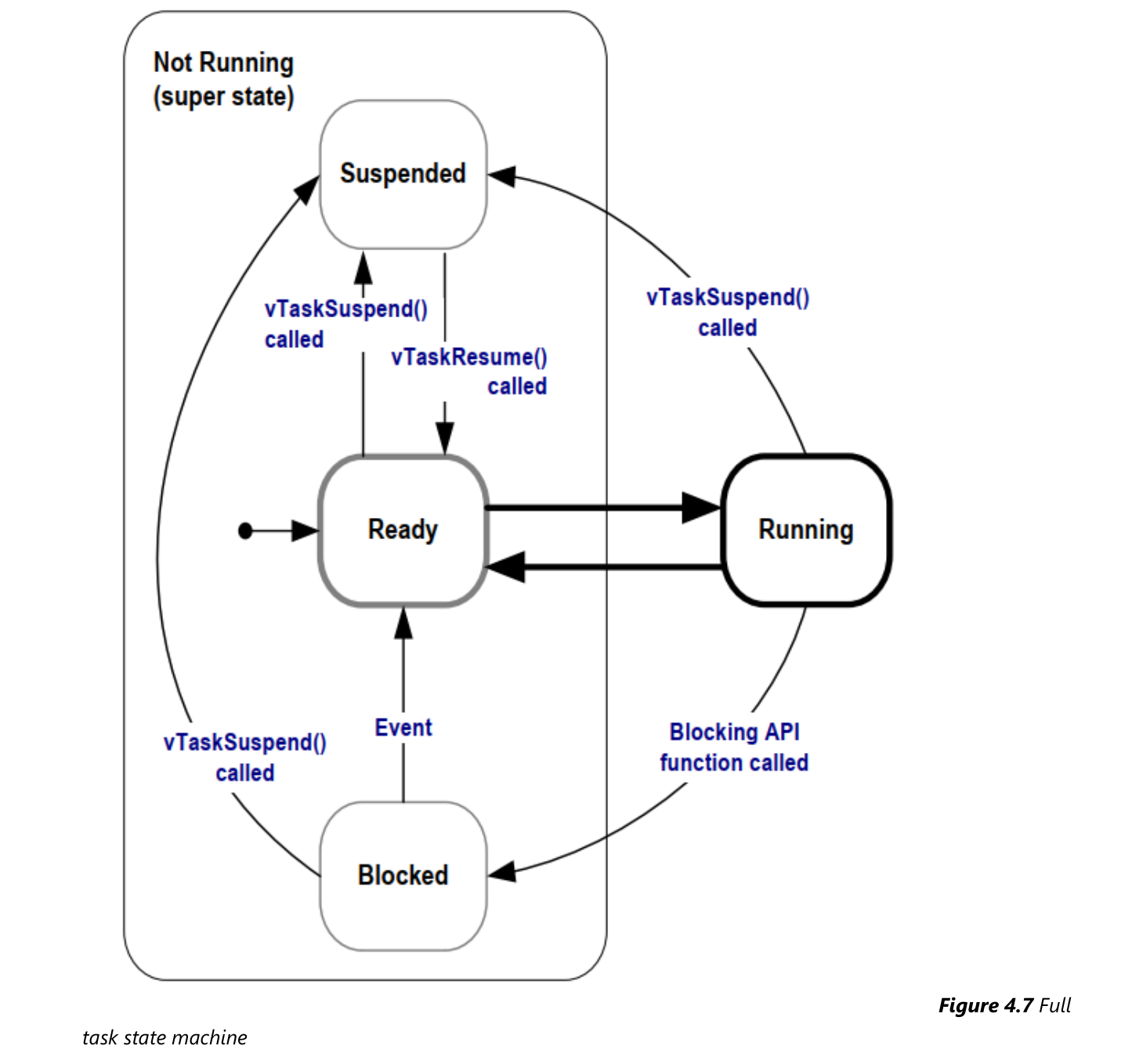
任务状态机
任务调度

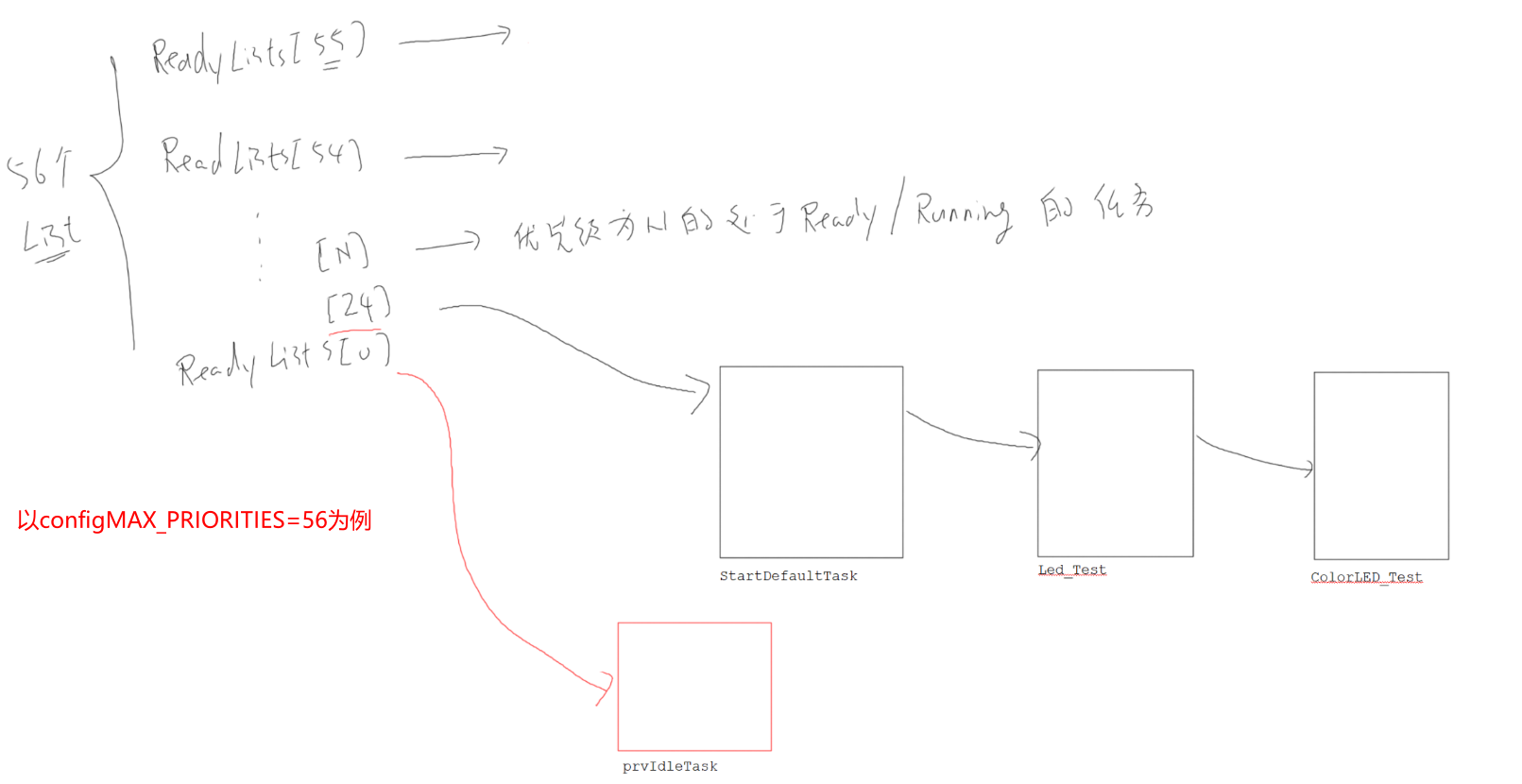
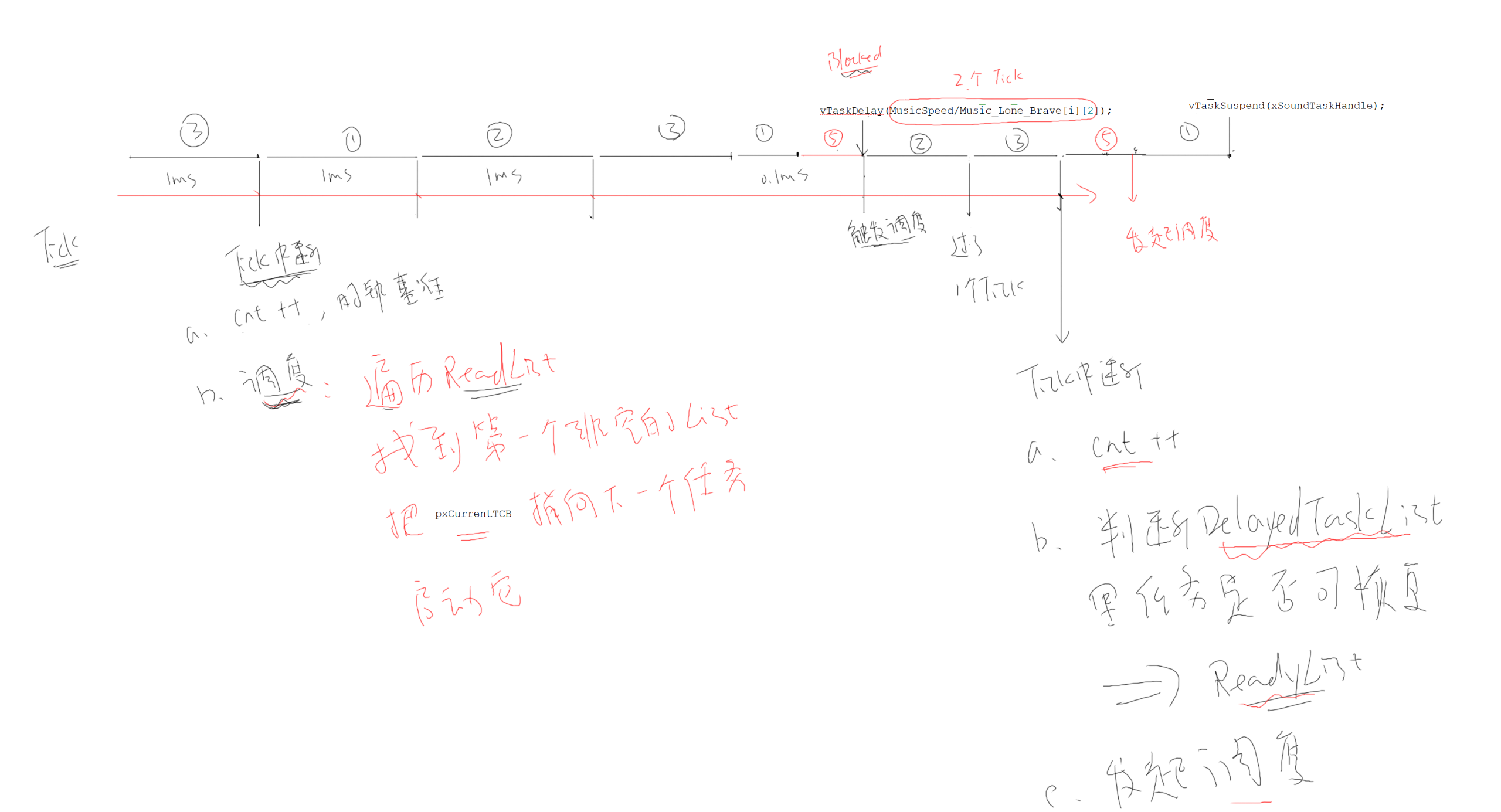
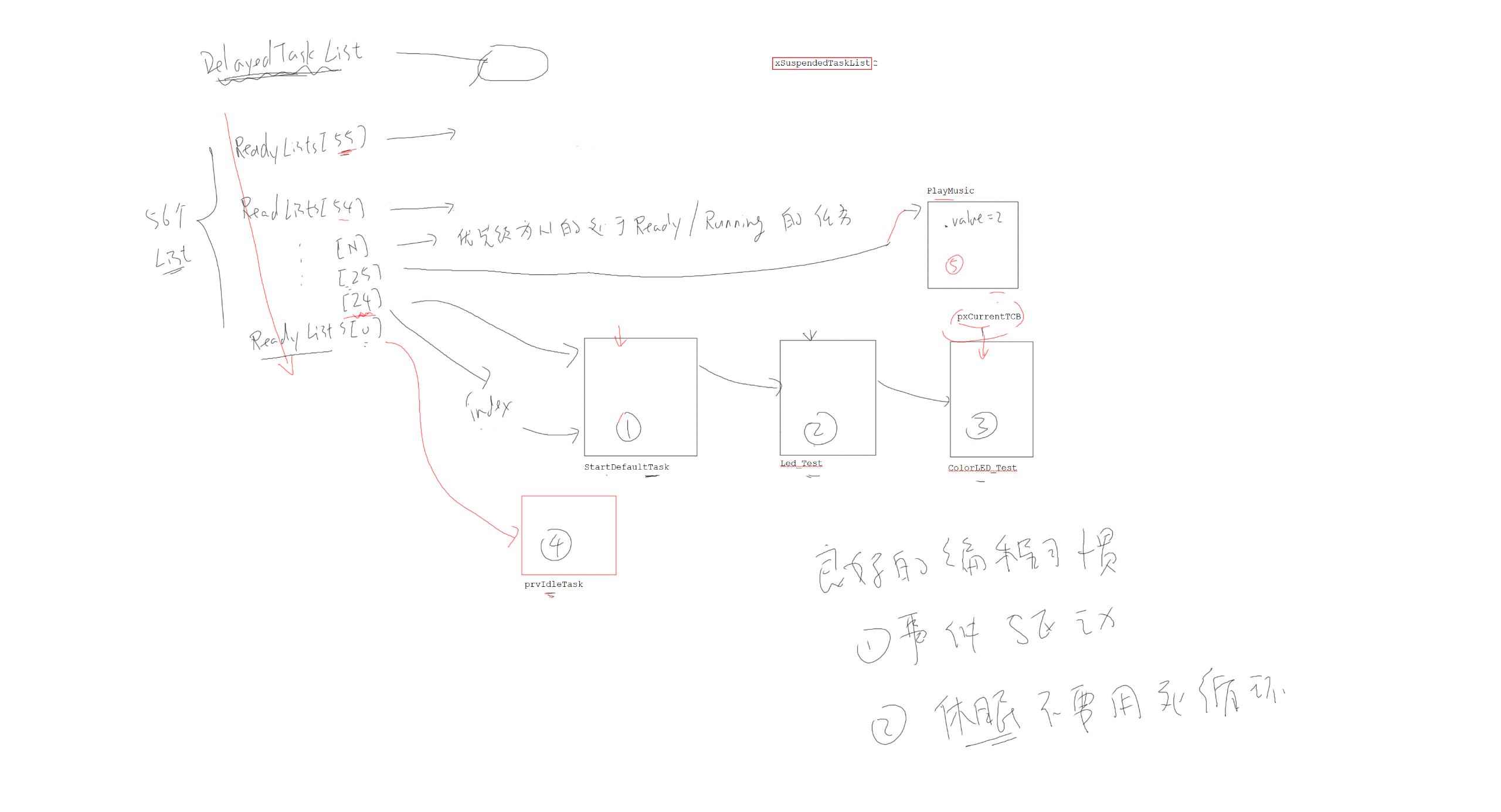
空闲任务 & 垃圾回收

两种延时
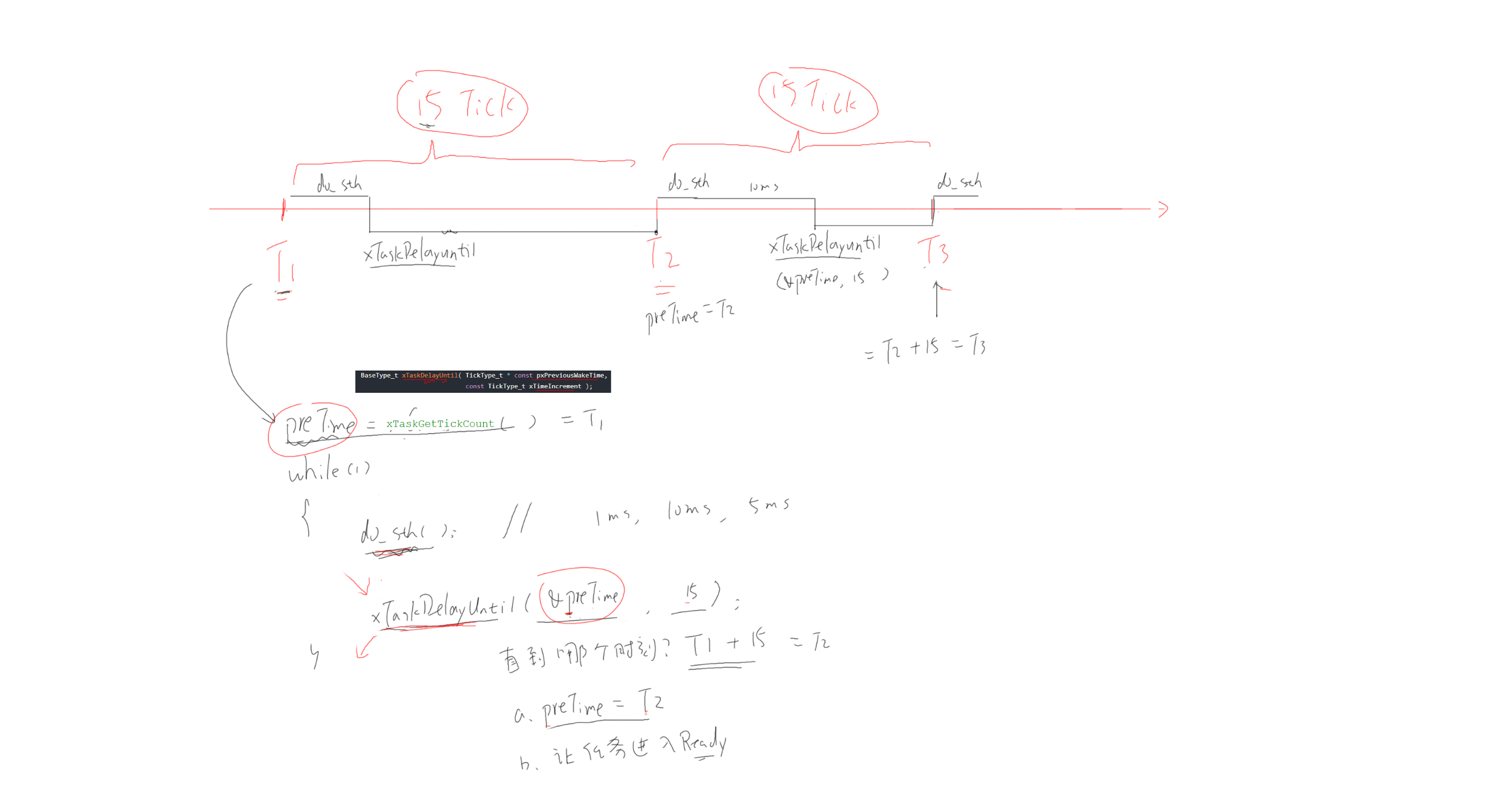
绝对延时
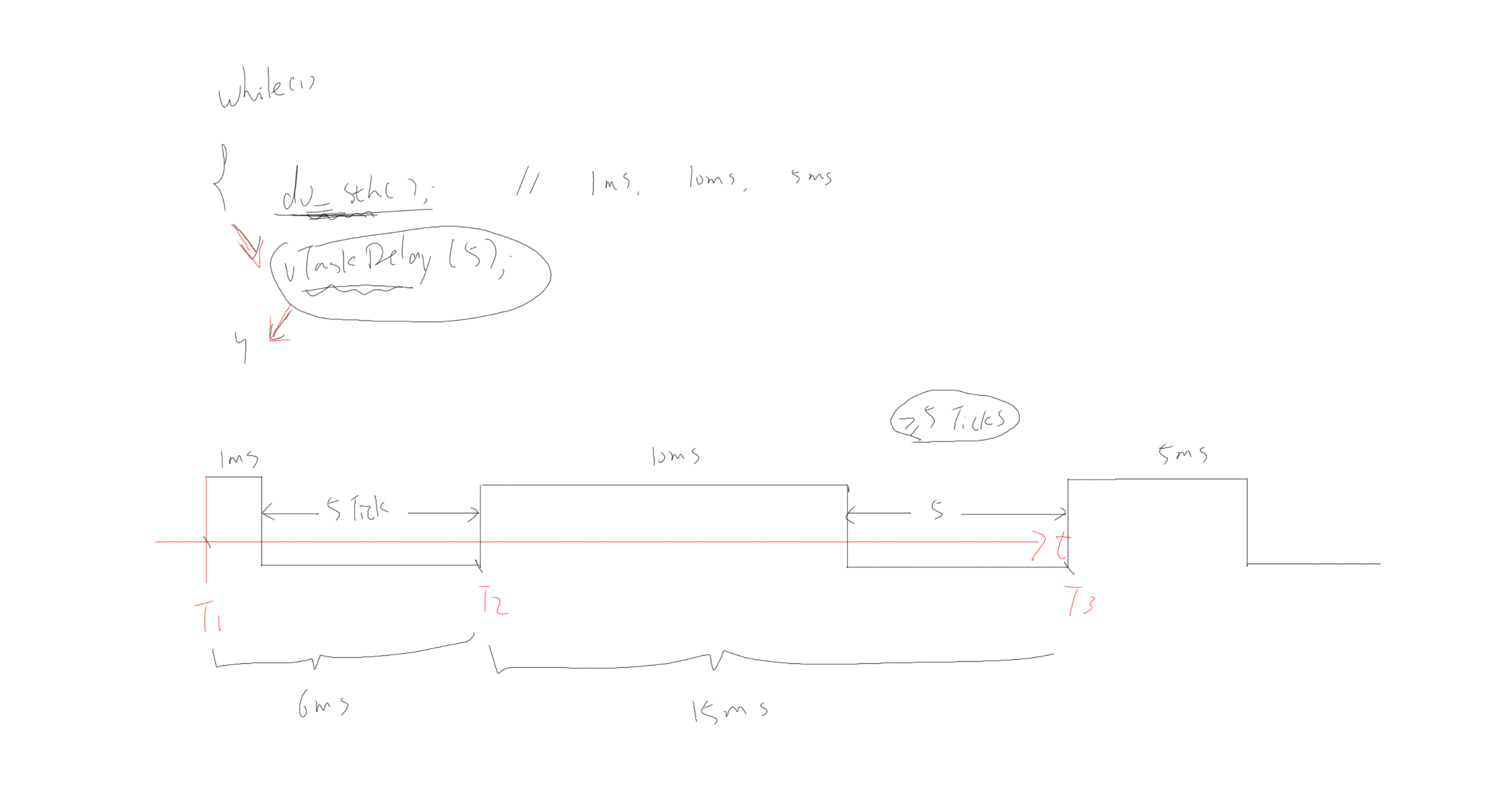
相对延时
任务间同步/互斥与通信
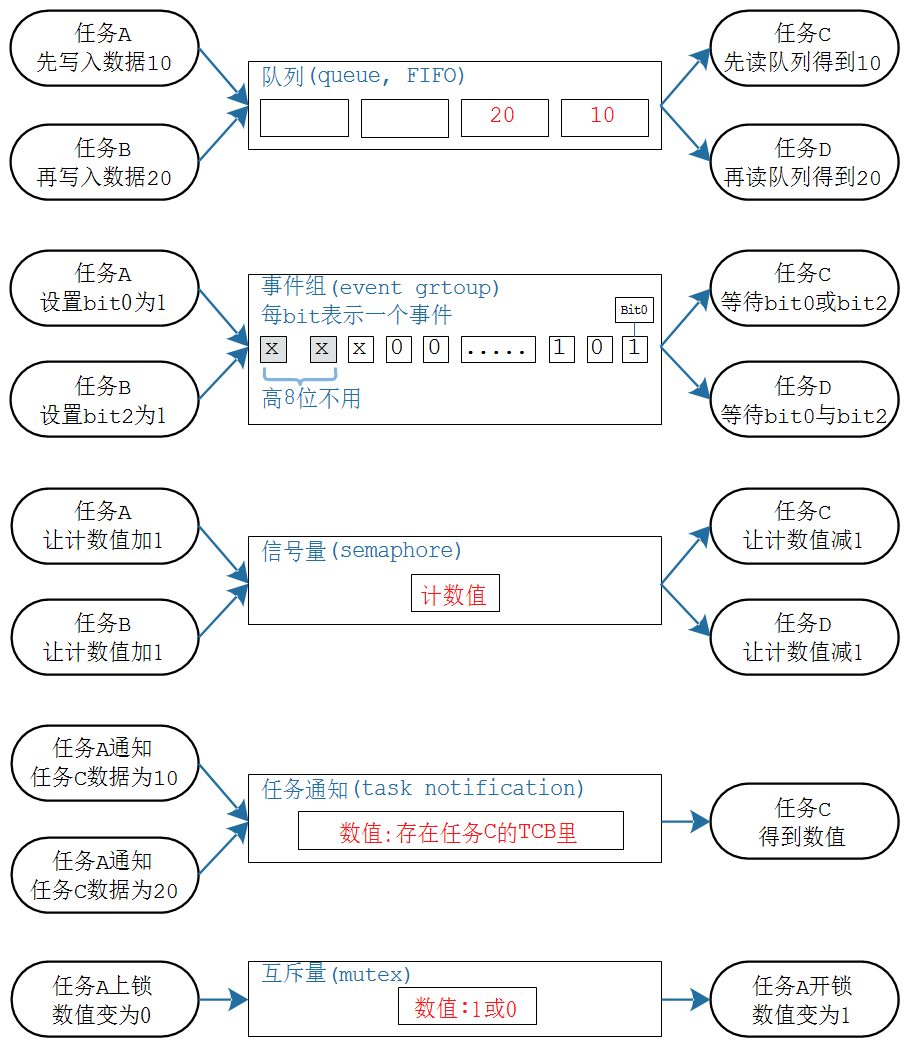
基于全局变量实现存在的问题
同步

互斥
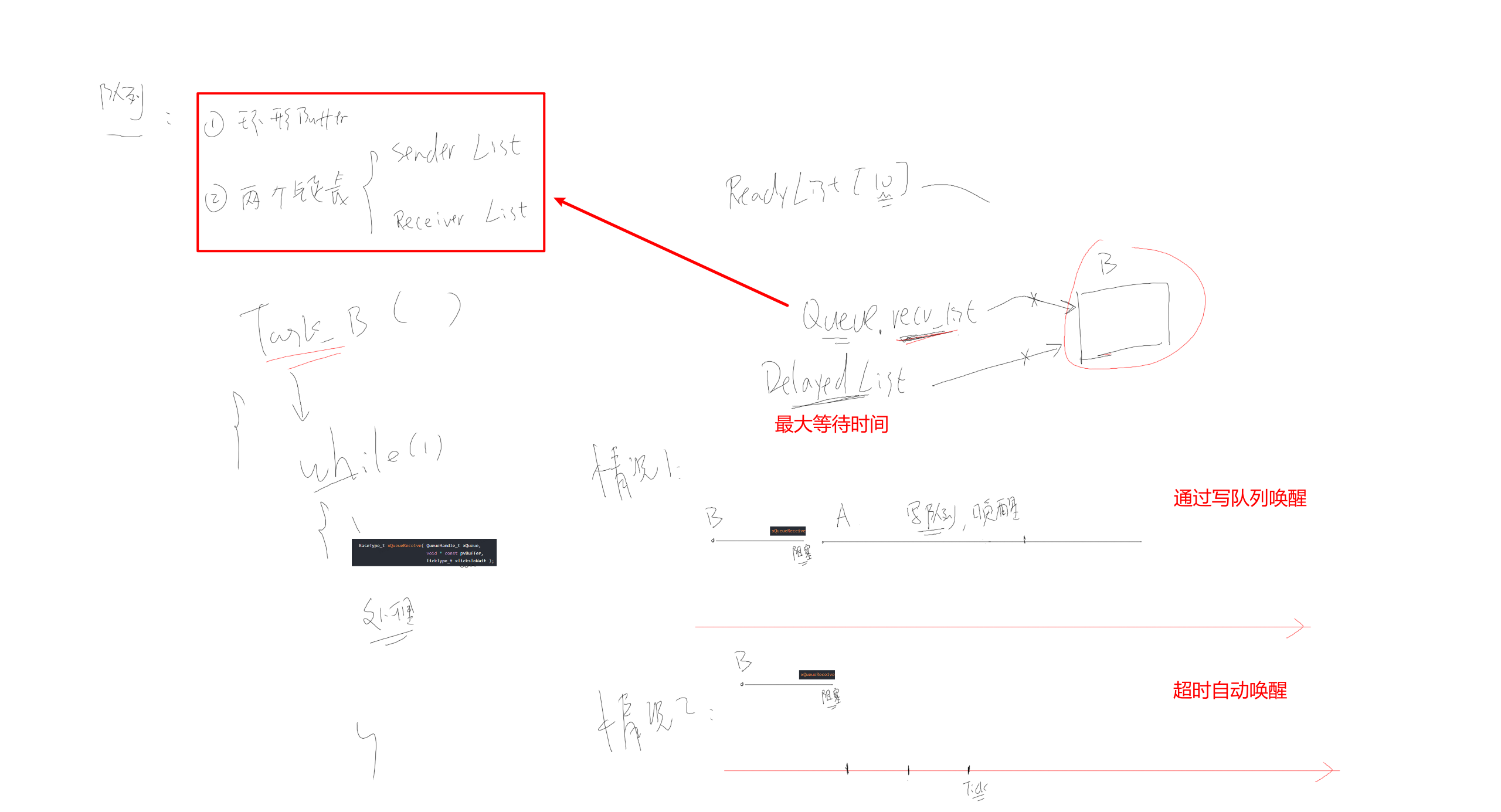
队列
任务之间如何传输数据
| 数据个数 | 互斥措施 | 阻塞-唤醒 | 使用场景 | |
|---|---|---|---|---|
| 全局变量 | 1 | 无 | 无 | 一读一写 |
| 环形缓冲区 | 多个 | 无 | 无 | 一读一写 |
| 队列 | 多个 | 有 | 有 | 多读多写 |
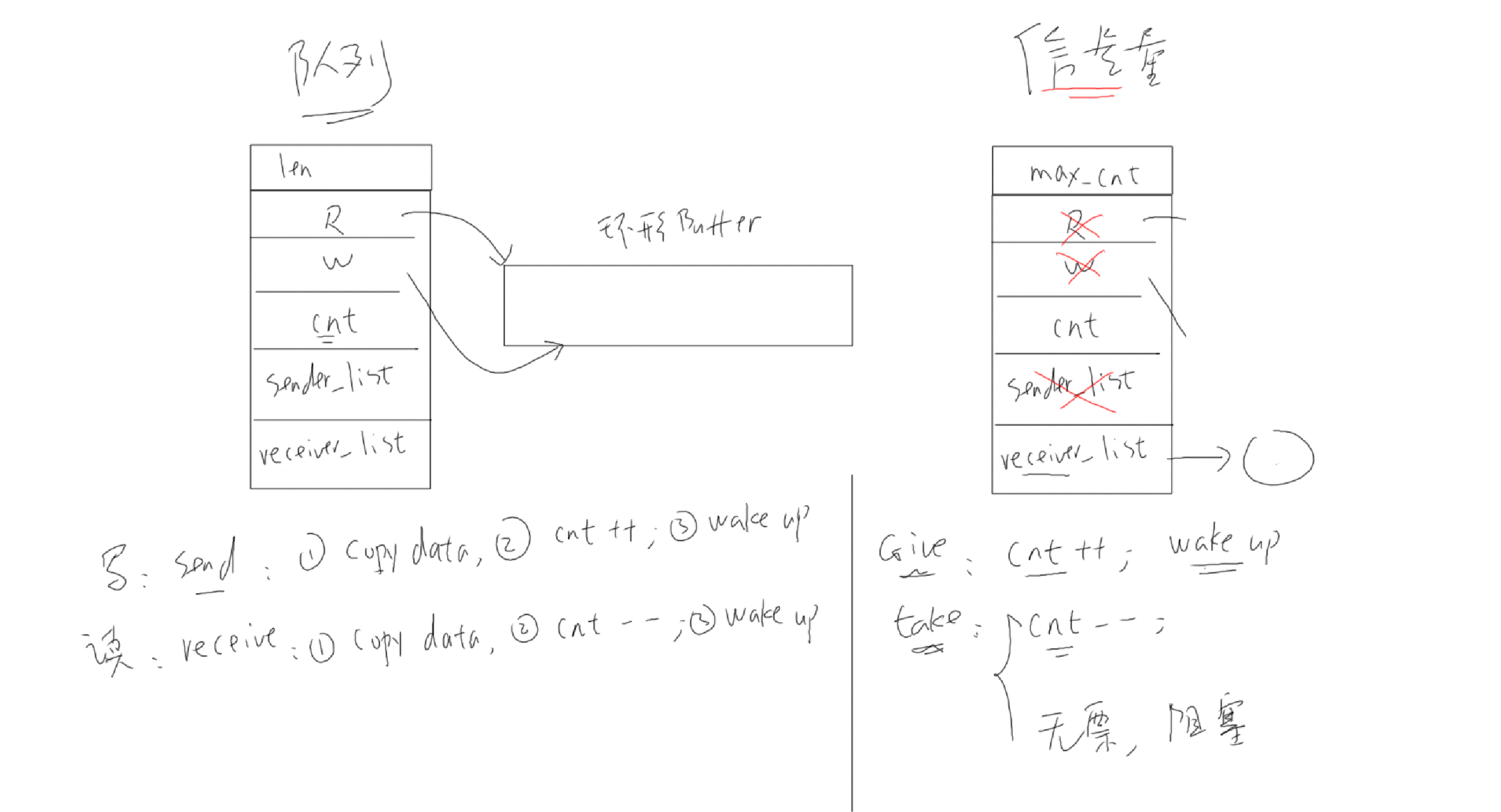
环形缓冲区
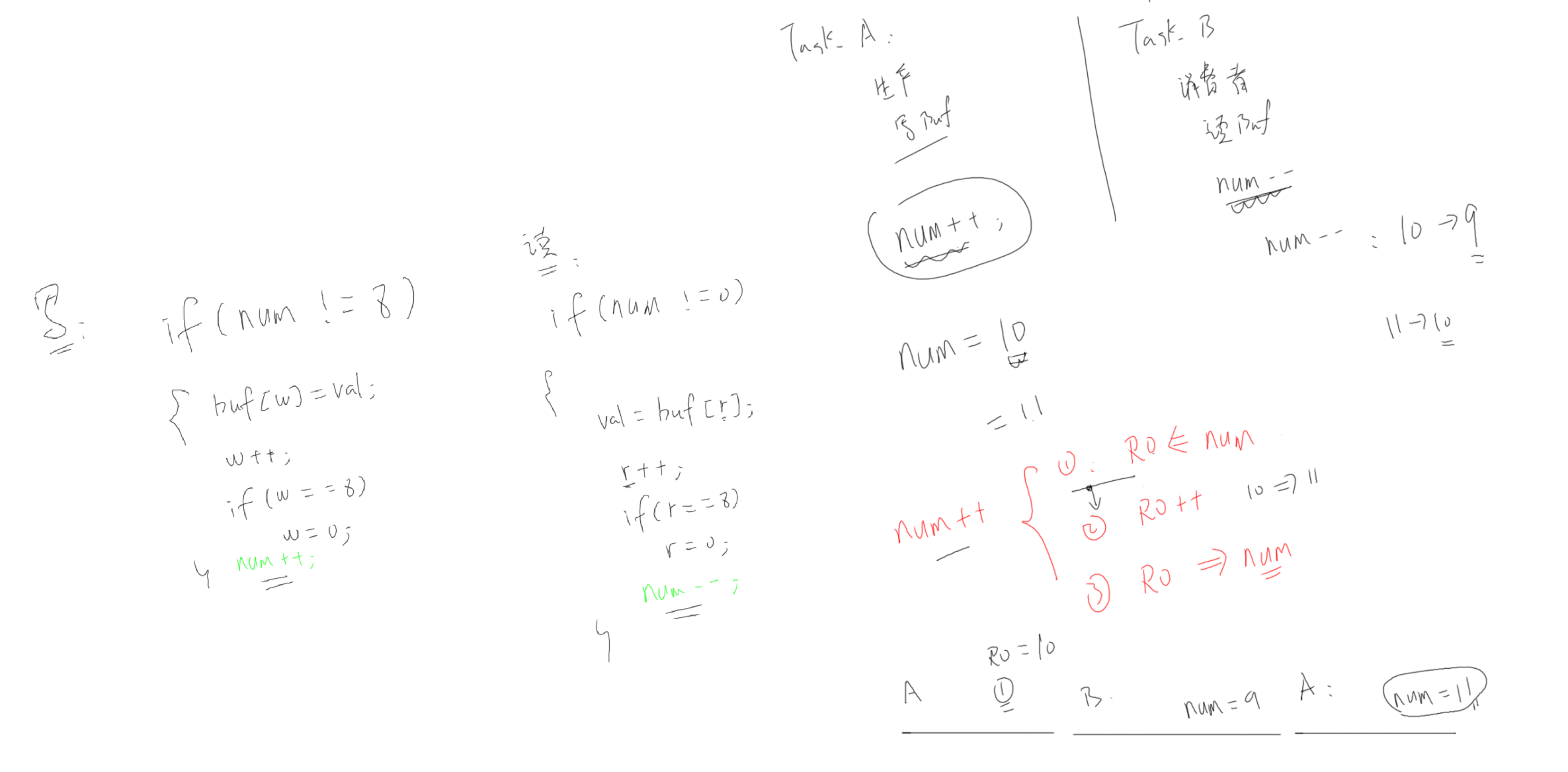
读写分离可以支持一个生产者和一个消费者同时访问,不会产生竞态条件:
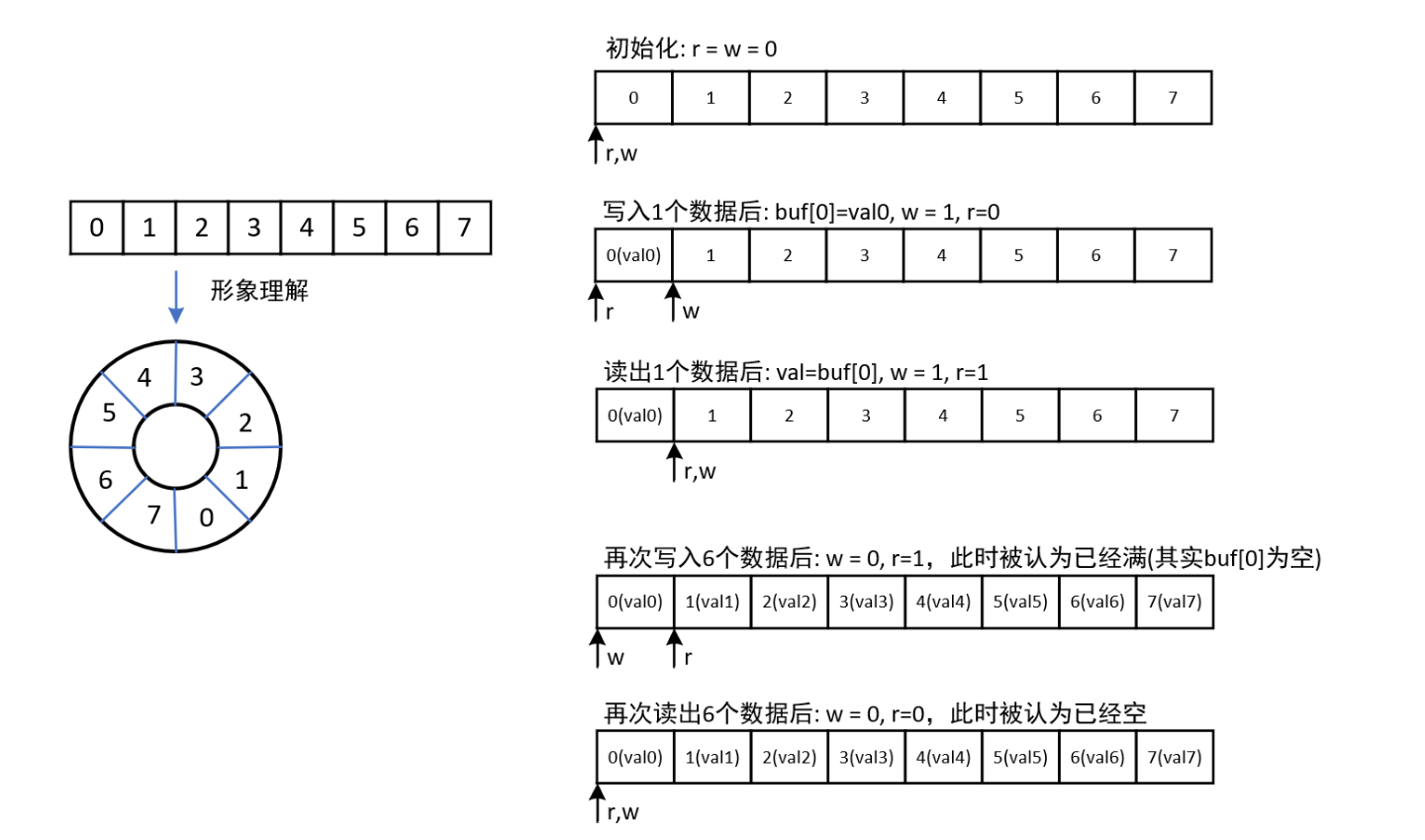
使用共享变量,例如缓冲区的数据数量 num则会产生竞态条件:
队列的本质
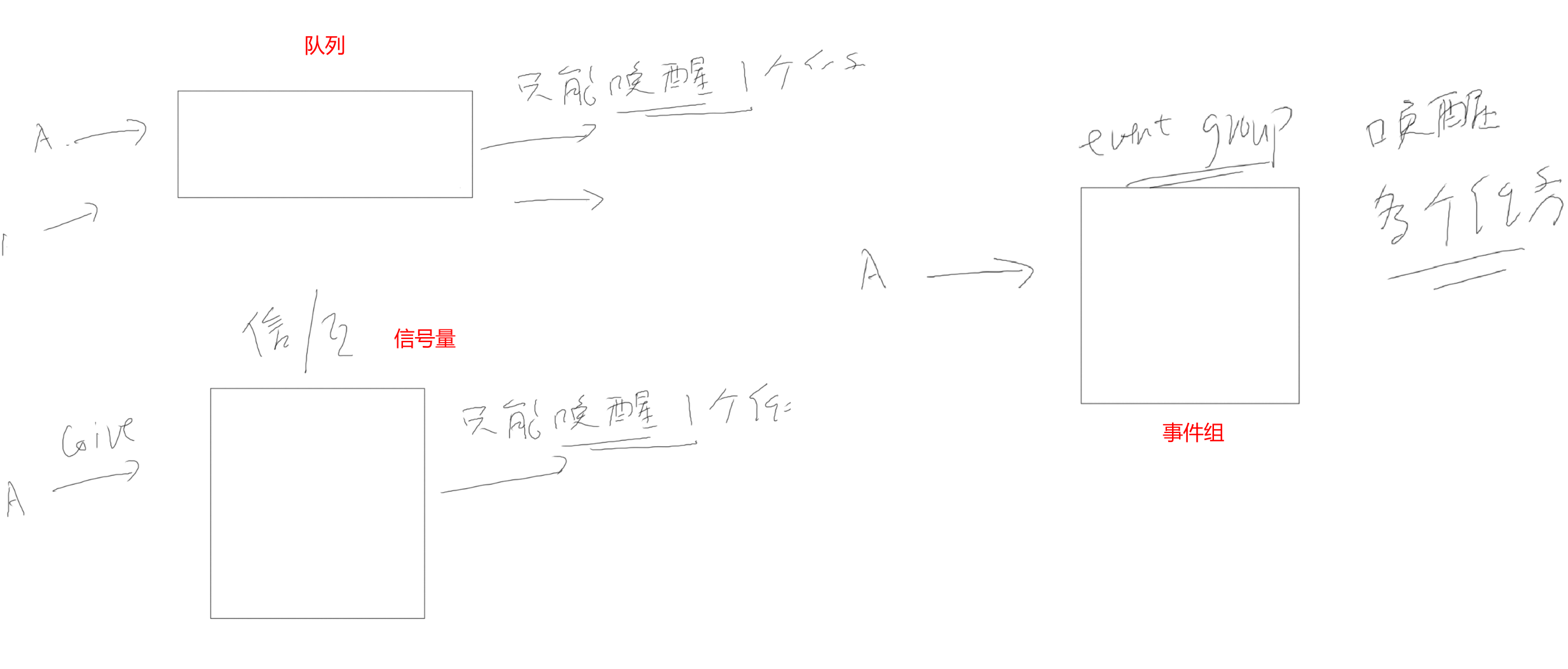
队列中,数据的读写本质就是环形缓冲区,在这个基础上增加了互斥措施、阻塞-唤醒机制。
如果这个队列不传输数据,只调整"数据个数",它就是信号量(semaphore)。
如果信号量中,限定"数据个数"最大值为1,它就是互斥量(mutex)。
使用队列实现控制翻转
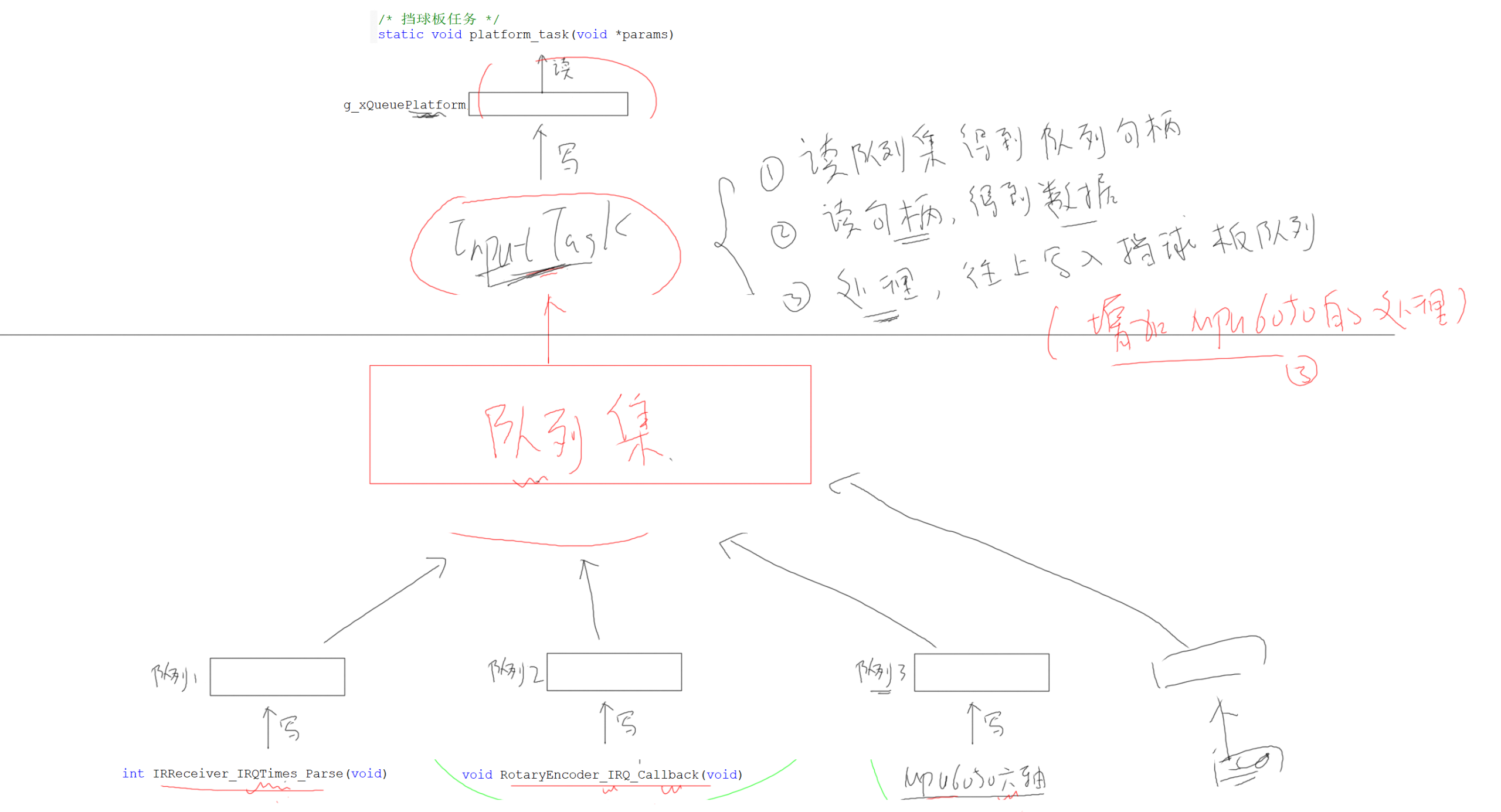
使用队列集整合不同的事件源

信号量/互斥量
信号量的本质
控制并发访问共享资源的数量
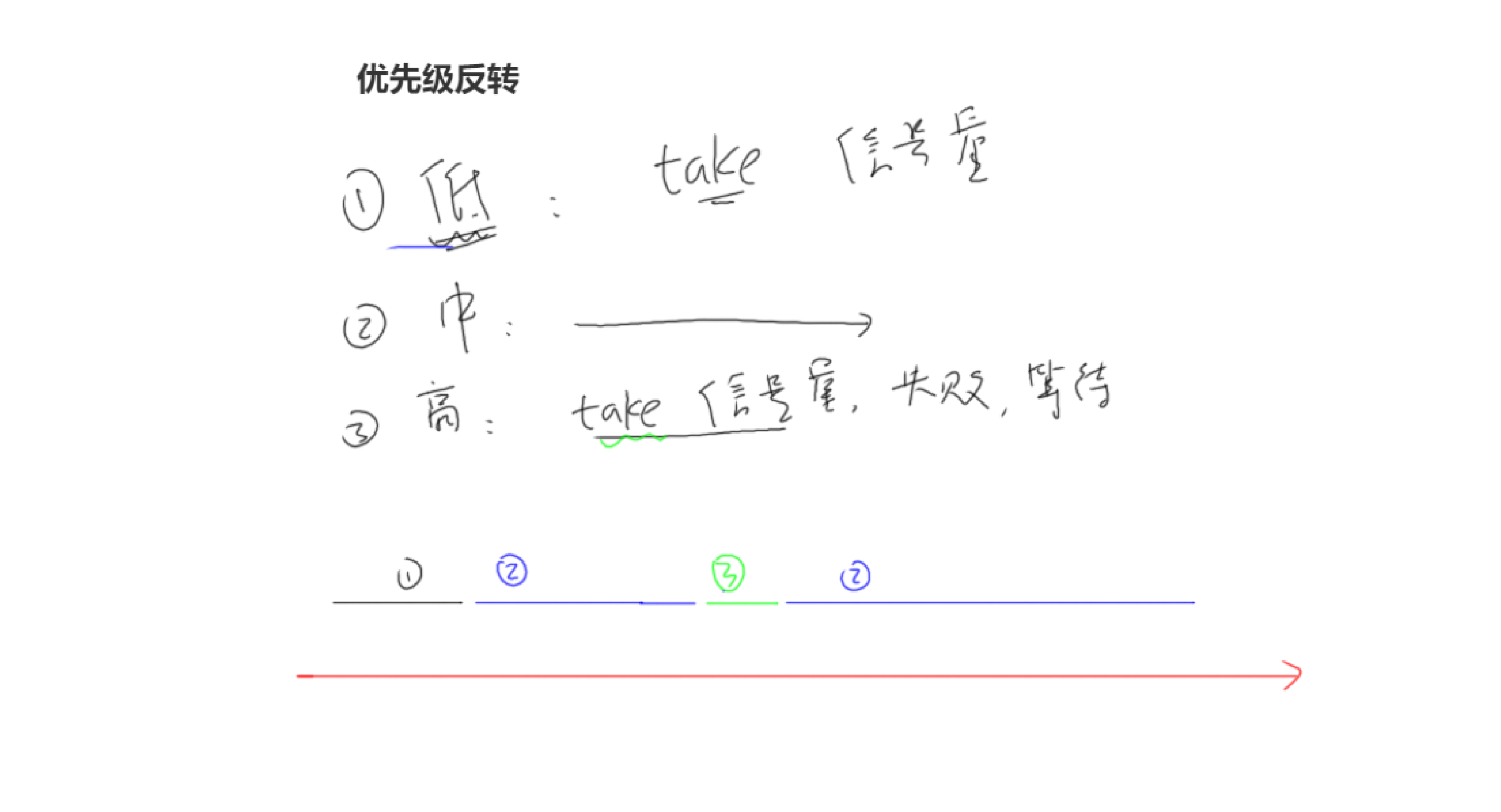
优先级翻转问题
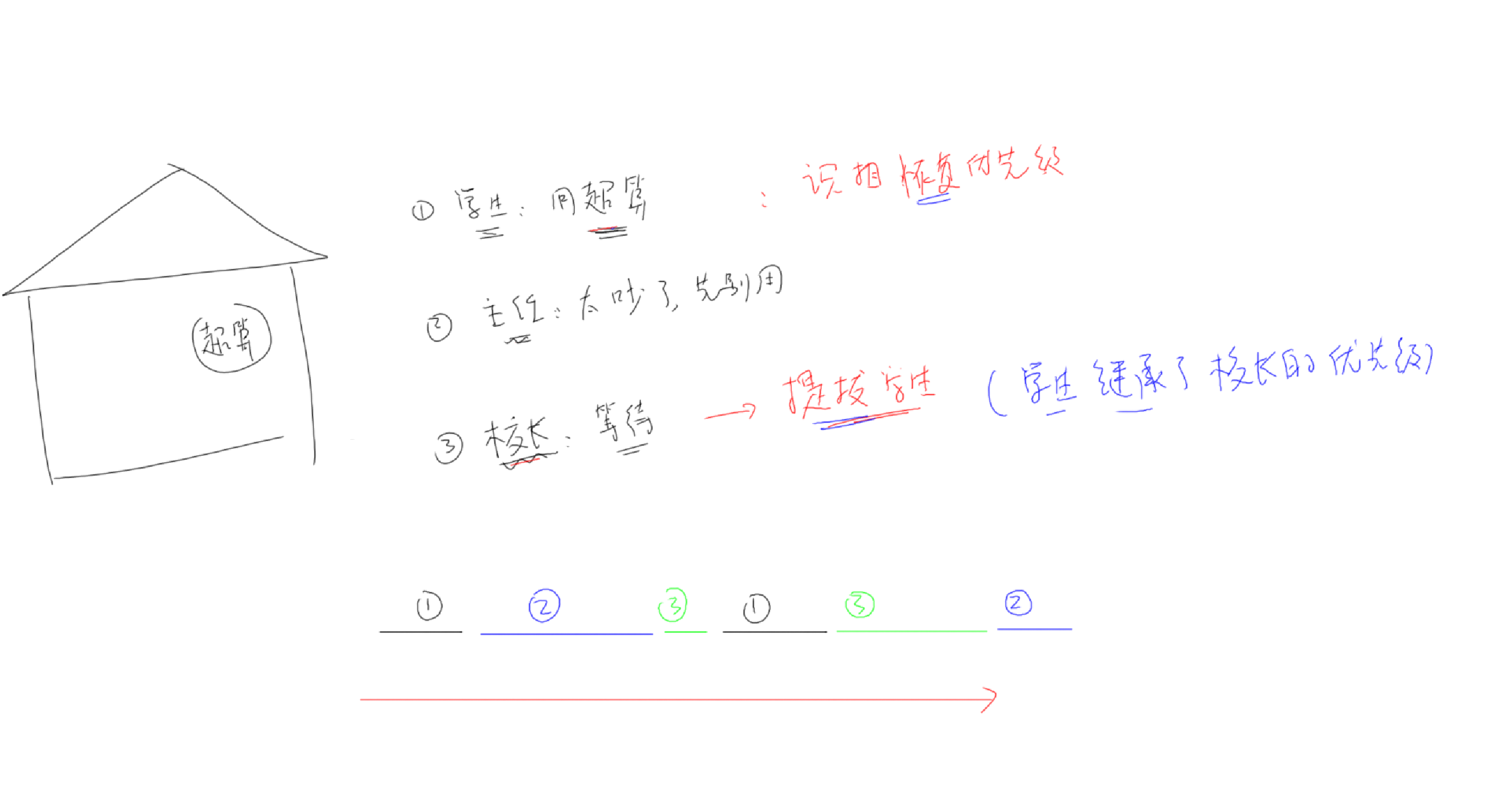
互斥量 & 优先级继承
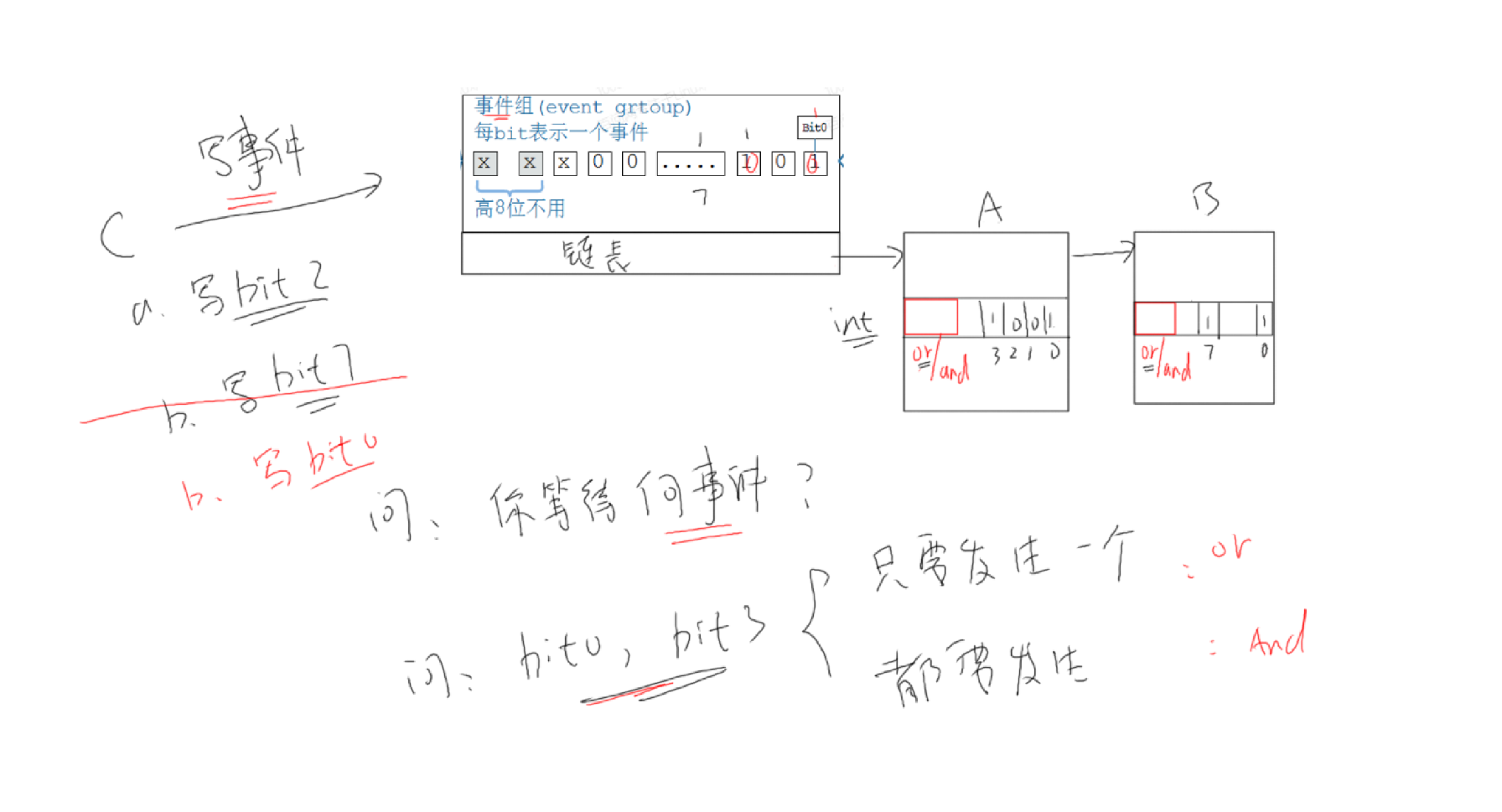
事件组
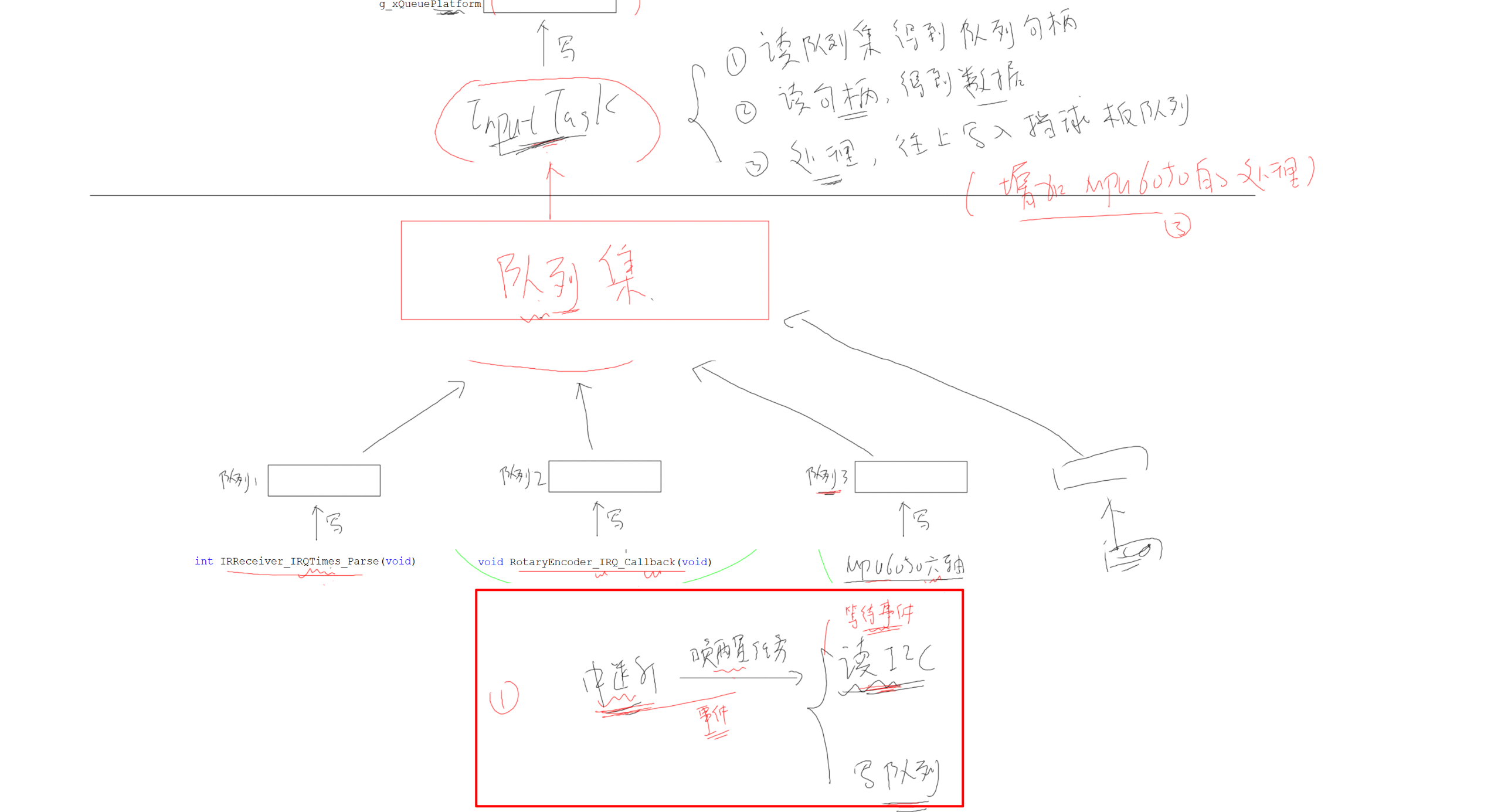
使用事件组优化不断轮询I2C读取MPU6050的问题
任务通知
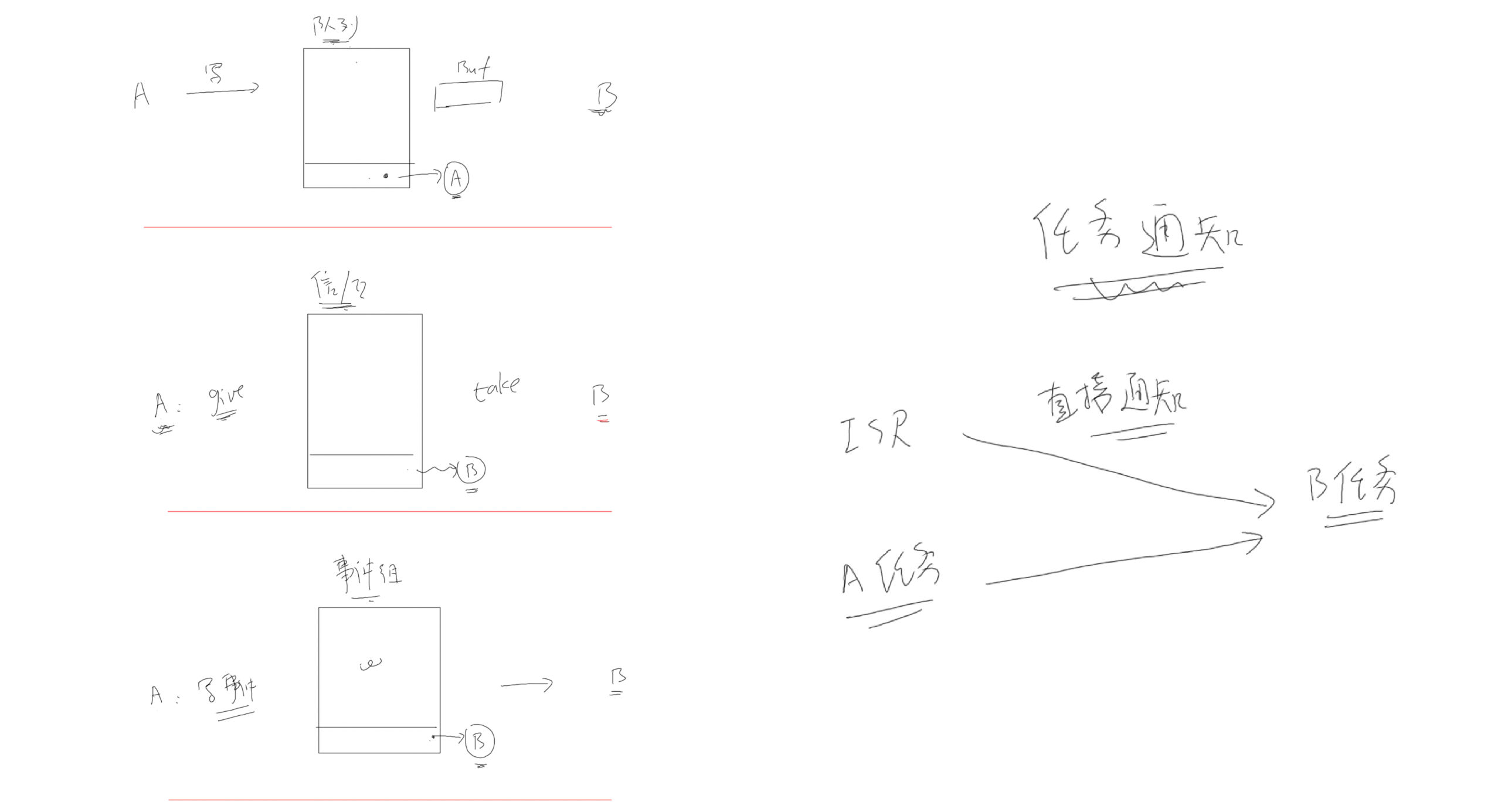
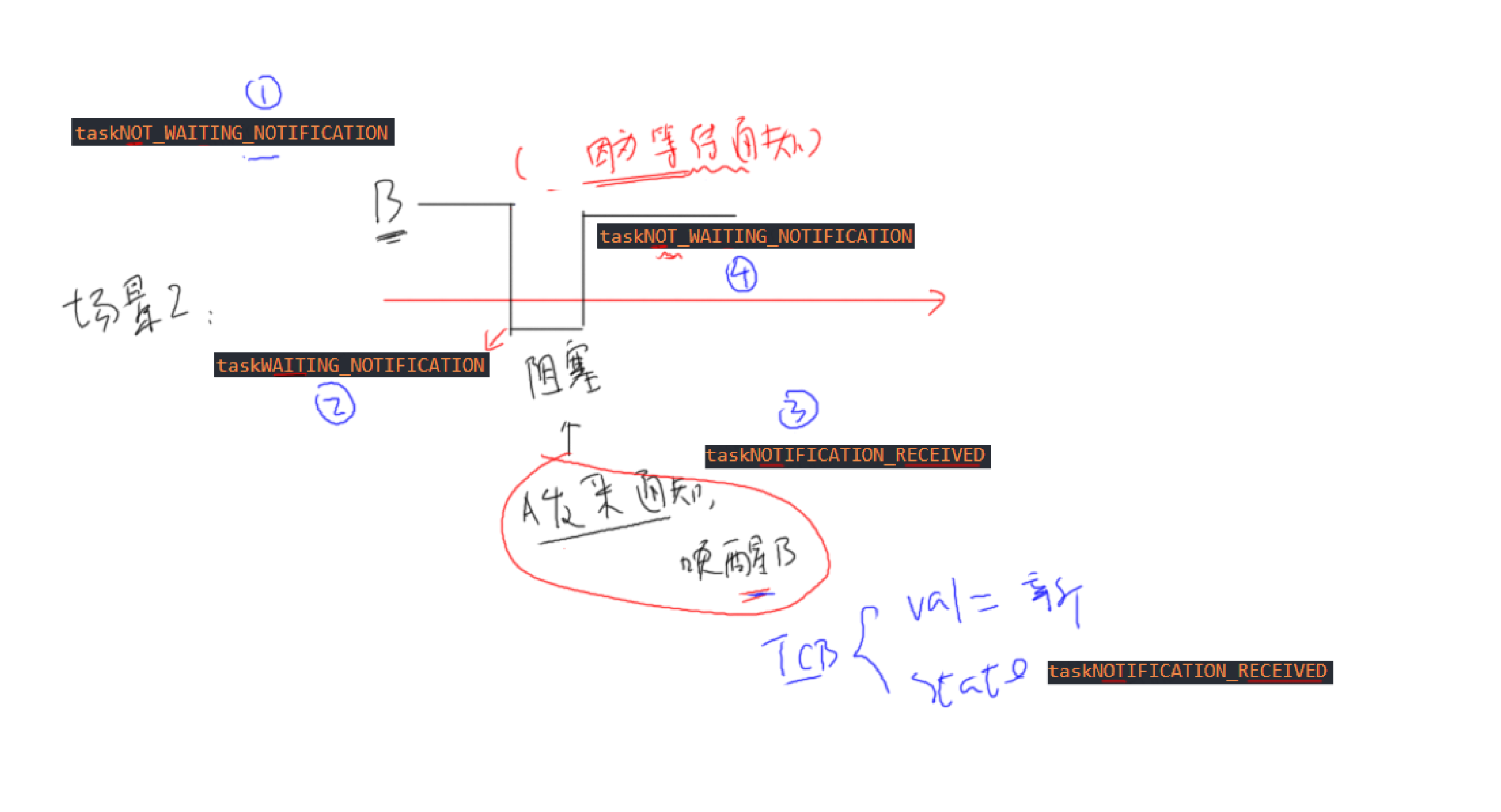
TCB通知状态

场景一:发送通知时,被通知方不是等待通知状态
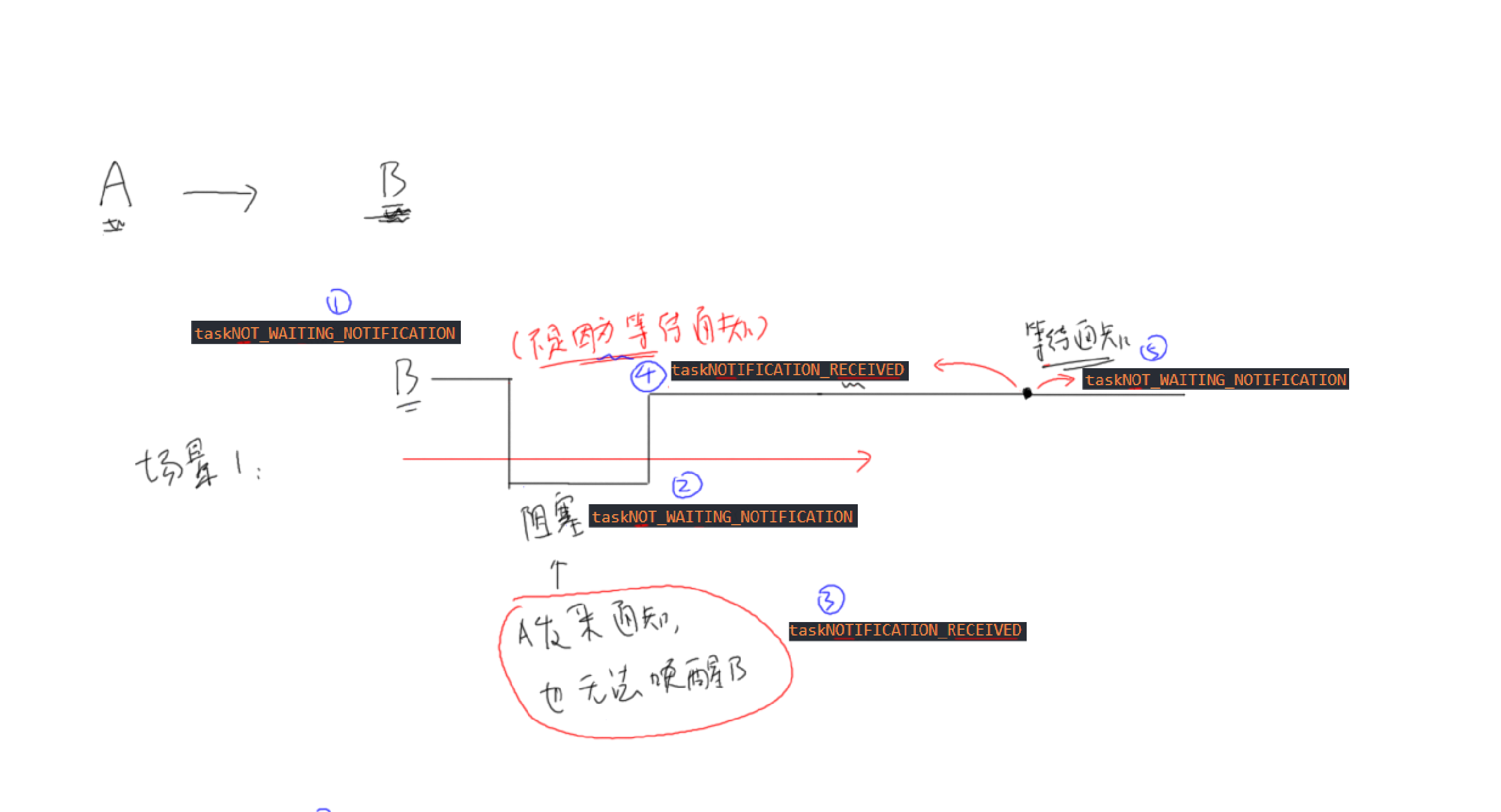
场景二:发送通知时,被通知方正在等待通知
两类函数
任务通知有2套函数,简化版、专业版,列表如下:
- 简化版函数的使用比较简单,它实际上也是使用专业版函数实现的
- 专业版函数支持很多参数,可以实现很多功能
| 简化版 | 专业版 | |
|---|---|---|
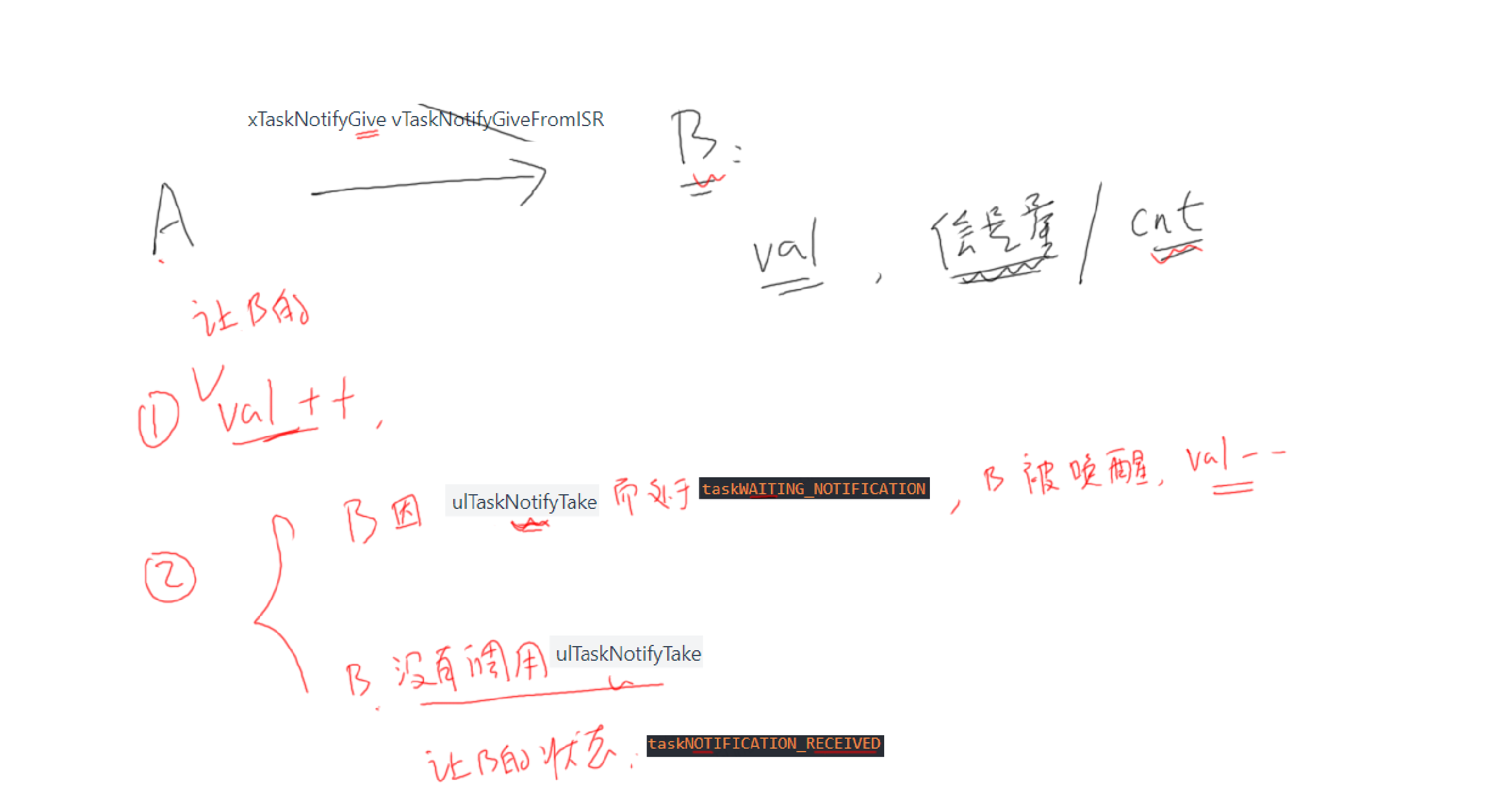
| 发出通知 | xTaskNotifyGive vTaskNotifyGiveFromISR | xTaskNotify xTaskNotifyFromISR |
| 取出通知 | ulTaskNotifyTake | xTaskNotifyWait |
简化版
专业版
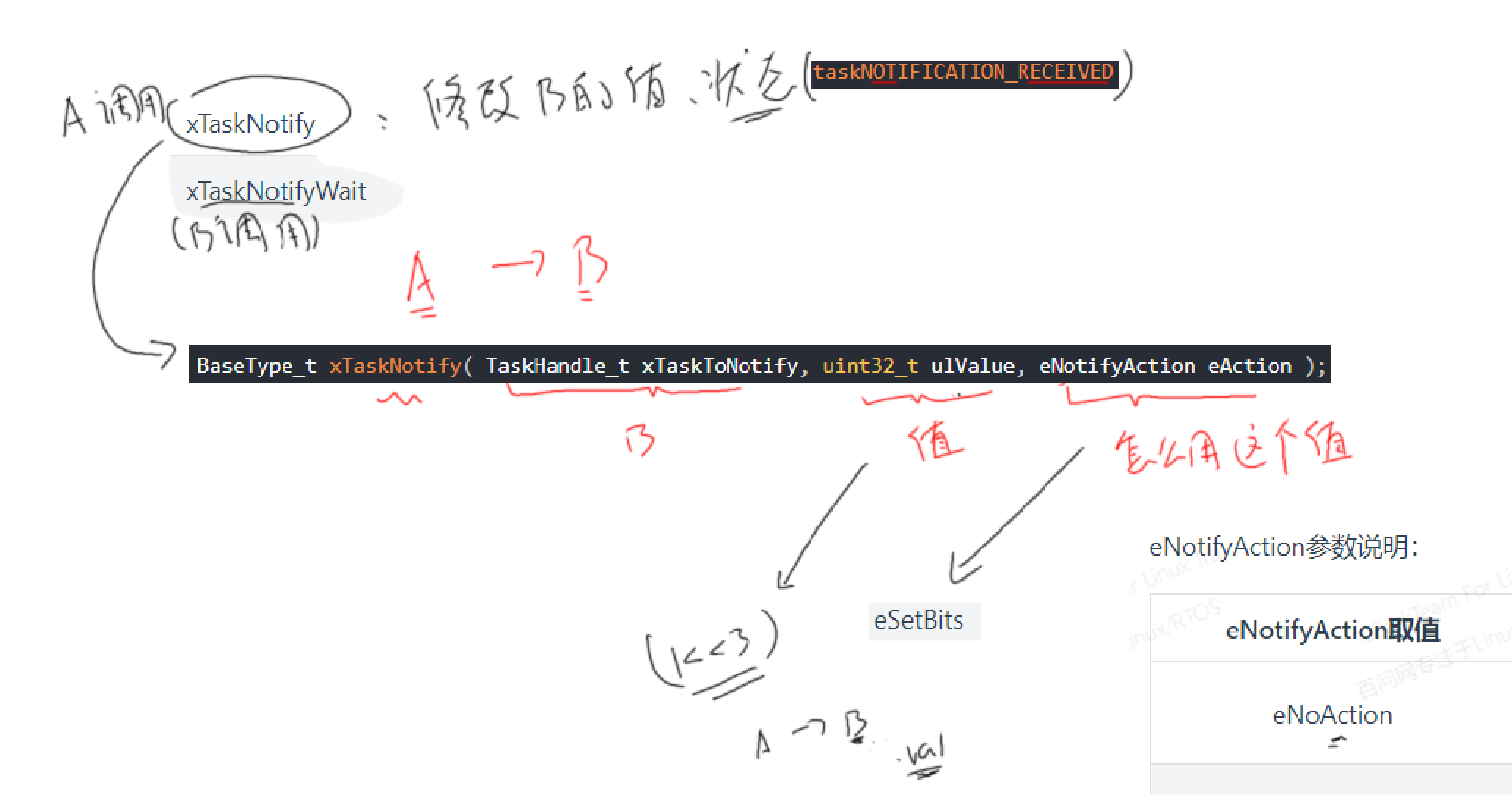
xTaskNotify函数的参数说明如下:
| 参数 | 说明 |
|---|---|
| xTaskToNotify | 任务句柄(创建任务时得到),给哪个任务发通知 |
| ulValue | 怎么使用ulValue,由eAction参数决定 |
| eAction | 见下表 |
| 返回值 | pdPASS:成功,大部分调用都会成功 pdFAIL:只有一种情况会失败,当eAction为eSetValueWithoutOverwrite, 并且通知状态为"pending"(表示有新数据未读),这时就会失败。 |
eNotifyAction参数说明:
| eNotifyAction取值 | 说明 |
|---|---|
| eNoAction | 仅仅是更新通知状态为"pending",未使用ulValue。 这个选项相当于轻量级的、更高效的二进制信号量。 |
| eSetBits | 通知值 = 原来的通知值 | ulValue,按位或。 相当于轻量级的、更高效的事件组。 |
| eIncrement | 通知值 = 原来的通知值 + 1,未使用ulValue。 相当于轻量级的、更高效的二进制信号量、计数型信号量。 相当于**xTaskNotifyGive()**函数。 |
| eSetValueWithoutOverwrite | 不覆盖。 如果通知状态为"pending"(表示有数据未读), 则此次调用xTaskNotify不做任何事,返回pdFAIL。 如果通知状态不是"pending"(表示没有新数据), 则:通知值 = ulValue。 |
| eSetValueWithOverwrite | 覆盖。 无论如何,不管通知状态是否为"pendng", 通知值 = ulValue。 |

软件定时器
软件定时器就是"闹钟",你可以设置闹钟,
- 在30分钟后让你起床工作
- 每隔1小时让你例行检查机器运行情况
软件定时器也可以完成两类事情:
- 在"未来"某个时间点,运行函数
- 周期性地运行函数
日常生活中我们可以定无数个"闹钟",这无数的"闹钟"要基于一个真实的闹钟。
在FreeRTOS里,我们也可以设置无数个"软件定时器",它们都是基于系统滴答中断(Tick Interrupt)。
软件定时器的特性
我们在手机上添加闹钟时,需要指定时间、指定类型(一次性的,还是周期性的)、指定做什么事;还有一些过时的、不再使用的闹钟。如下图所示:
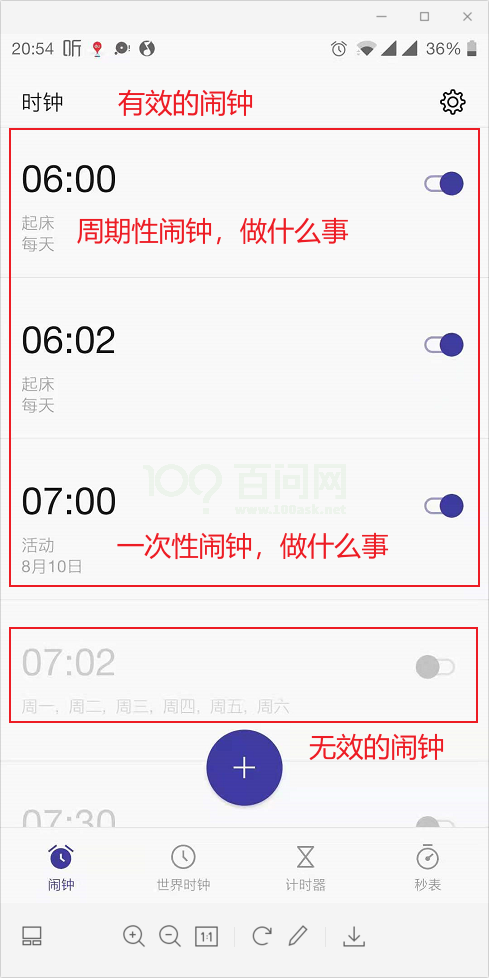
使用定时器跟使用手机闹钟是类似的:
- 指定时间:启动定时器和运行回调函数,两者的间隔被称为定时器的周期(period)。
- 指定类型,定时器有两种类型:
- 一次性(One-shot timers): 这类定时器启动后,它的回调函数只会被调用一次; 可以手工再次启动它,但是不会自动启动它。
- 自动加载定时器(Auto-reload timers ): 这类定时器启动后,时间到之后它会自动启动它; 这使得回调函数被周期性地调用。
- 指定要做什么事,就是指定回调函数
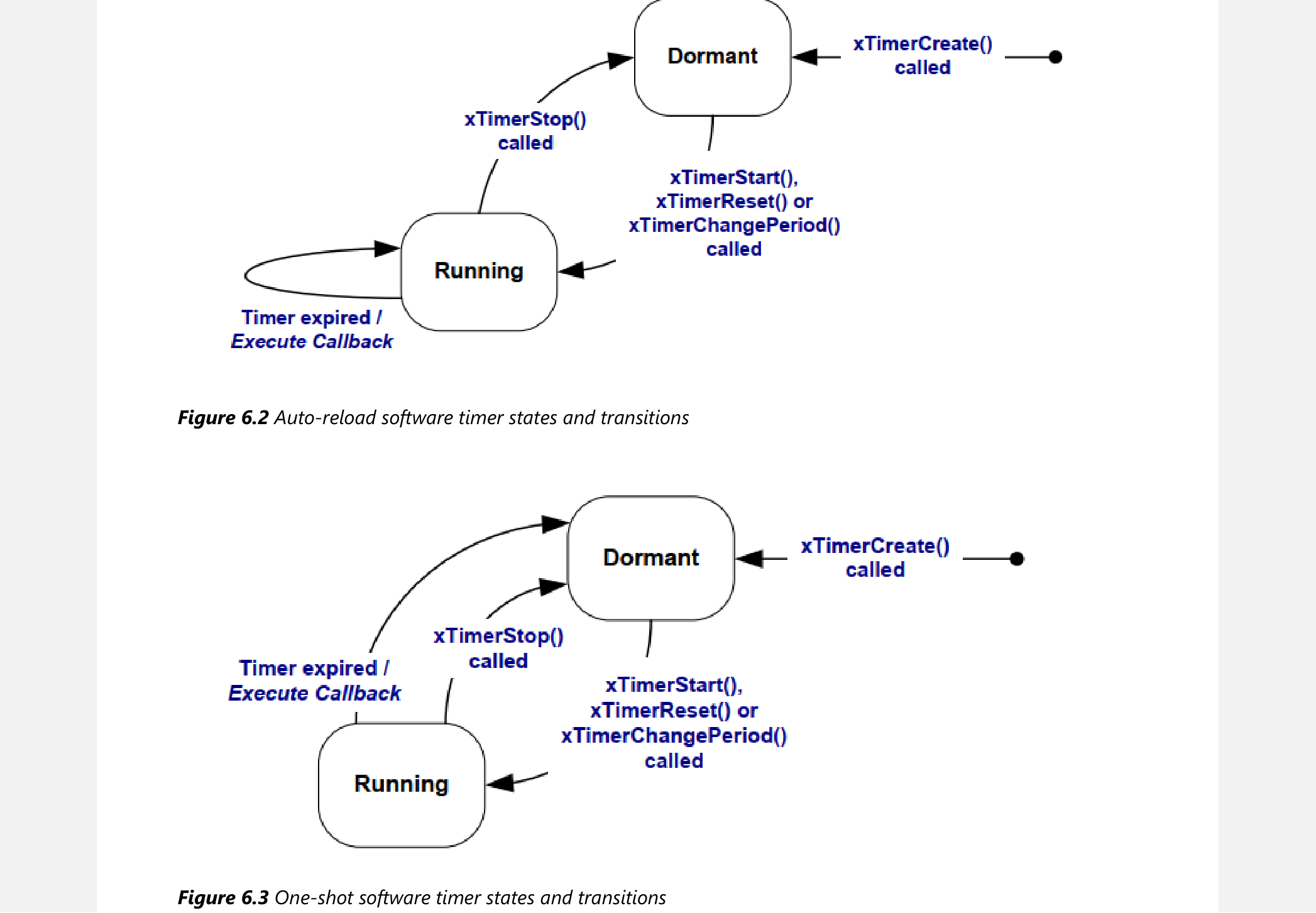
实际的闹钟分为:有效、无效两类。软件定时器也是类似的,它由两种状态:
- 运行(Running、Active):运行态的定时器,当指定时间到达之后,它的回调函数会被调用
- 冬眠(Dormant):冬眠态的定时器还可以通过句柄来访问它,但是它不再运行,它的回调函数不会被调用
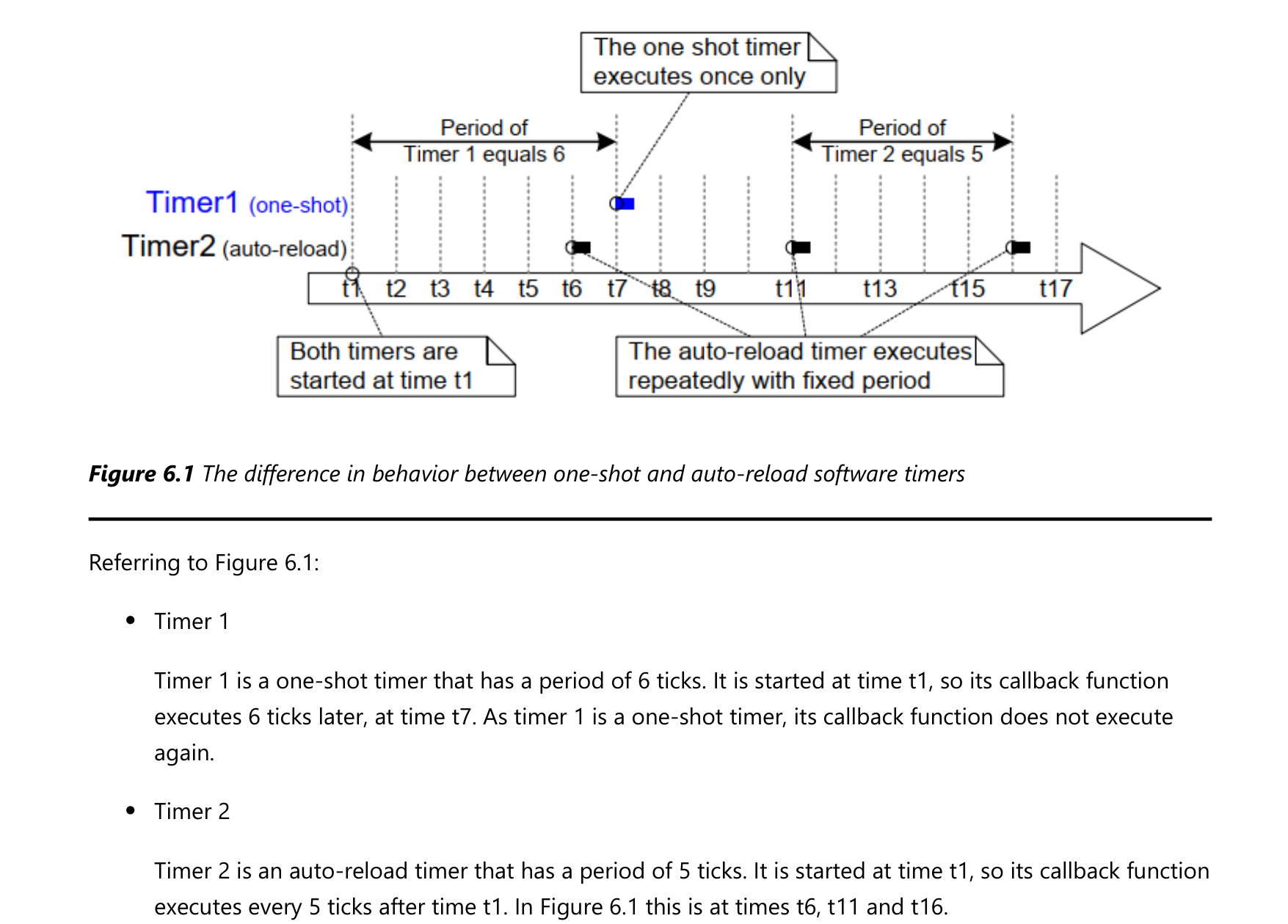
定时器运行情况示例如下:
- Timer1:它是一次性的定时器,在t1启动,周期是6个Tick。经过6个tick后,在t7执行回调函数。它的回调函数只会被执行一次,然后该定时器进入冬眠状态。
- Timer2:它是自动加载的定时器,在t1启动,周期是5个Tick。每经过5个tick它的回调函数都被执行,比如在t6、t11、t16都会执行。
上下文
要理解软件定时器API函数的参数,特别是里面的xTicksToWait,需要知道定时器执行的过程。
FreeRTOS中有一个Tick中断,软件定时器基于Tick来运行。在哪里执行定时器函数?第一印象就是在Tick中断里执行:
- 在Tick中断中判断定时器是否超时
- 如果超时了,调用它的回调函数
FreeRTOS是RTOS,它不允许在内核、在中断中执行不确定的代码:如果定时器函数很耗时,会影响整个系统。
所以,FreeRTOS中,不在Tick中断中执行定时器函数。
在哪里执行?在某个任务里执行,这个任务就是:RTOS Damemon Task,RTOS守护任务。以前被称为"Timer server",但是这个任务要做并不仅仅是定时器相关,所以改名为:RTOS Damemon Task。
当FreeRTOS的配置项configUSE_TIMERS被设置为1时,在启动调度器时,会自动创建RTOS Damemon Task。
我们自己编写的任务函数要使用定时器时,是通过"定时器命令队列"(timer command queue)和守护任务交互,如下图所示:
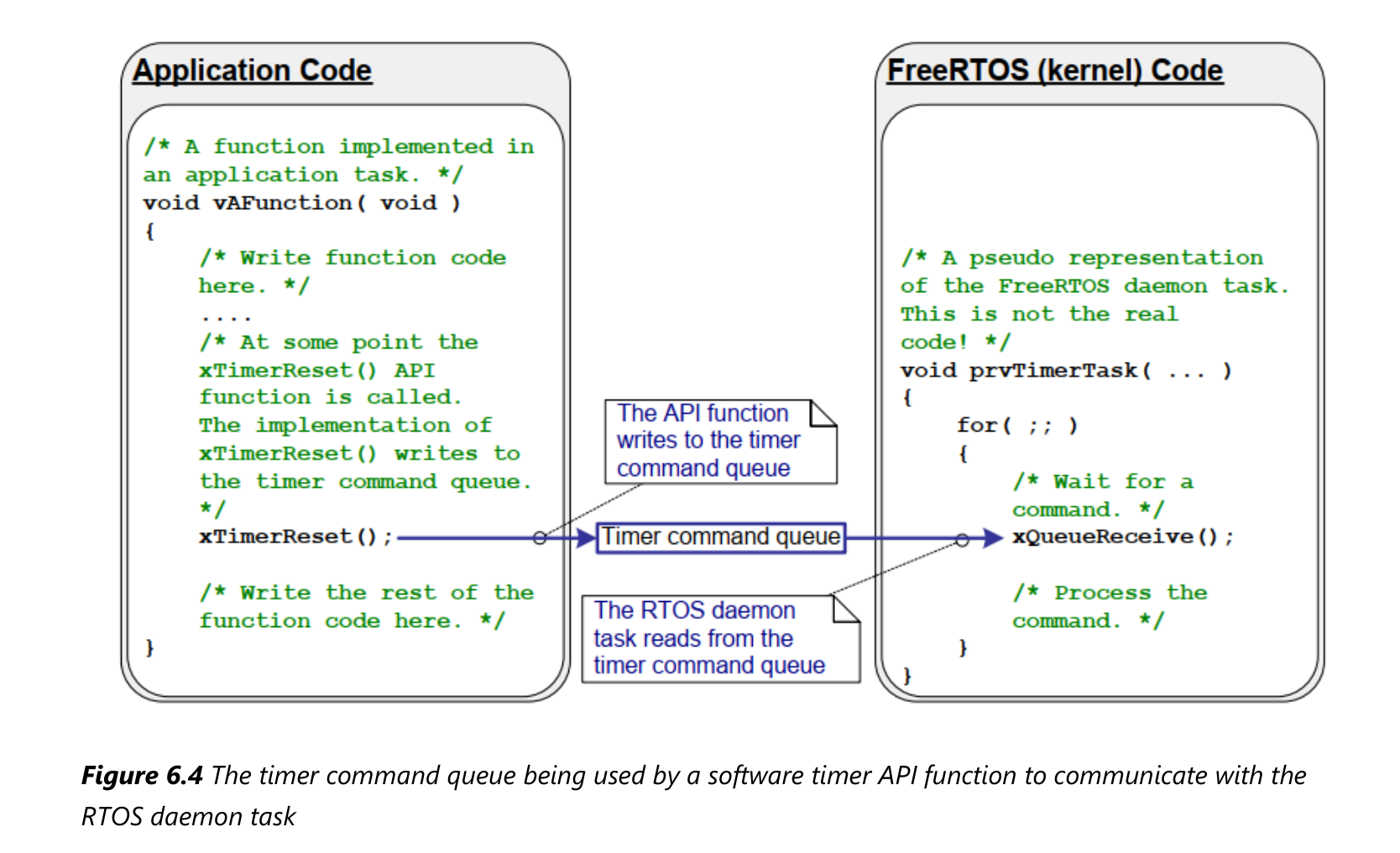

守护任务的优先级为:configTIMER_TASK_PRIORITY;定时器命令队列的长度为configTIMER_QUEUE_LENGTH。
守护任务调度
守护任务的调度,跟普通的任务并无差别。当守护任务是当前优先级最高的就绪态任务时,它就可以运行。它的工作有两类:
- 处理命令:从命令队列里取出命令、处理
- 执行定时器的回调函数
能否及时处理定时器的命令、能否及时执行定时器的回调函数,严重依赖于守护任务的优先级。下面使用2个例子来演示。
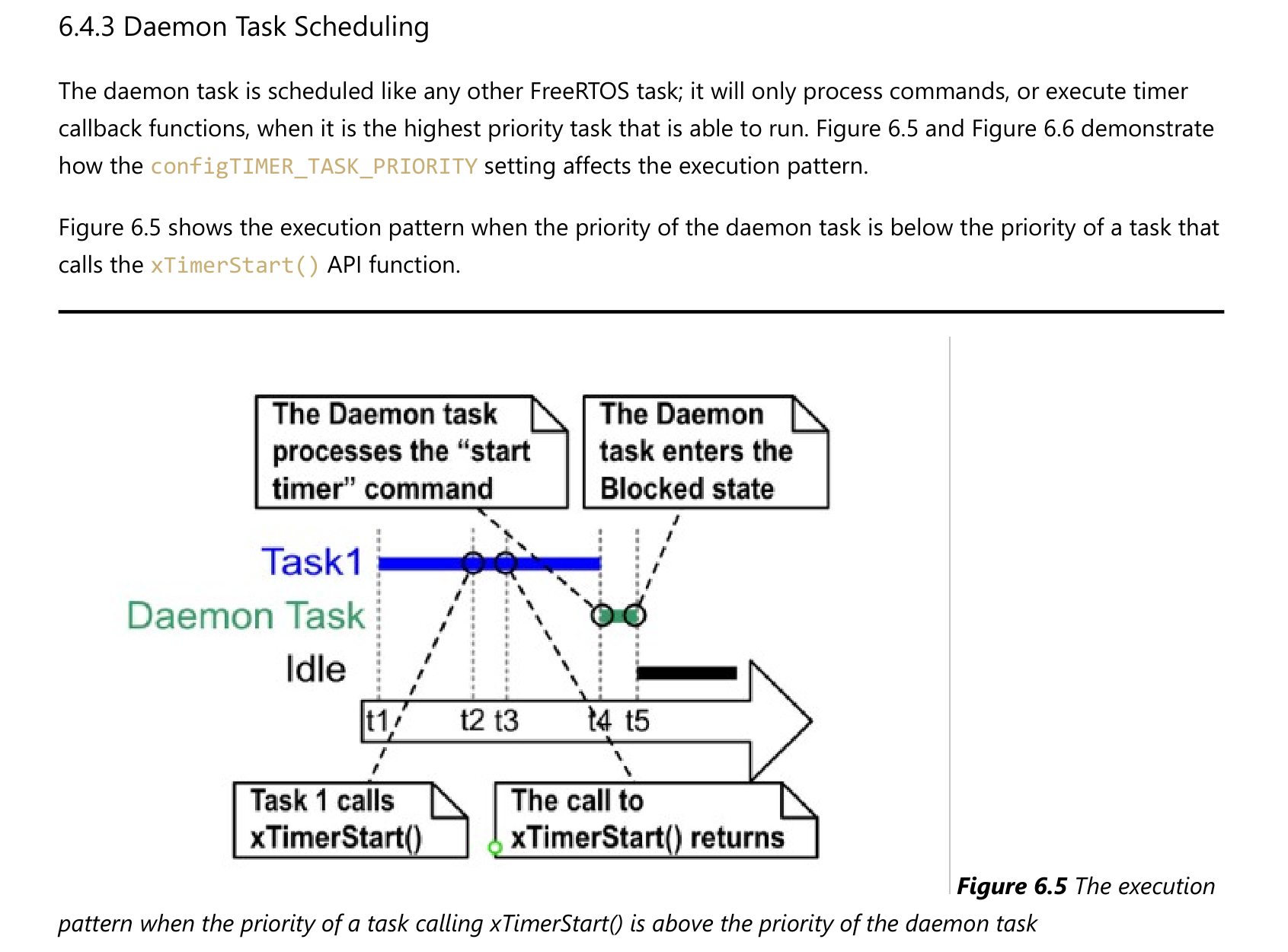
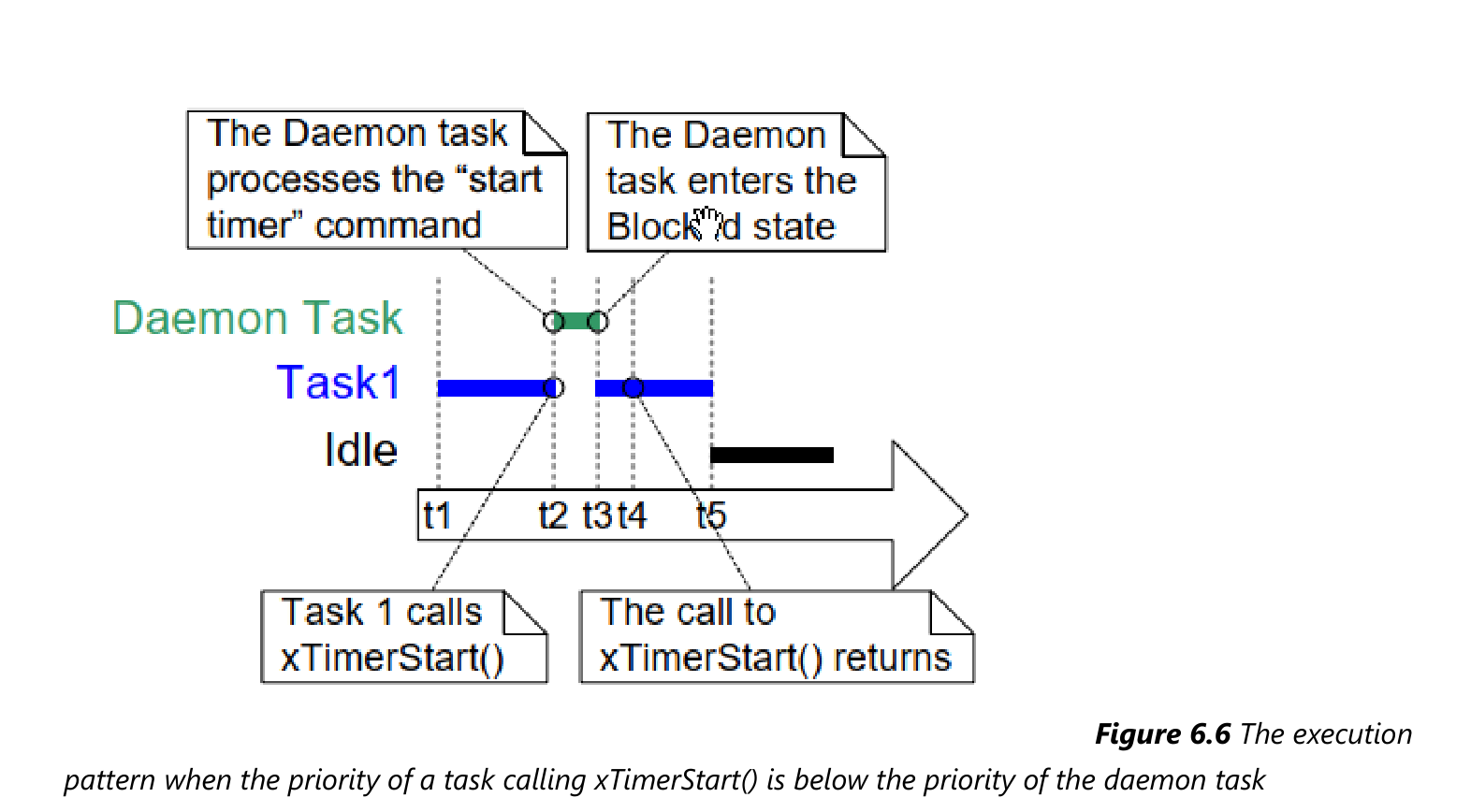
注意,定时器的超时时间是基于调用 xTimerStart() 的时刻tX,而不是基于守护任务处理命令的时刻tY。假设超时时间是10个Tick,超时时间是"tX+10",而非"tY+10"。
回调函数
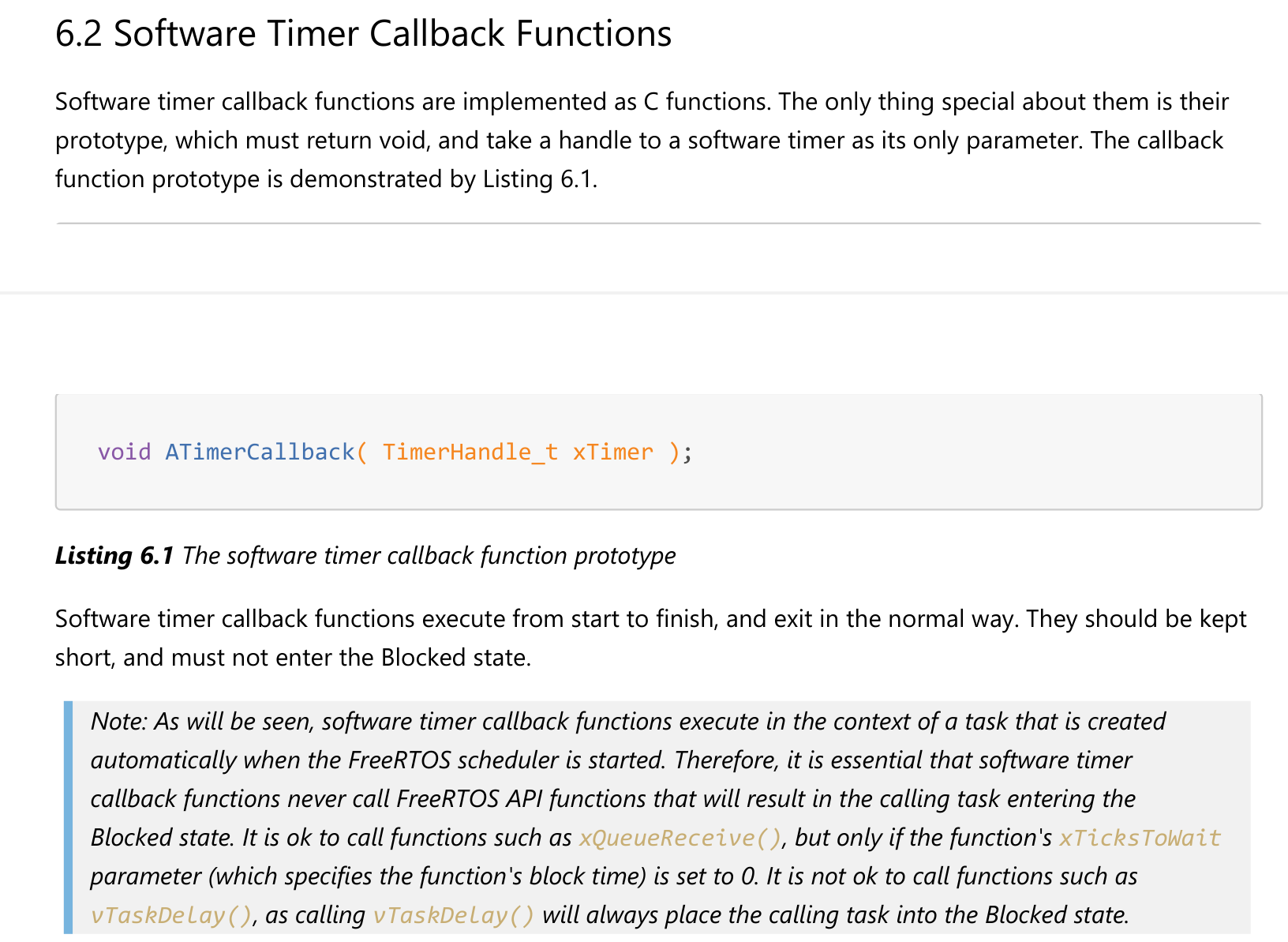
定时器的回调函数的原型如下:
void ATimerCallback( TimerHandle_t xTimer );定时器的回调函数是在守护任务中被调用的,守护任务不是专为某个定时器服务的,它还要处理其他定时器。
所以,定时器的回调函数不要影响其他人:
- 回调函数要尽快实行,不能进入阻塞状态
- 不要调用会导致阻塞的API函数,比如
vTaskDelay() - 可以调用
xQueueReceive()之类的函数,但是超时时间要设为0:即刻返回,不可阻塞
状态机
中断管理
在RTOS中,需要应对各类事件。这些事件很多时候是通过硬件中断产生,怎么处理中断呢?
假设当前系统正在运行Task1时,用户按下了按键,触发了按键中断。这个中断的处理流程如下:
- CPU跳到固定地址去执行代码,这个固定地址通常被称为中断向量,这个跳转时硬件实现的
- 执行代码做什么?
- 保存现场:Task1被打断,需要先保存Task1的运行环境,比如各类寄存器的值
- 分辨中断、调用处理函数(这个函数就被称为ISR,interrupt service routine)
- 恢复现场:继续运行Task1,或者运行其他优先级更高的任务
你要注意到,ISR是在内核中被调用的,ISR执行过程中,用户的任务无法执行。ISR要尽量快,否则:
- 其他低优先级的中断无法被处理:实时性无法保证
- 用户任务无法被执行:系统显得很卡顿
如果这个硬件中断的处理,就是非常耗费时间呢?对于这类中断的处理就要分为2部分:
- ISR:尽快做些清理、记录工作,然后触发某个任务
- 任务:更复杂的事情放在任务中处理
- 所以:需要ISR和任务之间进行通信
要在FreeRTOS中熟练使用中断,有几个原则要先说明:
- FreeRTOS把任务认为是硬件无关的,任务的优先级由程序员决定,任务何时运行由调度器决定
- ISR虽然也是使用软件实现的,但是它被认为是硬件特性的一部分,因为它跟硬件密切相关
- 何时执行?由硬件决定
- 哪个ISR被执行?由硬件决定
- ISR的优先级高于任务:即使是优先级最低的中断,它的优先级也高于任务。任务只有在没有中断的情况下,才能执行。
两套API:Xxx和XxxFromISR
为什么需要两套API
在任务函数中,我们可以调用各类API函数,比如队列操作函数:xQueueSendToBack。但是在ISR中使用这个函数会导致问题,应该使用另一个函数:xQueueSendToBackFromISR,它的函数名含有后缀"FromISR",表示"从ISR中给队列发送数据"。
FreeRTOS中很多API函数都有两套:一套在任务中使用,另一套在ISR中使用。后者的函数名含有"FromISR"后缀。
为什么要引入两套API函数?
- 很多API函数会导致任务进入阻塞状态:
- 运行这个函数的 任务 进入阻塞状态
- 比如写队列时,如果队列已满,可以进入阻塞状态等待一会
- ISR调用API函数时,ISR不是"任务",ISR不能进入阻塞状态
- 所以,在任务中、在ISR中,这些函数的功能是有差别的
为什么不使用同一套函数,比如在函数里面分辨当前调用者是任务还是ISR呢?示例代码如下

FreeRTOS使用两套函数,而不是使用一套函数,是因为有如下好处:
- 使用同一套函数的话,需要增加额外的判断代码、增加额外的分支,使得函数更长、更复杂、难以测试
- 在任务、ISR中调用时,需要的参数不一样,比如:
- 在任务中调用:需要指定超时时间,表示如果不成功就阻塞一会
- 在ISR中调用:不需要指定超时时间,无论是否成功都要即刻返回
- 如果强行把两套函数揉在一起,会导致参数臃肿、无效
- 移植FreeRTOS时,还需要提供监测上下文的函数,比如 is_in_isr()
- 有些处理器架构没有办法轻易分辨当前是处于任务中,还是处于ISR中,就需要额外添加更多、更复杂的代码
使用两套函数可以让程序更高效,但是也有一些缺点,比如你要使用第三方库函数时,即会在任务中调用它,也会在ISR中调用它。这个第三方库函数用到了FreeRTOS的API函数,你无法修改库函数。这个问题可以解决:
- 把中断的处理推迟到任务中进行(Defer interrupt processing),在任务中调用库函数
- 尝试在库函数中使用"FromISR"函数:
- 在任务中、在ISR中都可以调用"FromISR"函数
- 反过来就不行,非FromISR函数无法在ISR中使用
- 第三方库函数也许会提供OS抽象层,自行判断当前环境是在任务还是在ISR中,分别调用不同的函数


xHigherPriorityTaskWoken参数
xHigherPriorityTaskWoken的含义是:是否有更高优先级的任务被唤醒了。如果为pdTRUE,则意味着后面要进行任务切换。
还是以写队列为例。
任务A调用 xQueueSendToBack() 写队列,有几种情况发生:
- 队列满了,任务A阻塞等待,另一个任务B运行
- 队列没满,任务A成功写入队列,但是它导致另一个任务B被唤醒,任务B的优先级更高:任务B先运行
- 队列没满,任务A成功写入队列,即刻返回
可以看到,在任务中调用API函数可能导致任务阻塞、任务切换,这叫做"context switch",上下文切换。这个函数可能很长时间才返回,在函数的内部实现了任务切换。
xQueueSendToBackFromISR() 函数也可能导致任务切换,但是不会在函数内部进行切换,而是返回一个参数:表示是否需要切换,函数原型与用法如下:
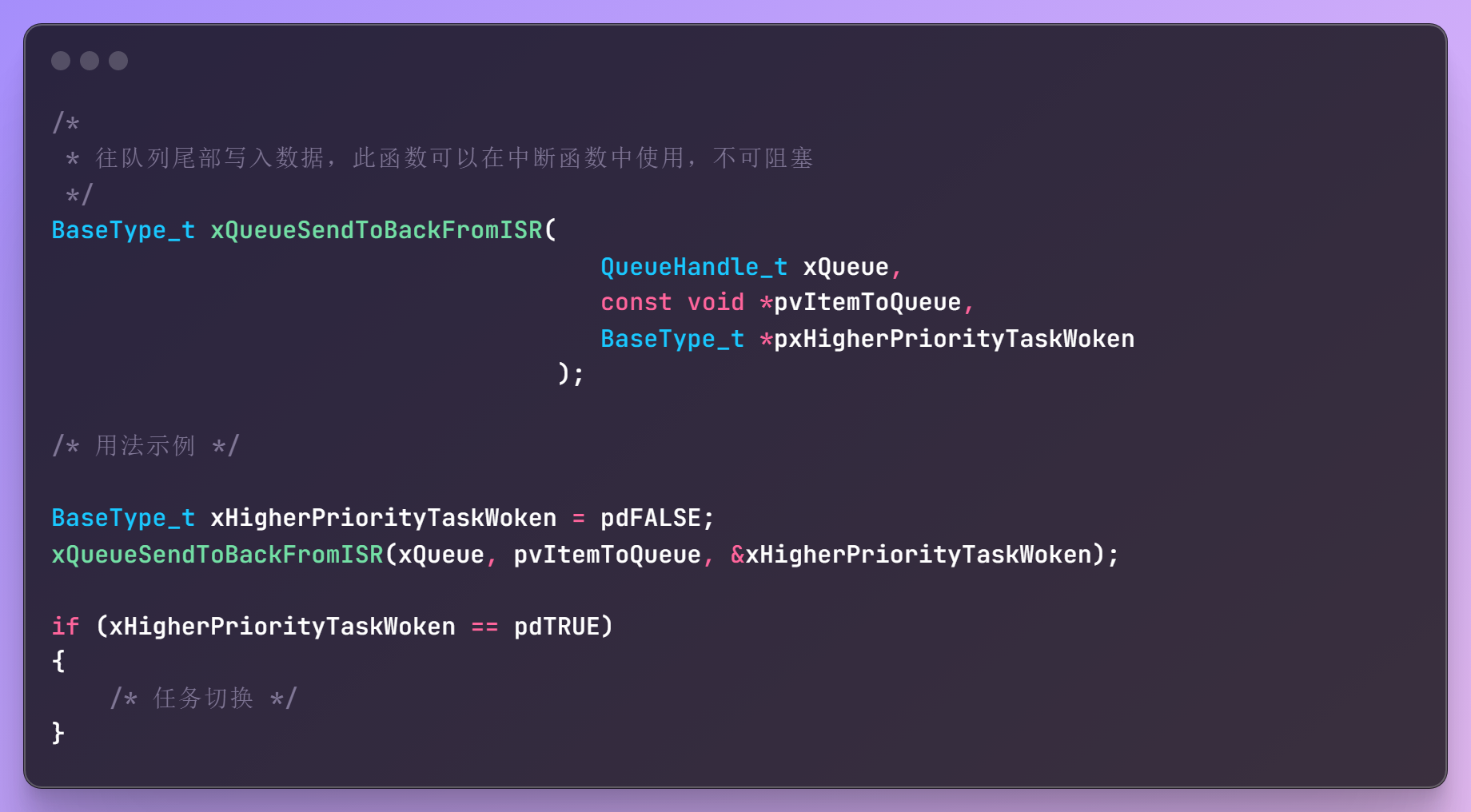
pxHigherPriorityTaskWoken参数,就是用来保存函数的结果:是否需要切换
pxHigherPriorityTaskWoken等于pdTRUE:函数的操作导致更高优先级的任务就绪了,ISR应该进行任务切换pxHigherPriorityTaskWoken等于pdFALSE:没有进行任务切换的必要
为什么不在"FromISR"函数内部进行任务切换,而只是标记一下而已呢?为了效率!示例代码如下:

ISR中有可能多次调用"FromISR"函数,如果在"FromISR"内部进行任务切换,会浪费时间。解决方法是:
- 在"FromISR"中标记是否需要切换
- 在ISR返回之前再进行任务切换
示例代码如下
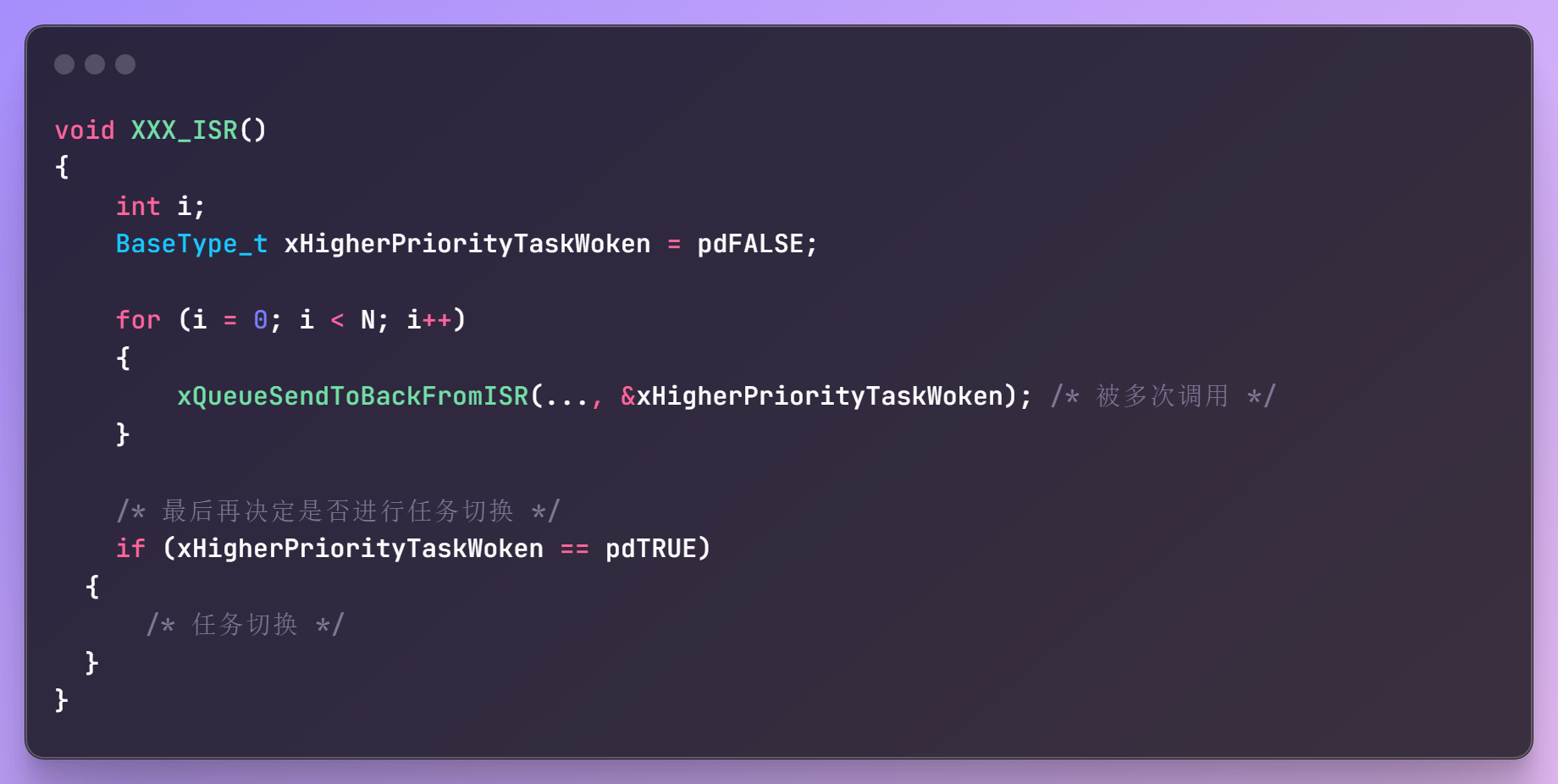
上述的例子很常见,比如UART中断:在UART的ISR中读取多个字符,发现收到回车符时才进行任务切换。
在ISR中调用API时不进行任务切换,而只是在xHigherPriorityTaskWoken中标记一下,除了效率,还有多种好处:
- 效率高:避免不必要的任务切换
- 让ISR更可控:中断随机产生,在API中进行任务切换的话,可能导致问题更复杂
- 可移植性
- 在Tick中断中,调用 vApplicationTickHook() :它运行于ISR,只能使用"FromISR"的函数
使用"FromISR"函数时,如果不想使用xHigherPriorityTaskWoken参数,可以设置为NULL。



怎么切换任务
FreeRTOS的ISR函数中,使用两个宏进行任务切换:

这两个宏做的事情是完全一样的,在老版本的FreeRTOS中,
- portEND_SWITCHING_ISR 使用汇编实现
- portYIELD_FROM_ISR 使用C语言实现
新版本都统一使用portYIELD_FROM_ISR。
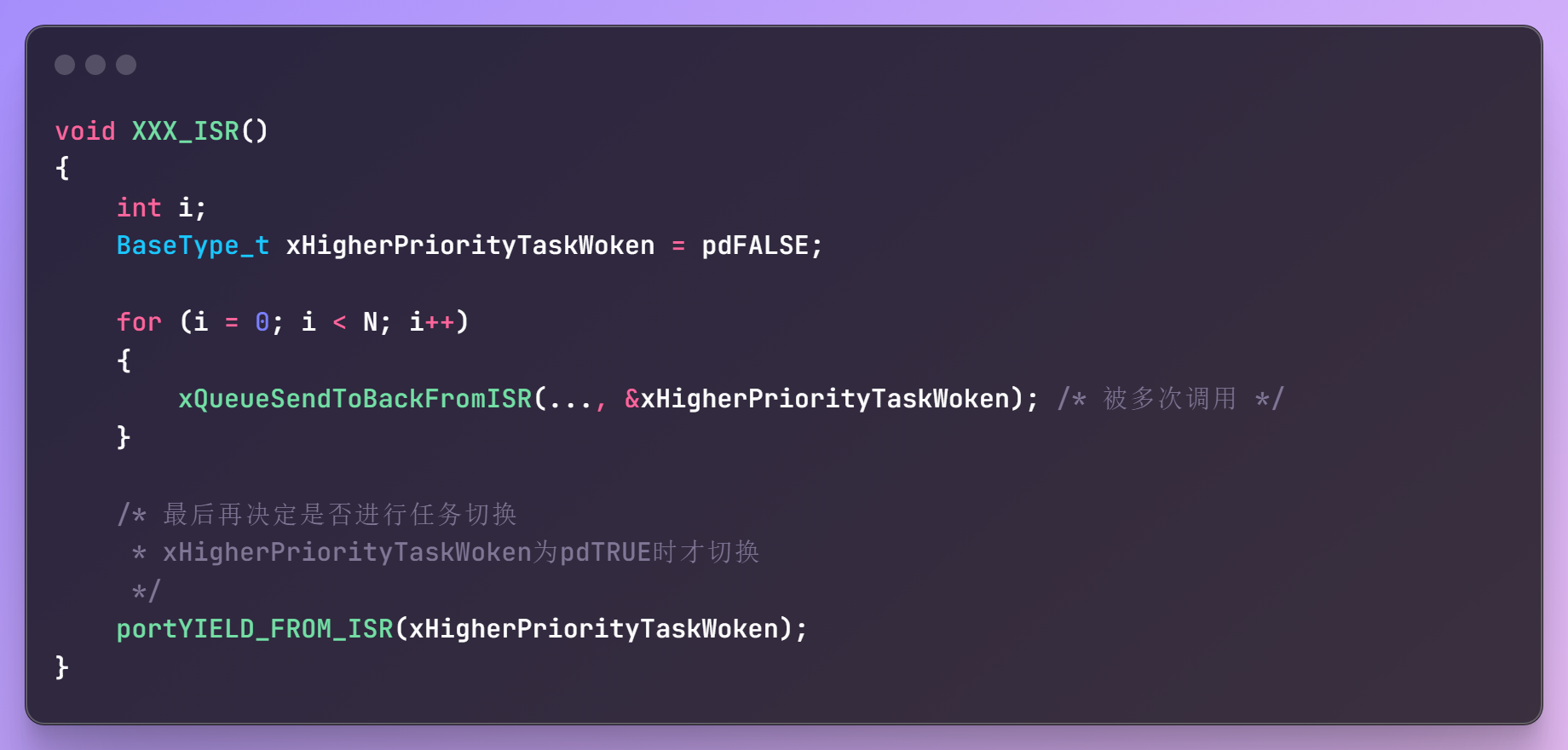
注意,这里只是将PendSV中断挂起标志位置位,等到合适的时机才会在PendSV中断中执行任务上下文切换
中断的延迟处理
前面讲过,ISR要尽量快,否则:
- 其他低优先级的中断无法被处理:实时性无法保证
- 用户任务无法被执行:系统显得很卡顿
- 如果运行中断嵌套,这会更复杂,ISR越快执行约有助于中断嵌套
如果这个硬件中断的处理,就是非常耗费时间呢?对于这类中断的处理就要分为2部分:
- ISR:尽快做些清理、记录工作,然后触发某个任务
- 任务:更复杂的事情放在任务中处理
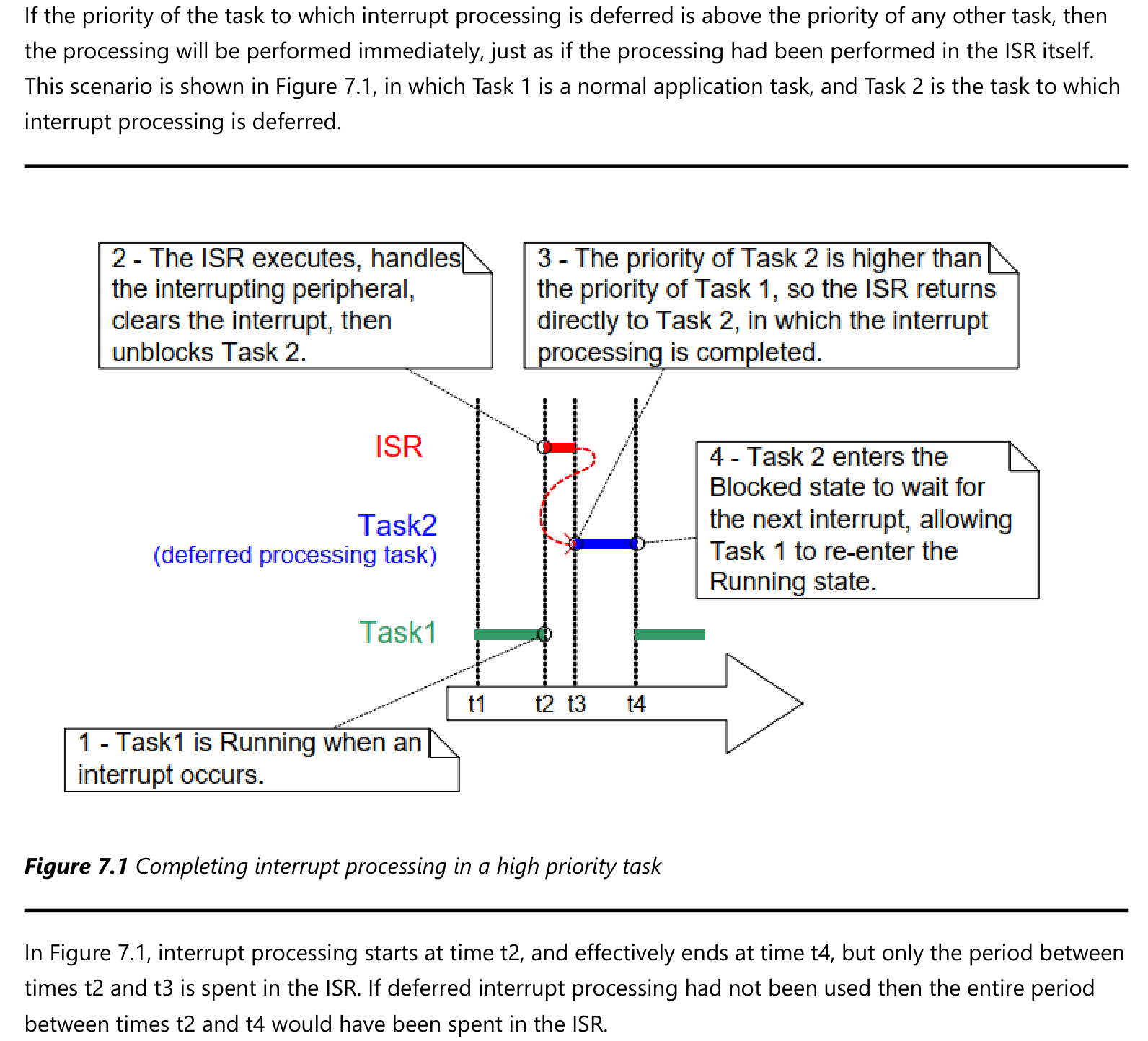
这种处理方式叫"中断的延迟处理"(Deferring interrupt processing),处理流程如下图所示:
- t1:任务1运行,任务2阻塞
- t2:发生中断,
- 该中断的ISR函数被执行,任务1被打断
- ISR函数要尽快能快速地运行,它做一些必要的操作(比如清除中断),然后唤醒任务2
- t3:在创建任务时设置任务2的优先级比任务1高(这取决于设计者),所以ISR返回后,运行的是任务2,它要完成中断的处理。任务2就被称为"deferred processing task",中断的延迟处理任务。
- t4:任务2处理完中断后,进入阻塞态以等待下一个中断,任务1重新运行
资源管理

要独占式地访问临界资源,有3种方法:
- 公平竞争:比如使用互斥量,谁先获得互斥量谁就访问临界资源。
- 谁要跟我抢,我就灭掉谁:
- 中断要跟我抢?我屏蔽中断
- 其他任务要跟我抢?我禁止调度器,不运行任务切换
屏蔽中断
屏蔽中断有两套宏:任务中使用、ISR中使用:
- 任务中使用:
taskENTER_CRITICA()/taskEXIT_CRITICAL() - ISR中使用:
taskENTER_CRITICAL_FROM_ISR()/taskEXIT_CRITICAL_FROM_ISR()
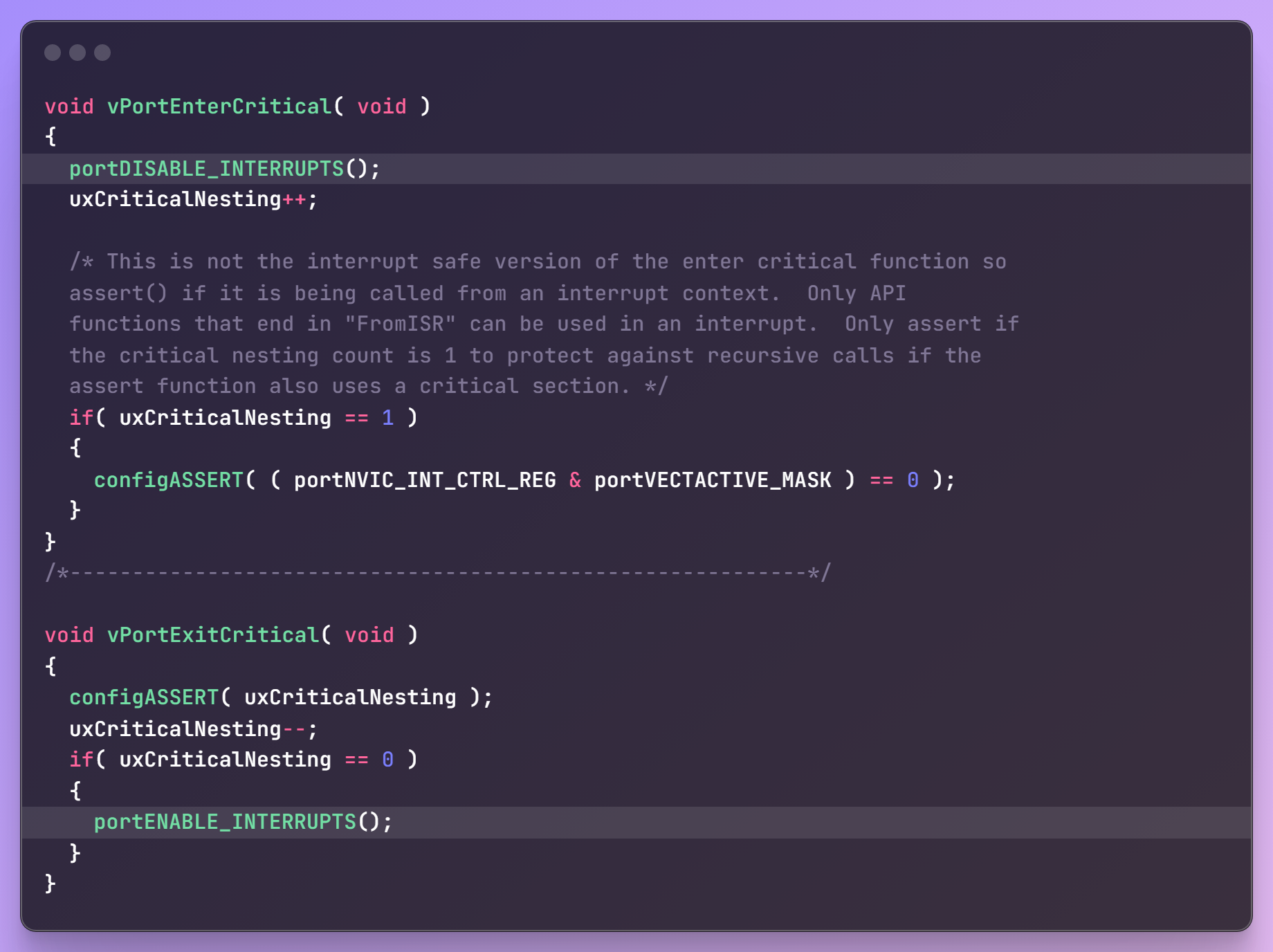
在任务中屏蔽中断
在任务中屏蔽中断的示例代码如下:

在 taskENTER_CRITICA()/taskEXIT_CRITICAL() 之间:
- 低优先级的中断被屏蔽了:优先级低于、等于
configMAX_SYSCALL_INTERRUPT_PRIORITY - 高优先级的中断可以产生:优先级高于
configMAX_SYSCALL_INTERRUPT_PRIORITY- 但是,这些中断ISR里,不允许使用FreeRTOS的API函数
- 任务调度依赖于中断、依赖于API函数,所以:这两段代码之间,不会有任务调度产生
这套 taskENTER_CRITICA()/taskEXIT_CRITICAL() 宏,是可以递归使用的(可重入的),它的内部会记录嵌套的深度,只有嵌套深度变为0时,调用 taskEXIT_CRITICAL() 才会重新使能中断。
使用 taskENTER_CRITICA()/taskEXIT_CRITICAL() 来访问临界资源是很粗鲁的方法:
- 中断无法正常运行
- 任务调度无法进行
- 所以,之间的代码要尽可能快速地执行
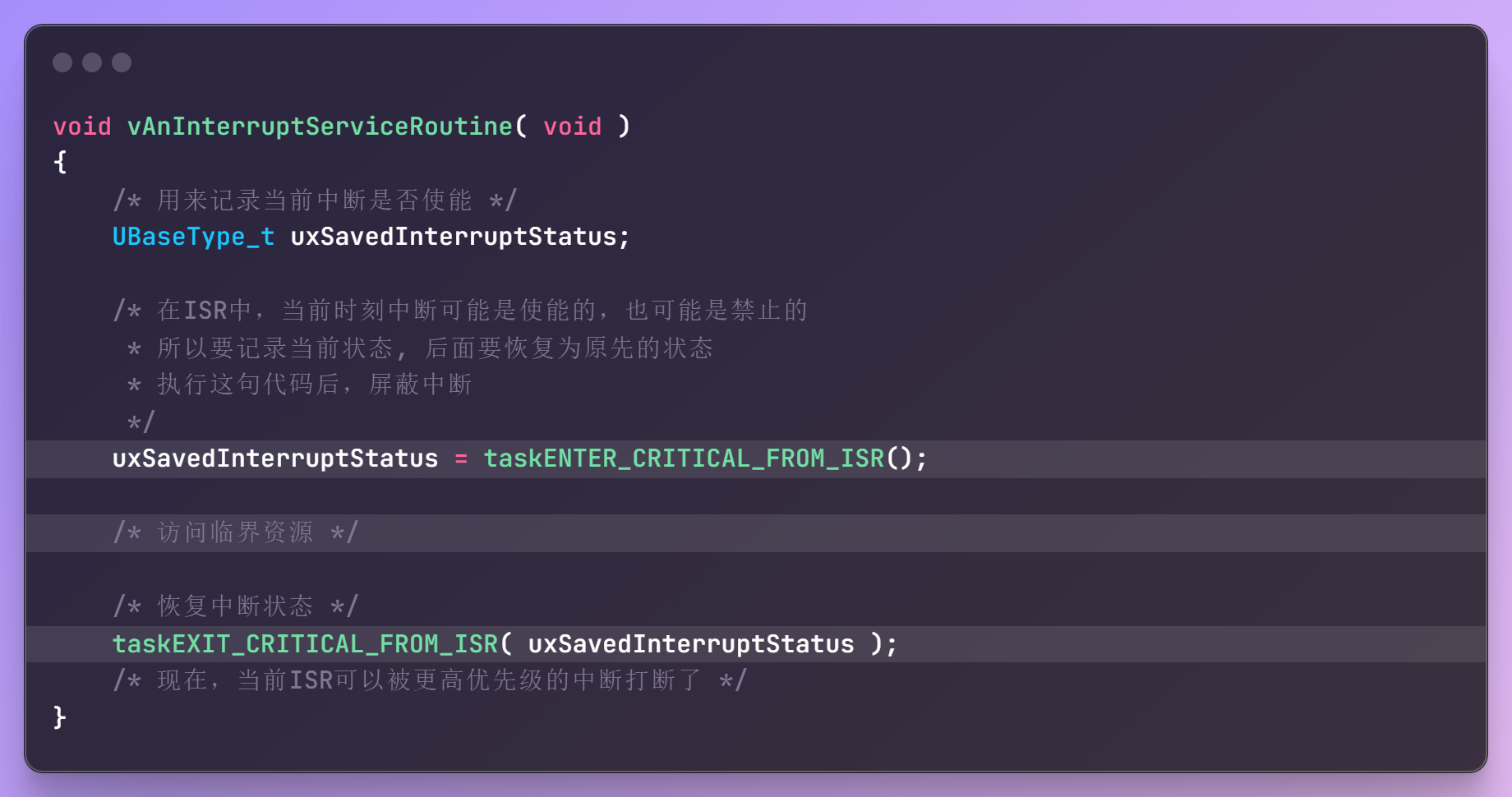
在ISR中屏蔽中断
要使用含有"FROM_ISR"后缀的宏,示例代码如下:
暂停调度器
如果有别的任务来跟你竞争临界资源,你可以把中断关掉:这当然可以禁止别的任务运行,但是这代价太大了。它会影响到中断的处理。
如果只是禁止别的任务来跟你竞争,不需要关中断,暂停调度器就可以了:在这期间,中断还是可以发生、处理。
使用这2个函数来暂停、恢复调度器:

示例代码如下:

这套 vTaskSuspendScheduler()/xTaskResumeScheduler() 宏,是可以递归使用的,它的内部会记录嵌套的深度,只有嵌套深度变为0时,调用 taskEXIT_CRITICAL() 才会重新使能中断。
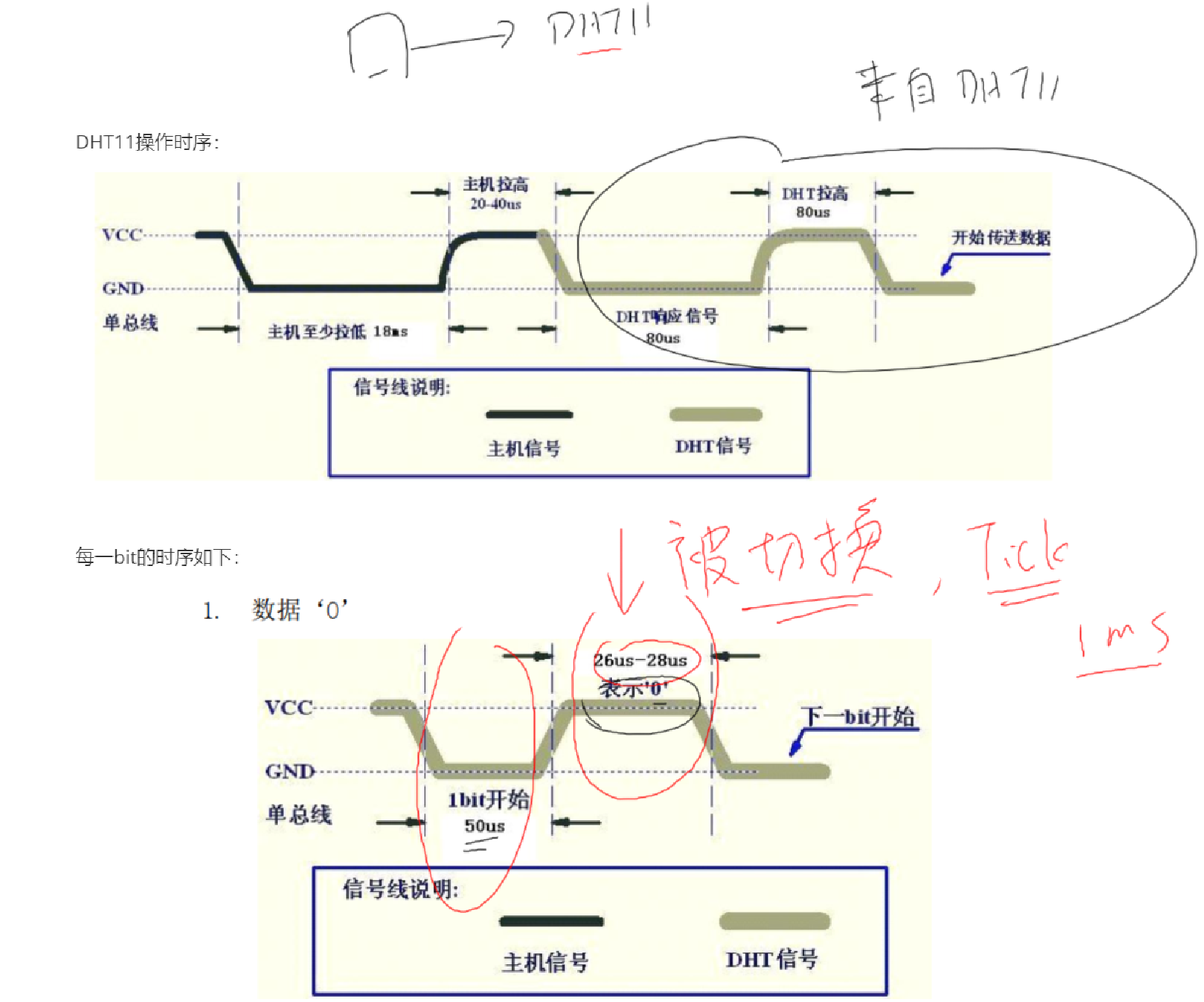
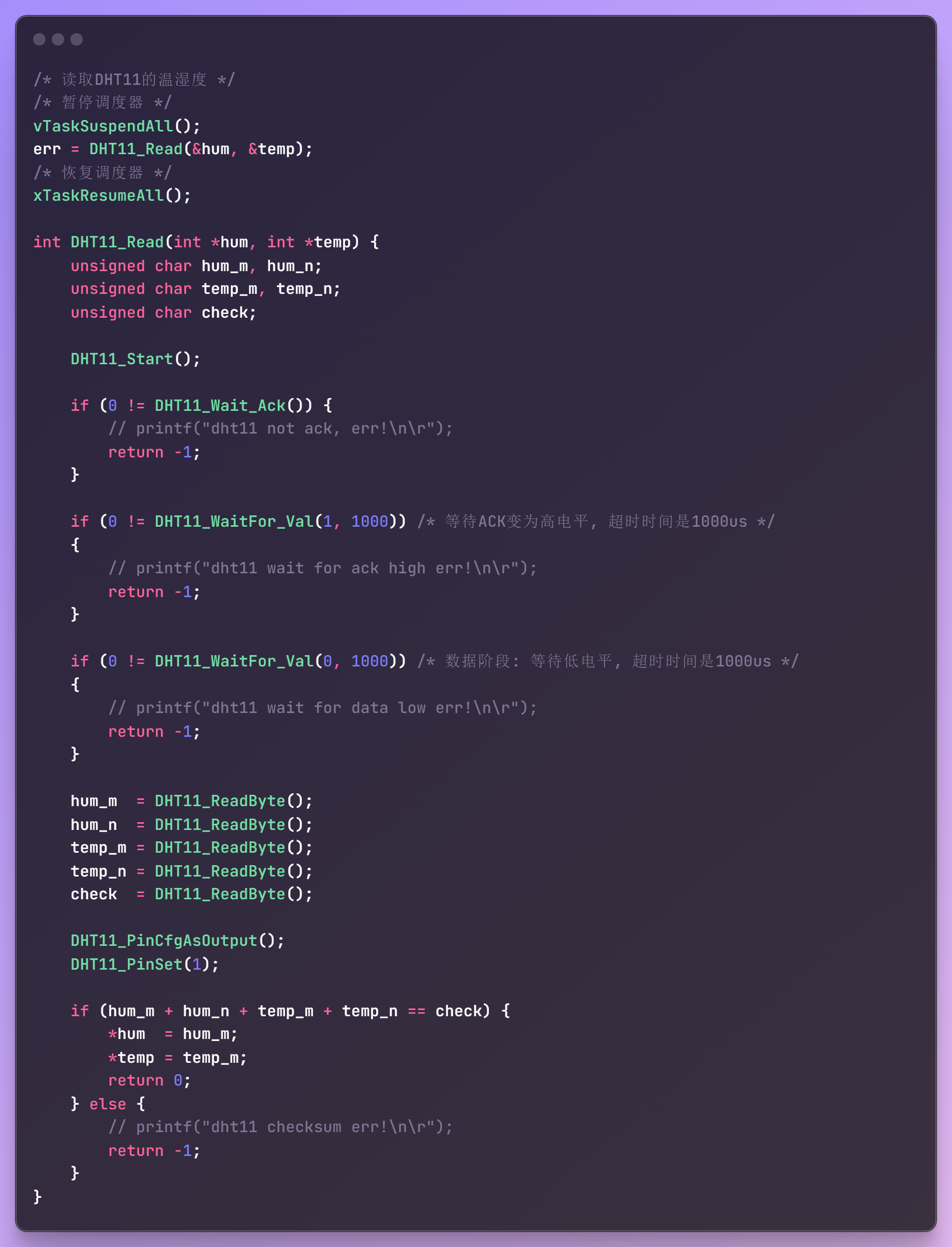
案例——原子化DHT11操作时序
调试与优化
调试
FreeRTOS提供了很多调试手段:
- 打印
- 断言:configASSERT
- Trace
- Hook函数(回调函数)
打印
printf:FreeRTOS工程里使用了microlib,里面实现了printf函数。
我们只需实现一下函数即可使用printf:
int fputc( int ch, FILE *f );断言
一般的C库里面,断言就是一个函数:
void assert(scalar expression);它的作用是:确认expression必须为真,如果expression为假的话就中止程序。
在FreeRTOS里,使用 configASSERT(),比如:
##define configASSERT(x) if (!x) while(1);我们可以让它提供更多信息,比如:
##define configASSERT(x) \
if (!x) \
{
printf("%s %s %d\r\n", __FILE__, __FUNCTION__, __LINE__); \
while(1); \
}configASSERT(x)中,如果x为假,表示发生了很严重的错误,必须停止系统的运行。
它用在很多场合,比如:
- 队列操作
BaseType_t xQueueGenericSend( QueueHandle_t xQueue,
const void * const pvItemToQueue,
TickType_t xTicksToWait,
const BaseType_t xCopyPosition )
{
BaseType_t xEntryTimeSet = pdFALSE, xYieldRequired;
TimeOut_t xTimeOut;
Queue_t * const pxQueue = xQueue;
configASSERT( pxQueue );
configASSERT(!((pvItemToQueue == NULL) && (pxQueue->uxItemSize != (UBaseType_t)0U)));
configASSERT( !((xCopyPosition == queueOVERWRITE) && (pxQueue->uxLength != 1 )));- 中断级别的判断
void vPortValidateInterruptPriority( void )
{
uint32_t ulCurrentInterrupt;
uint8_t ucCurrentPriority;
/* Obtain the number of the currently executing interrupt. */
ulCurrentInterrupt = vPortGetIPSR();
/* Is the interrupt number a user defined interrupt? */
if( ulCurrentInterrupt >= portFIRST_USER_INTERRUPT_NUMBER )
{
/* Look up the interrupt's priority. */
ucCurrentPriority = pcInterruptPriorityRegisters[ ulCurrentInterrupt ];
configASSERT( ucCurrentPriority >= ucMaxSysCallPriority );
}Trace
FreeRTOS中定义了很多trace开头的宏,这些宏被放在系统个关键位置。
它们一般都是空的宏,这不会影响代码:不影响编程处理的程序大小、不影响运行时间。
我们要调试某些功能时,可以修改宏:修改某些标记变量、打印信息等待。
| trace宏 | 描述 |
|---|---|
| traceTASK_INCREMENT_TICK(xTickCount) | 当tick计数自增之前此宏函数被调用。参数xTickCount当前的Tick值,它还没有增加。 |
| traceTASK_SWITCHED_OUT() | vTaskSwitchContext中,把当前任务切换出去之前调用此宏函数。 |
| traceTASK_SWITCHED_IN() | vTaskSwitchContext中,新的任务已经被切换进来了,就调用此函数。 |
| traceBLOCKING_ON_QUEUE_RECEIVE(pxQueue) | 当正在执行的当前任务因为试图去读取一个空的队列、信号或者互斥量而进入阻塞状态时,此函数会被立即调用。参数pxQueue保存的是试图读取的目标队列、信号或者互斥量的句柄,传递给此宏函数。 |
| traceBLOCKING_ON_QUEUE_SEND(pxQueue) | 当正在执行的当前任务因为试图往一个已经写满的队列或者信号或者互斥量而进入了阻塞状态时,此函数会被立即调用。参数pxQueue保存的是试图写入的目标队列、信号或者互斥量的句柄,传递给此宏函数。 |
| traceQUEUE_SEND(pxQueue) | 当一个队列或者信号发送成功时,此宏函数会在内核函数xQueueSend(),xQueueSendToFront(),xQueueSendToBack(),以及所有的信号give函数中被调用,参数pxQueue是要发送的目标队列或信号的句柄,传递给此宏函数。 |
| traceQUEUE_SEND_FAILED(pxQueue) | 当一个队列或者信号发送失败时,此宏函数会在内核函数xQueueSend(),xQueueSendToFront(),xQueueSendToBack(),以及所有的信号give函数中被调用,参数pxQueue是要发送的目标队列或信号的句柄,传递给此宏函数。 |
| traceQUEUE_RECEIVE(pxQueue) | 当读取一个队列或者接收信号成功时,此宏函数会在内核函数xQueueReceive()以及所有的信号take函数中被调用,参数pxQueue是要接收的目标队列或信号的句柄,传递给此宏函数。 |
| traceQUEUE_RECEIVE_FAILED(pxQueue) | 当读取一个队列或者接收信号失败时,此宏函数会在内核函数xQueueReceive()以及所有的信号take函数中被调用,参数pxQueue是要接收的目标队列或信号的句柄,传递给此宏函数。 |
| traceQUEUE_SEND_FROM_ISR(pxQueue) | 当在中断中发送一个队列成功时,此函数会在xQueueSendFromISR()中被调用。参数pxQueue是要发送的目标队列的句柄。 |
| traceQUEUE_SEND_FROM_ISR_FAILED(pxQueue) | 当在中断中发送一个队列失败时,此函数会在xQueueSendFromISR()中被调用。参数pxQueue是要发送的目标队列的句柄。 |
| traceQUEUE_RECEIVE_FROM_ISR(pxQueue) | 当在中断中读取一个队列成功时,此函数会在xQueueReceiveFromISR()中被调用。参数pxQueue是要发送的目标队列的句柄。 |
| traceQUEUE_RECEIVE_FROM_ISR_FAILED(pxQueue) | 当在中断中读取一个队列失败时,此函数会在xQueueReceiveFromISR()中被调用。参数pxQueue是要发送的目标队列的句柄。 |
| traceTASK_DELAY_UNTIL() | 当一个任务因为调用了vTaskDelayUntil()进入了阻塞状态的前一刻此宏函数会在vTaskDelayUntil()中被立即调用。 |
| traceTASK_DELAY() | 当一个任务因为调用了vTaskDelay()进入了阻塞状态的前一刻此宏函数会在vTaskDelay中被立即调用。 |
Malloc Hook函数
编程时,一般的逻辑错误都容易解决。难以处理的是内存越界、栈溢出等。
内存越界经常发生在堆的使用过程总:堆,就是使用malloc得到的内存。
并没有很好的方法检测内存越界,但是可以提供一些回调函数:
- 使用pvPortMalloc失败时,如果在FreeRTOSConfig.h里配置 configUSE_MALLOC_FAILED_HOOK 为1,会调用:
void vApplicationMallocFailedHook( void );栈溢出Hook函数
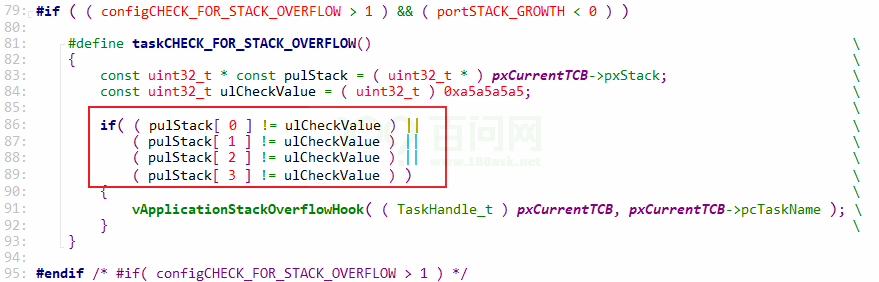
在切换任务(vTaskSwitchContext)时调用taskCHECK_FOR_STACK_OVERFLOW来检测栈是否溢出,如果溢出会调用:
void vApplicationStackOverflowHook( TaskHandle_t xTask, char * pcTaskName );怎么判断栈溢出?有两种方法:
- 方法1:
- 当前任务被切换出去之前,它的整个运行现场都被保存在栈里,这时 很可能 就是它对栈的使用到达了峰值。
- 这方法很高效,但是并不精确
- 比如:任务在运行过程中调用了函数A大量地使用了栈,调用完函数A后才被调度。
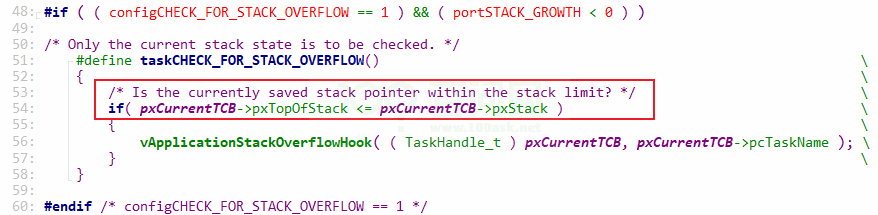
- 方法2:
- 创建任务时,它的栈被填入固定的值,比如:0xa5
- 检测栈里最后16字节的数据,如果不是0xa5的话表示栈即将、或者已经被用完了
- 没有方法1快速,但是也足够快
- 能捕获 几乎所有 的栈溢出
- 为什么是几乎所有?可能有些函数使用栈时,非常凑巧地把栈设置为0xa5:几乎不可能
优化
在Windows中,当系统卡顿时我们可以查看任务管理器找到最消耗CPU资源的程序。
在FreeRTOS中,我们也可以查看任务使用CPU的情况、使用栈的情况,然后针对性地进行优化。
这就是查看"任务的统计"信息。
栈使用情况
在创建任务时分配了栈,可以填入固定的数值比如0xa5,以后可以使用以下函数查看"栈的高水位",也就是还有多少空余的栈空间:
UBaseType_t uxTaskGetStackHighWaterMark( TaskHandle_t xTask );原理是:从栈底往栈顶逐个字节地判断,它们的值持续是0xa5就表示它是空闲的。
函数说明:
| 参数/返回值 | 说明 |
|---|---|
| xTask | 哪个任务 |
| 返回值 | 任务运行时、任务被切换时,都会用到栈。栈里原来值(0xa5)就会被覆盖。 逐个函数从栈的尾部判断栈的值连续为0xa5的个数, 它就是任务运行过程中空闲内存容量的最小值。 注意:假设从栈尾开始连续为0xa5的栈空间是N字节,返回值是N/4。 |
任务运行时间统计
对于同优先级的任务,它们按照时间片轮流运行:你执行一个Tick,我执行一个Tick。
是否可以在Tick中断函数中,统计当前任务的累计运行时间?
不行!很不精确,因为有更高优先级的任务就绪时,当前任务还没运行一个完整的Tick就被抢占了。
我们需要比Tick更快的时钟,比如Tick周期时1ms,我们可以使用另一个定时器,让它发生中断的周期时0.1ms甚至更短。
使用这个定时器来衡量一个任务的运行时间,原理如下图所示:

- 切换到Task1时,使用更快的定时器记录当前时间T1
- Task1被切换出去时,使用更快的定时器记录当前时间T4
- (T4-T1)就是它运行的时间,累加起来
- 关键点:在 vTaskSwitchContext 函数中,使用 更快的定时器 统计运行时间
涉及的代码
- 配置
#define configGENERATE_RUN_TIME_STATS 1
#define configUSE_TRACE_FACILITY 1
#define configUSE_STATS_FORMATTING_FUNCTIONS 1- 实现宏 portCONFIGURE_TIMER_FOR_RUN_TIME_STATS(),它用来初始化更快的定时器
- 实现这两个宏之一,它们用来返回当前时钟值(更快的定时器)
- portGET_RUN_TIME_COUNTER_VALUE():直接返回时钟值
- portALT_GET_RUN_TIME_COUNTER_VALUE(Time):设置Time变量等于时钟值
代码执行流程:
- 初始化更快的定时器:启动调度器时
在任务切换时统计运行时间

- 获得统计信息,可以使用下列函数
- uxTaskGetSystemState:对于每个任务它的统计信息都放在一个TaskStatus_t结构体里
- vTaskList:得到的信息是可读的字符串,比如
- vTaskGetRunTimeStats: 得到的信息是可读的字符串
函数说明
- uxTaskGetSystemState:获得任务的统计信息
UBaseType_t uxTaskGetSystemState( TaskStatus_t * const pxTaskStatusArray,
const UBaseType_t uxArraySize,
uint32_t * const pulTotalRunTime );| 参数 | 描述 |
|---|---|
| pxTaskStatusArray | 指向一个TaskStatus_t结构体数组,用来保存任务的统计信息。 有多少个任务?可以用 uxTaskGetNumberOfTasks() 来获得。 |
| uxArraySize | 数组大小、数组项个数,必须大于或等于 uxTaskGetNumberOfTasks() |
| pulTotalRunTime | 用来保存当前总的运行时间(更快的定时器),可以传入NULL |
| 返回值 | 传入的pxTaskStatusArray数组,被设置了几个数组项。 注意:如果传入的uxArraySize小于 uxTaskGetNumberOfTasks() ,返回值就是0 |
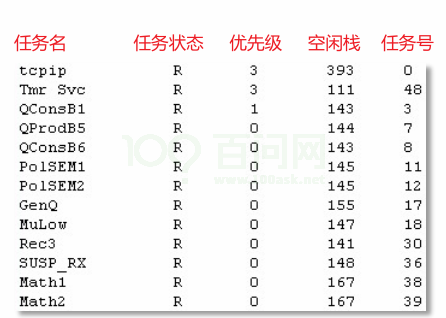
- vTaskList :获得任务的统计信息,形式为可读的字符串。注意,pcWriteBuffer必须足够大。
void vTaskList( signed char *pcWriteBuffer );可读信息格式如下:
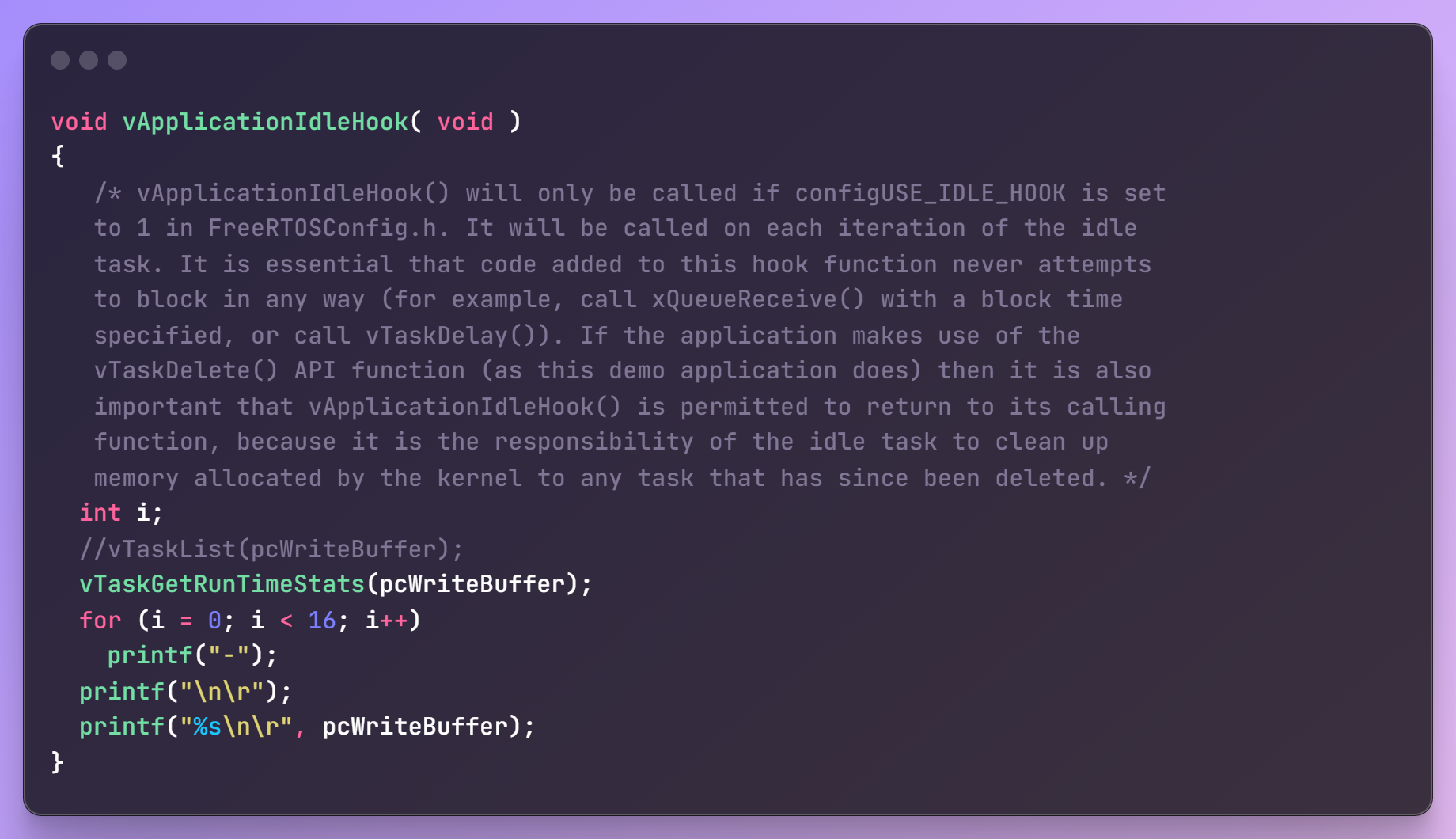
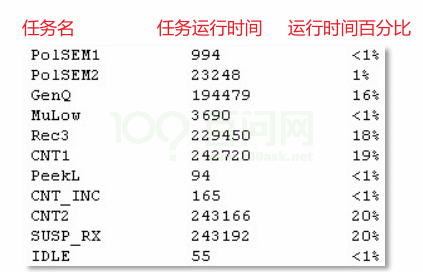
- vTaskGetRunTimeStats:获得任务的运行信息,形式为可读的字符串。注意,pcWriteBuffer必须足够大。
void vTaskGetRunTimeStats( signed char *pcWriteBuffer );可读信息格式如下:
FreeRTOS实践 & 工程架构演进
背景
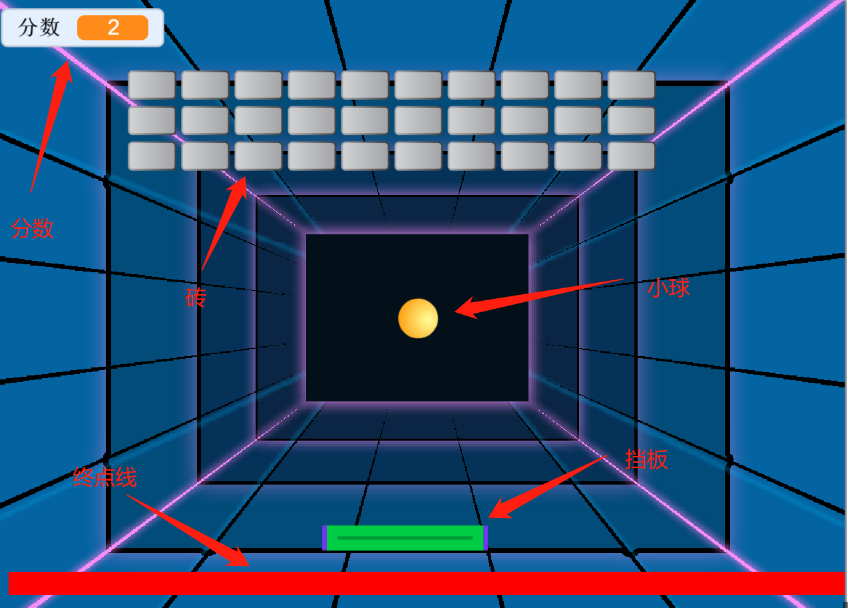
基于STM32F103实现一个以打砖块游戏为背景的多任务系统
- 挡球板左右移动控制
- IR红外遥控:左右键
- 旋转编码器:左右旋转
- MPU6050陀螺仪:左右倾斜
- 蜂鸣器:小球碰到砖块、挡板、中点线、左右边框边界时发出提示音
- DHT11:在顶部显示当前温湿度
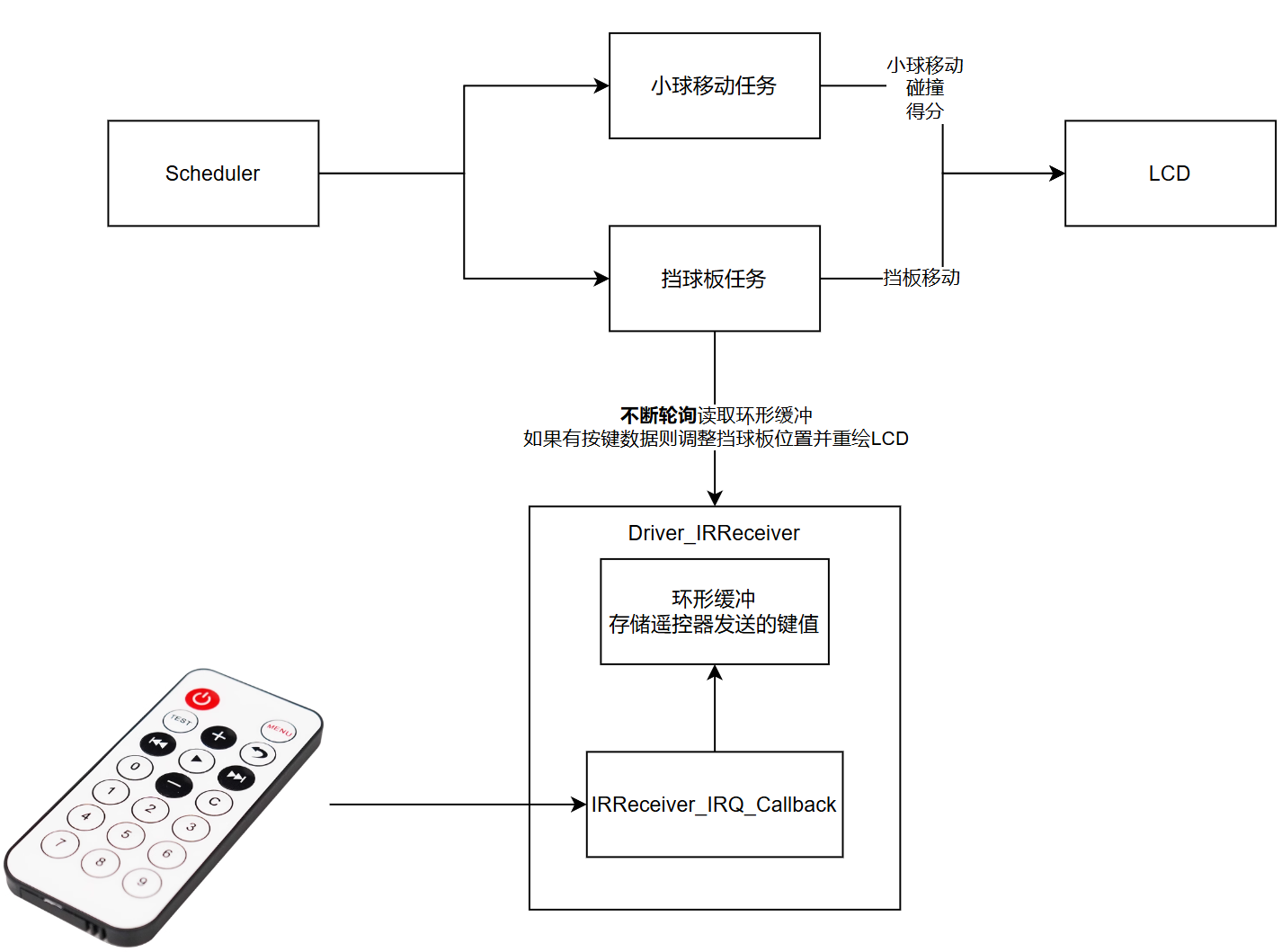
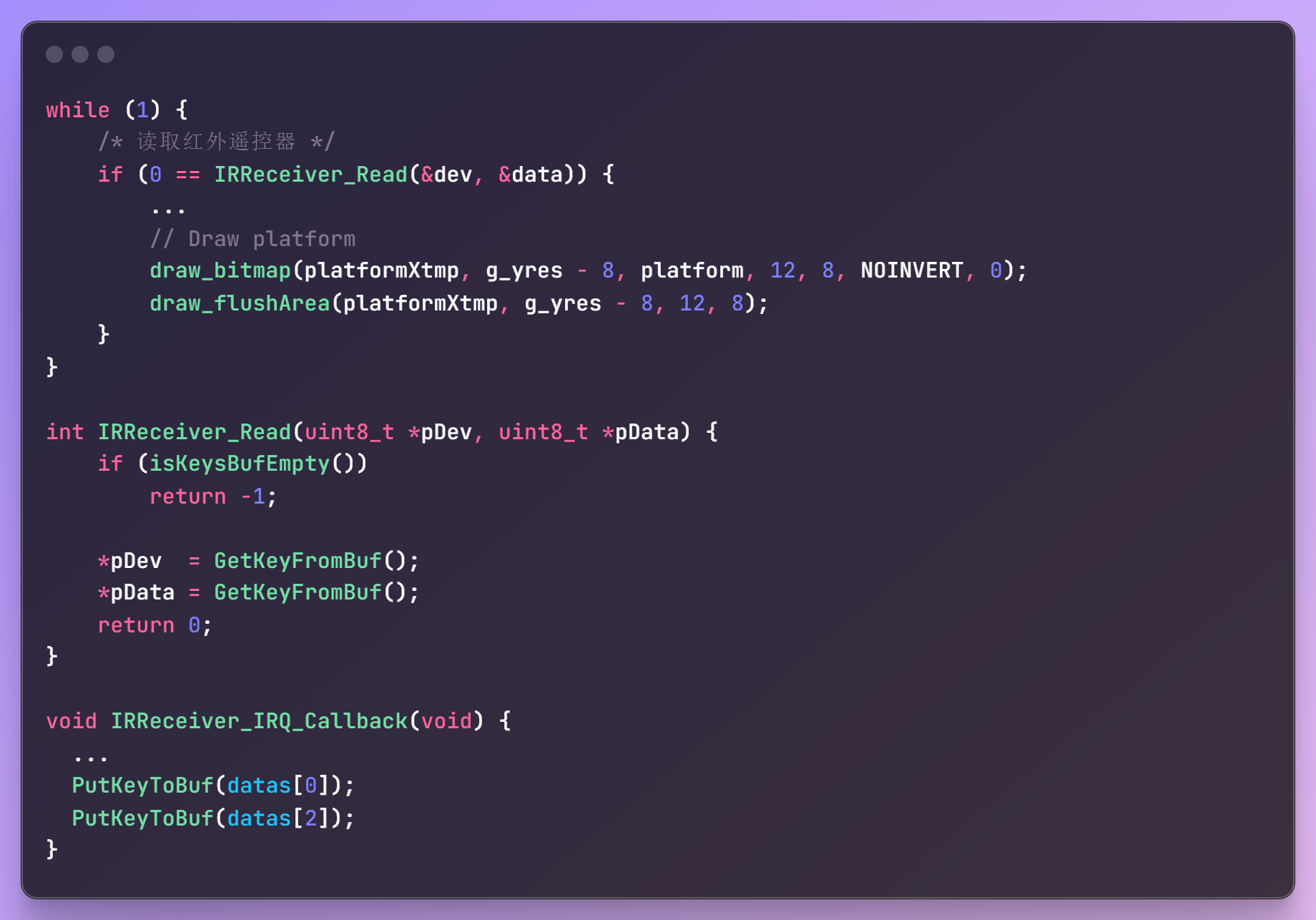
v1.0 非阻塞环形缓冲
缺点
- 挡球板任务不断轮询IR缓冲,不断问它有没有键值数据,即使我们没有使用遥控器控制挡球板;根据FreeRTOS的时间片轮转调度,当缓冲中没有数据时,挡球板任务会把时间片都浪费在
while if的判断中
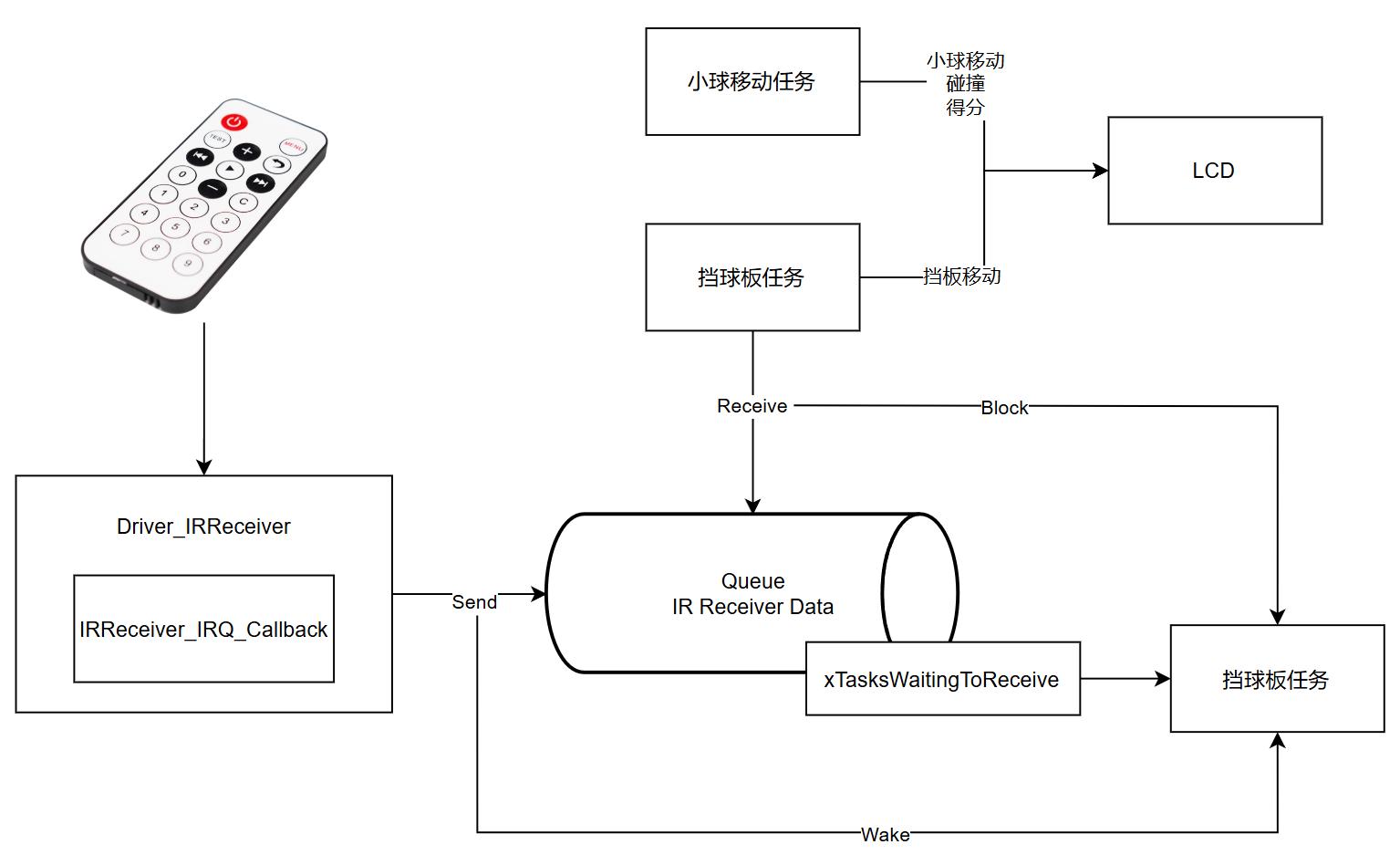
v2.0 队列——使用阻塞(事件驱动)提高CPU利用率
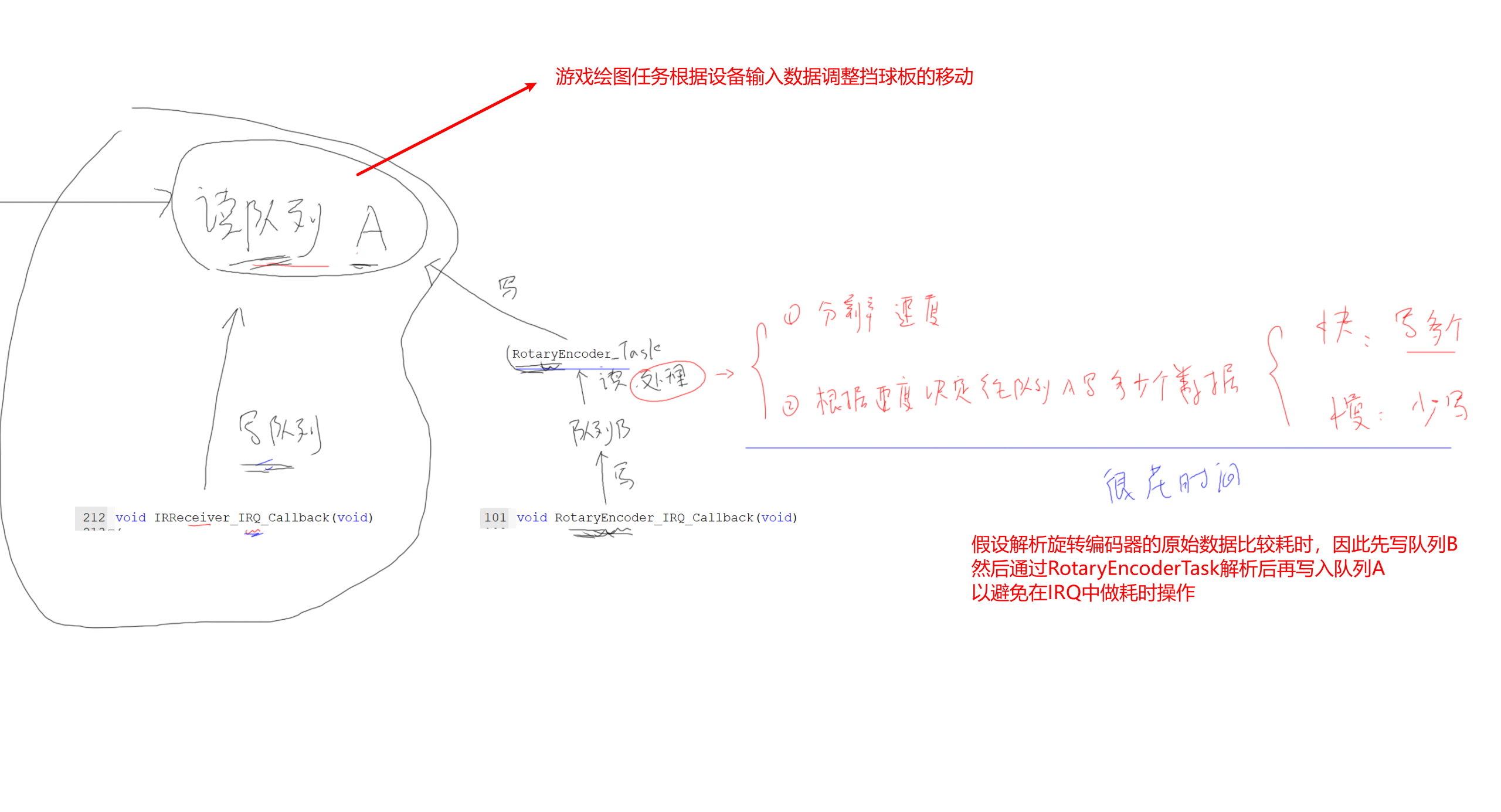
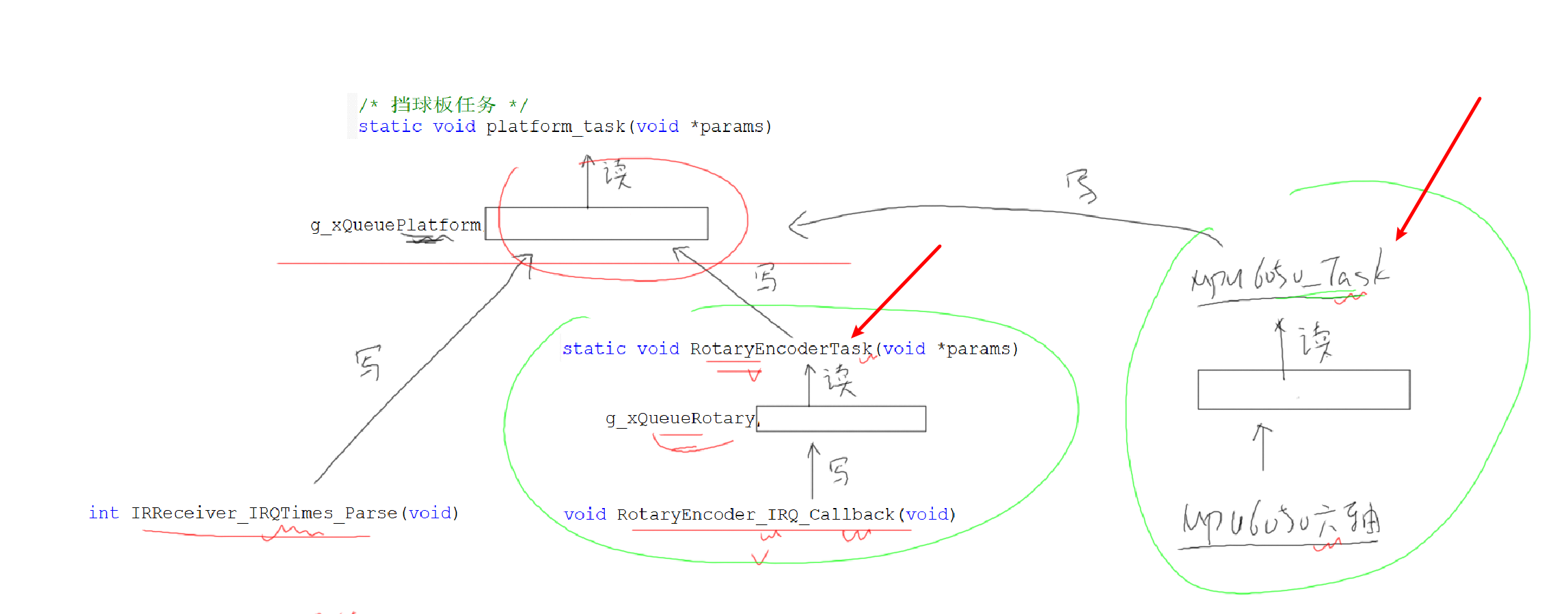
v3.0 多设备输入同时控制游戏
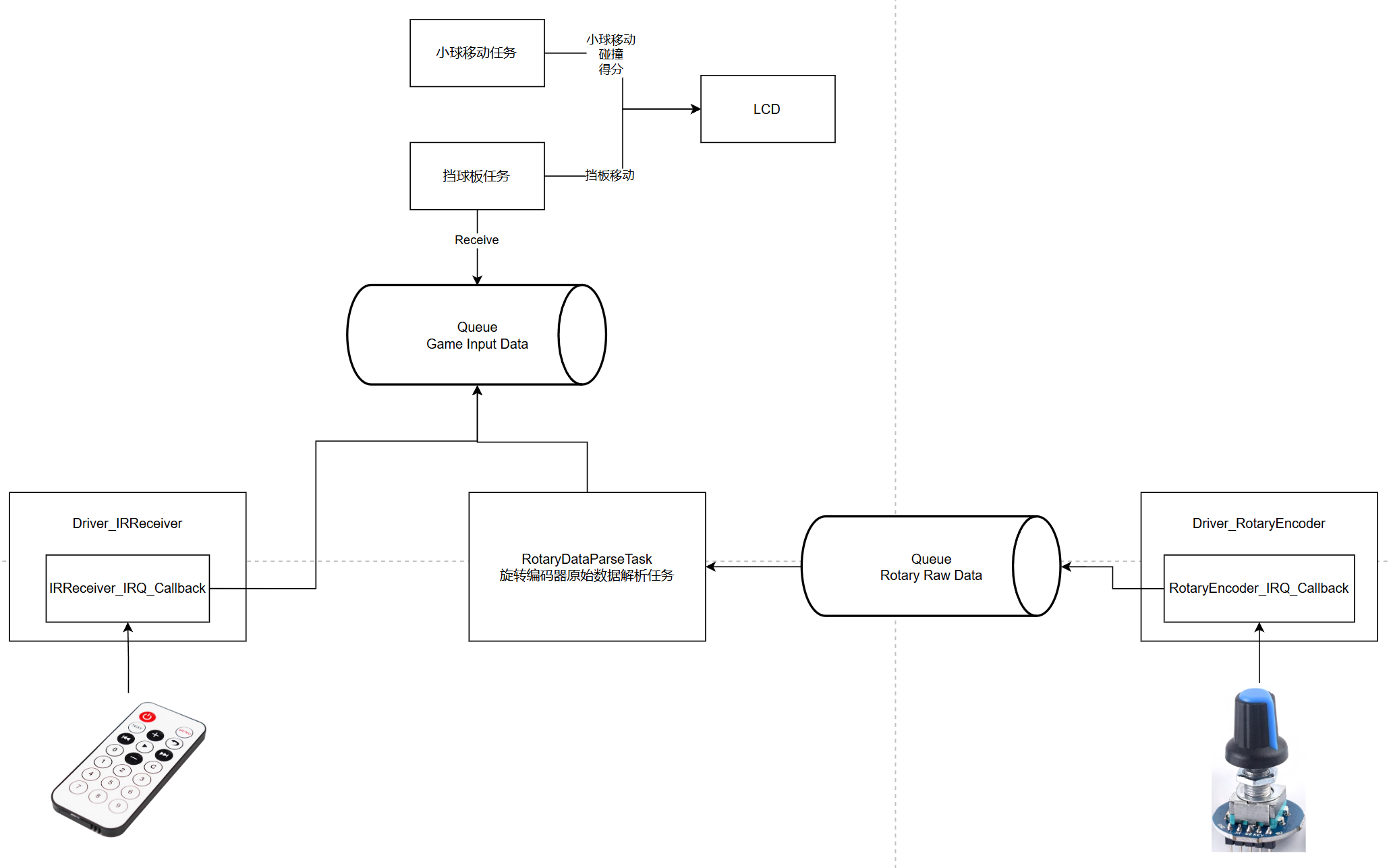
缺点
- 针对每个输入设备,都有将原始数据适配为游戏输入数据(例如向左还是向右移动挡板)的需求,按照上图的架构,那么每扩展一个设备就需要配套增加一个
XxxDataParseTask,而任务是比较重量级的,这样未免显得有些臃肿
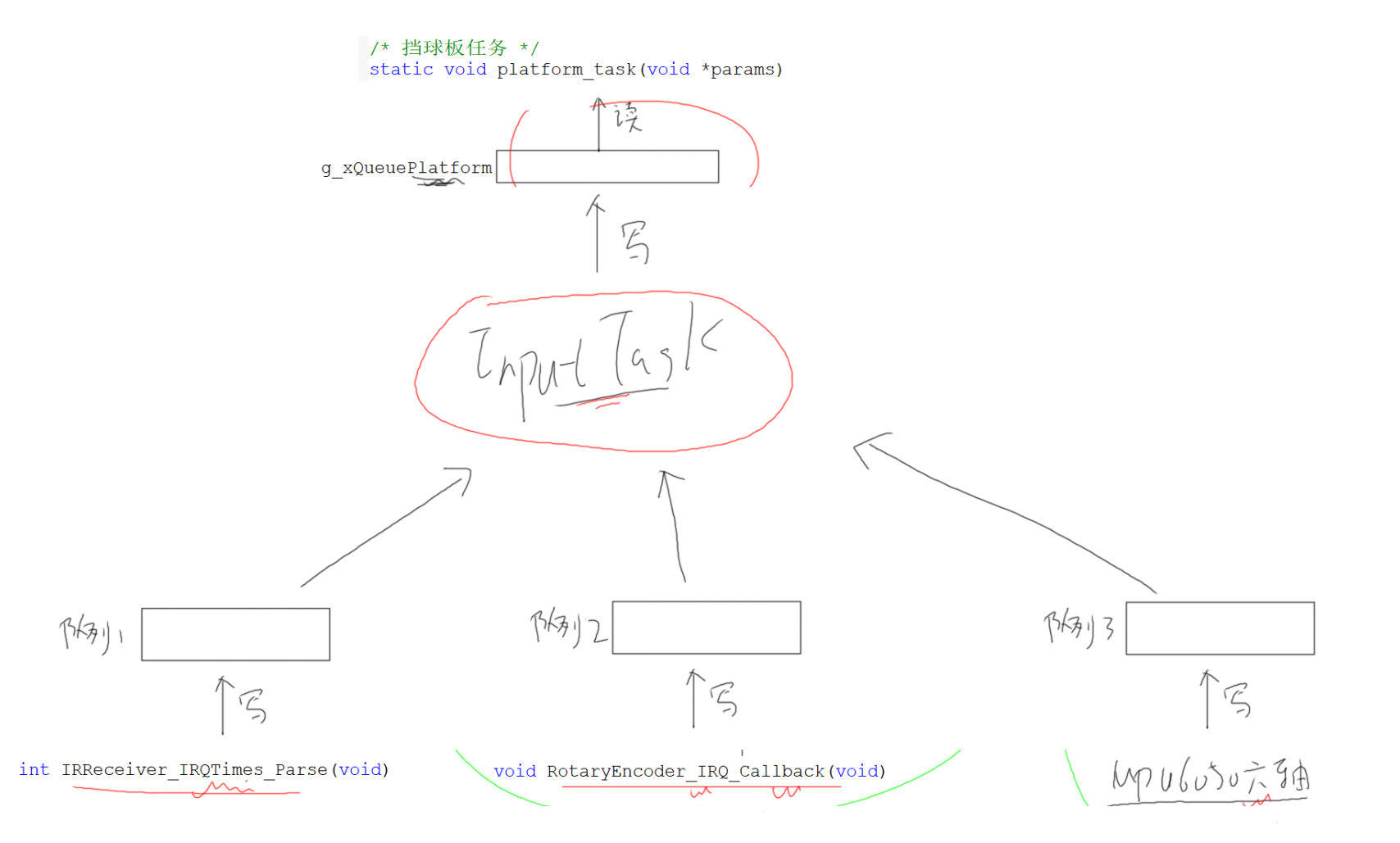
v4.0 队列集——整合相同功能的不同数据来源
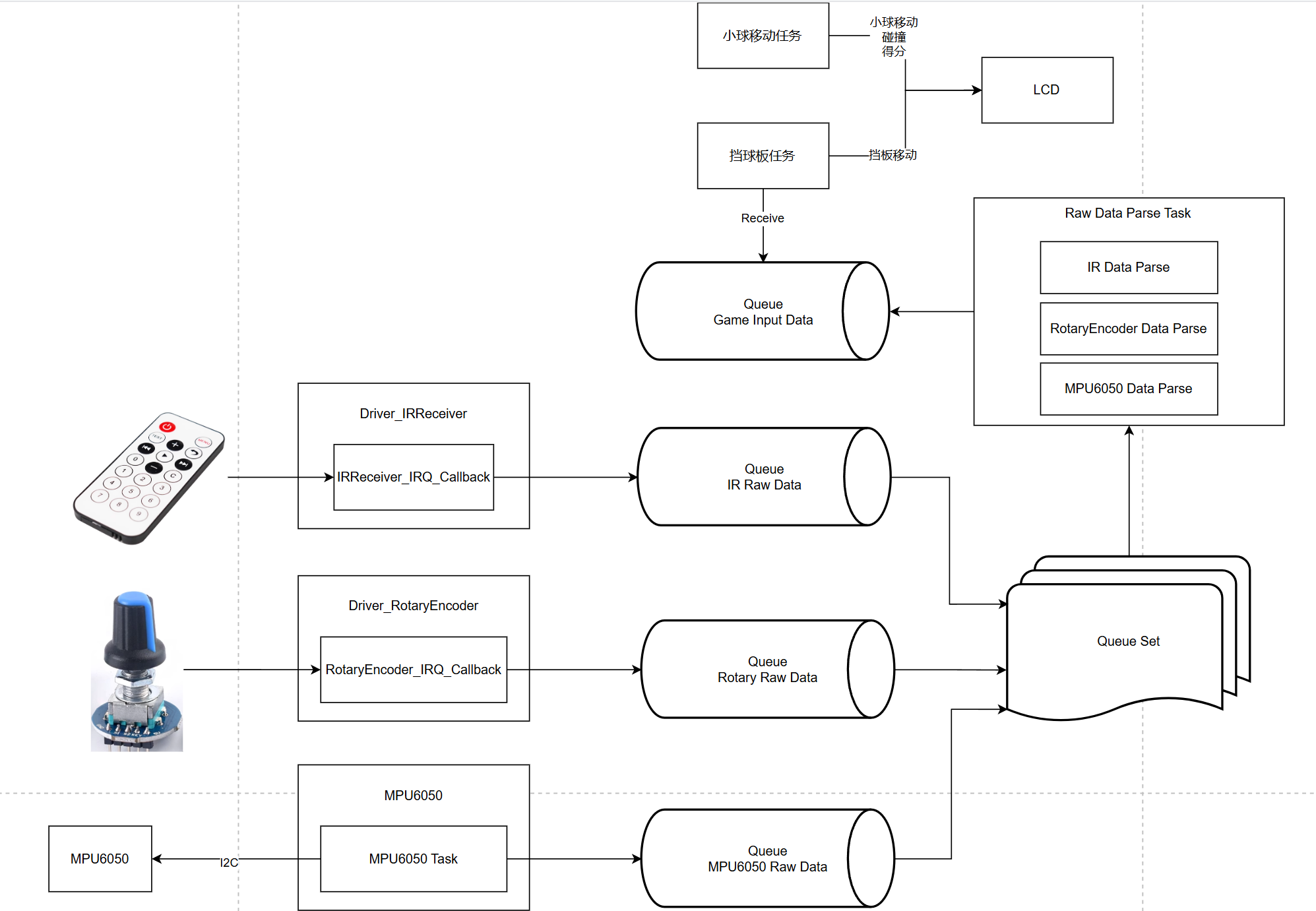
v5.0 解耦——底层驱动分发队列
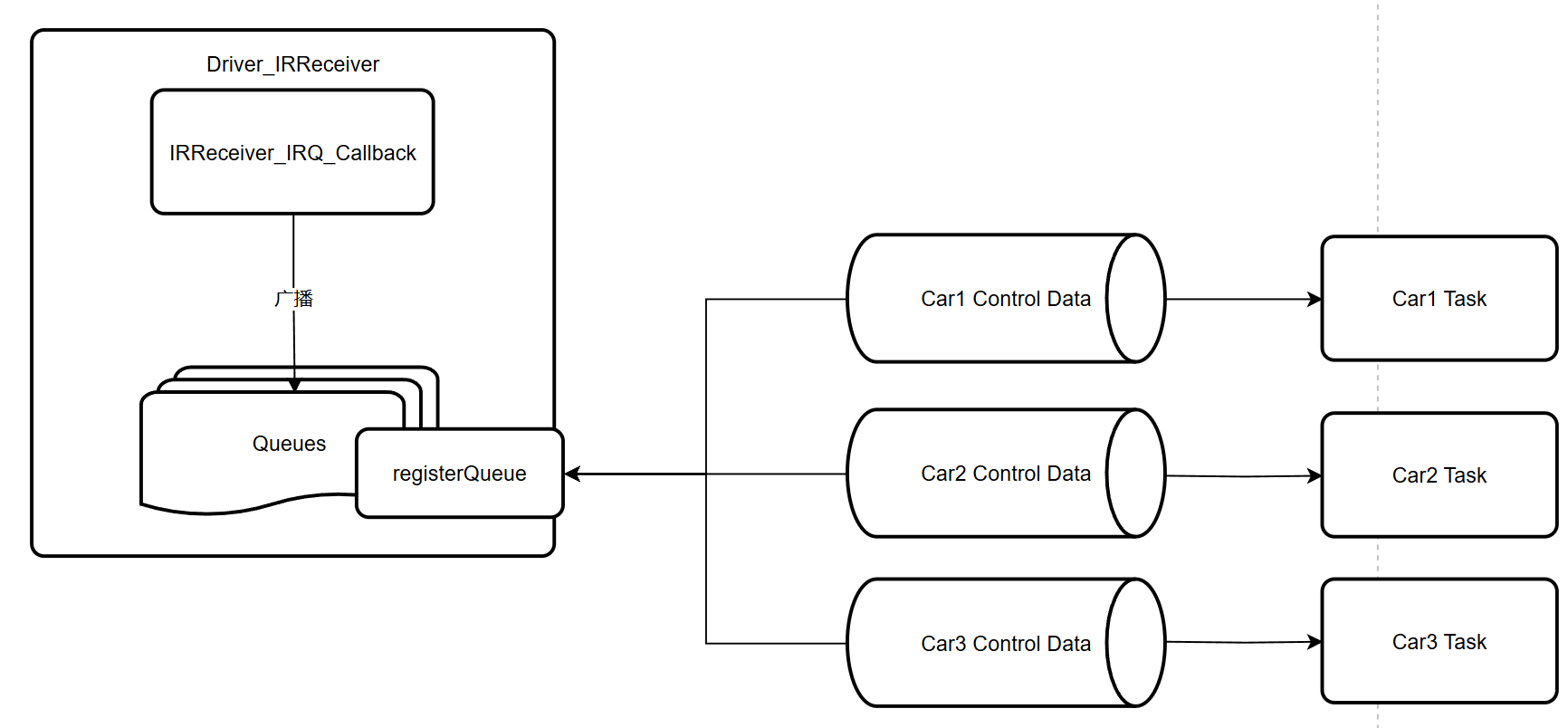
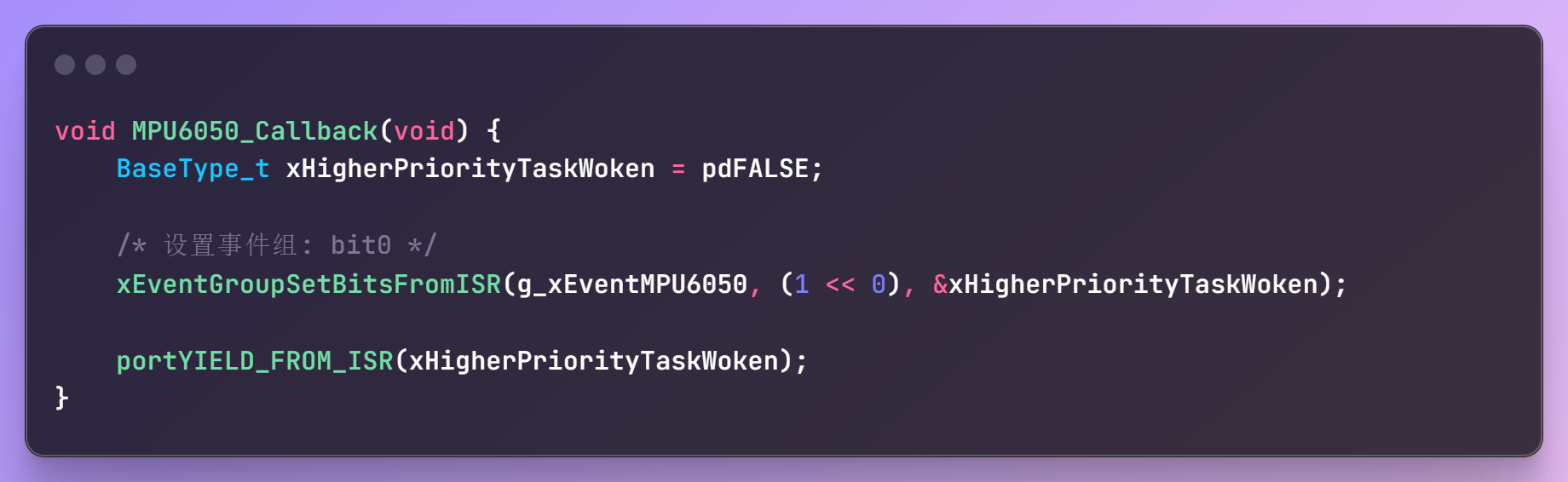
v6.0 事件组——中断触发I2C读取MPU6050
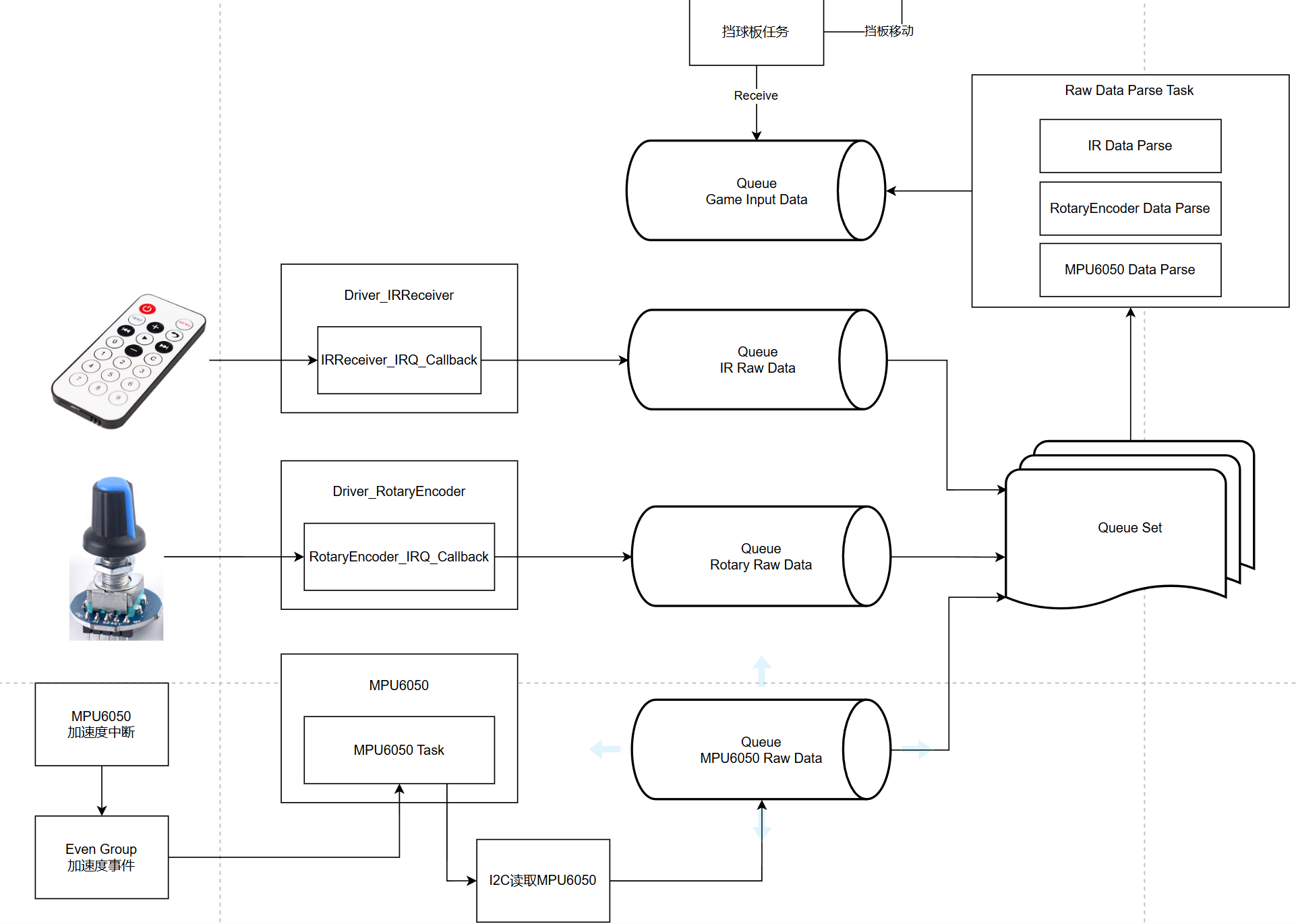
v7.0 软件定时器——提示音定时停止
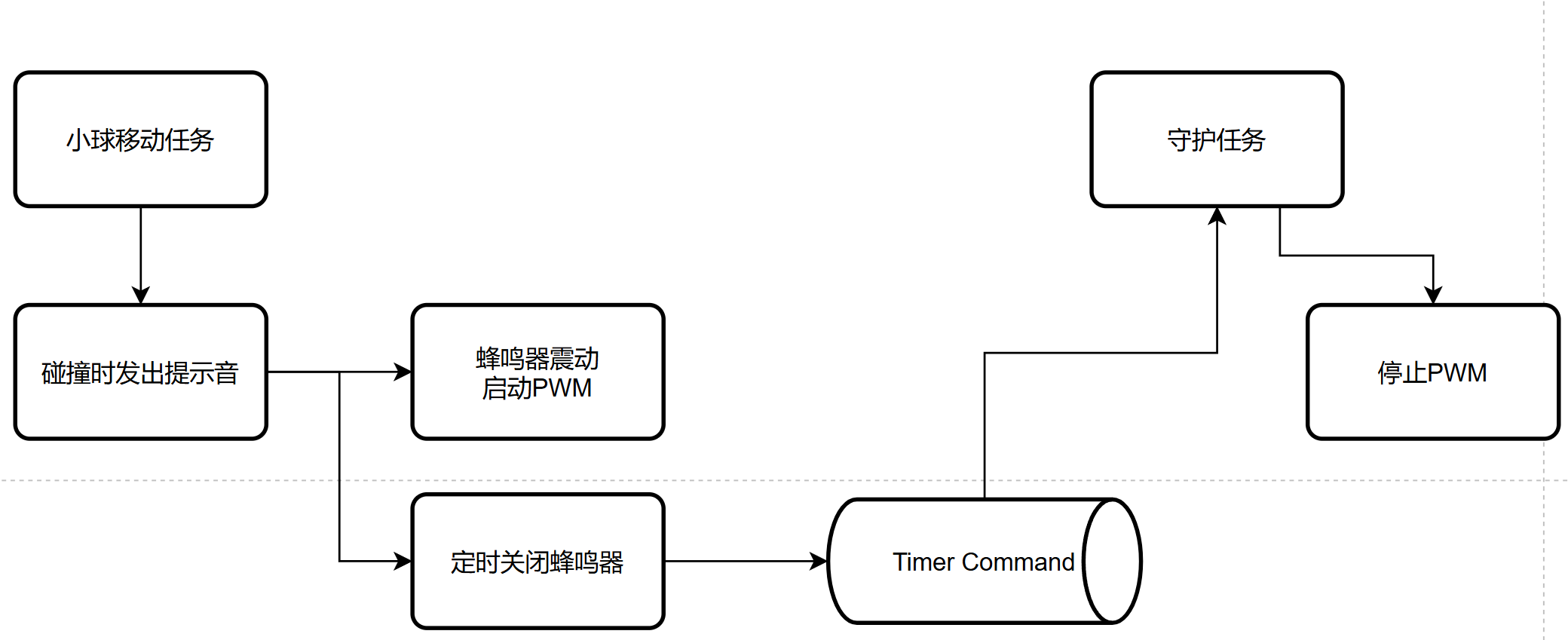
v8.0 FromISR+Yield——改进实时性
v9.0 资源管理——原子操作DHT11时序控制
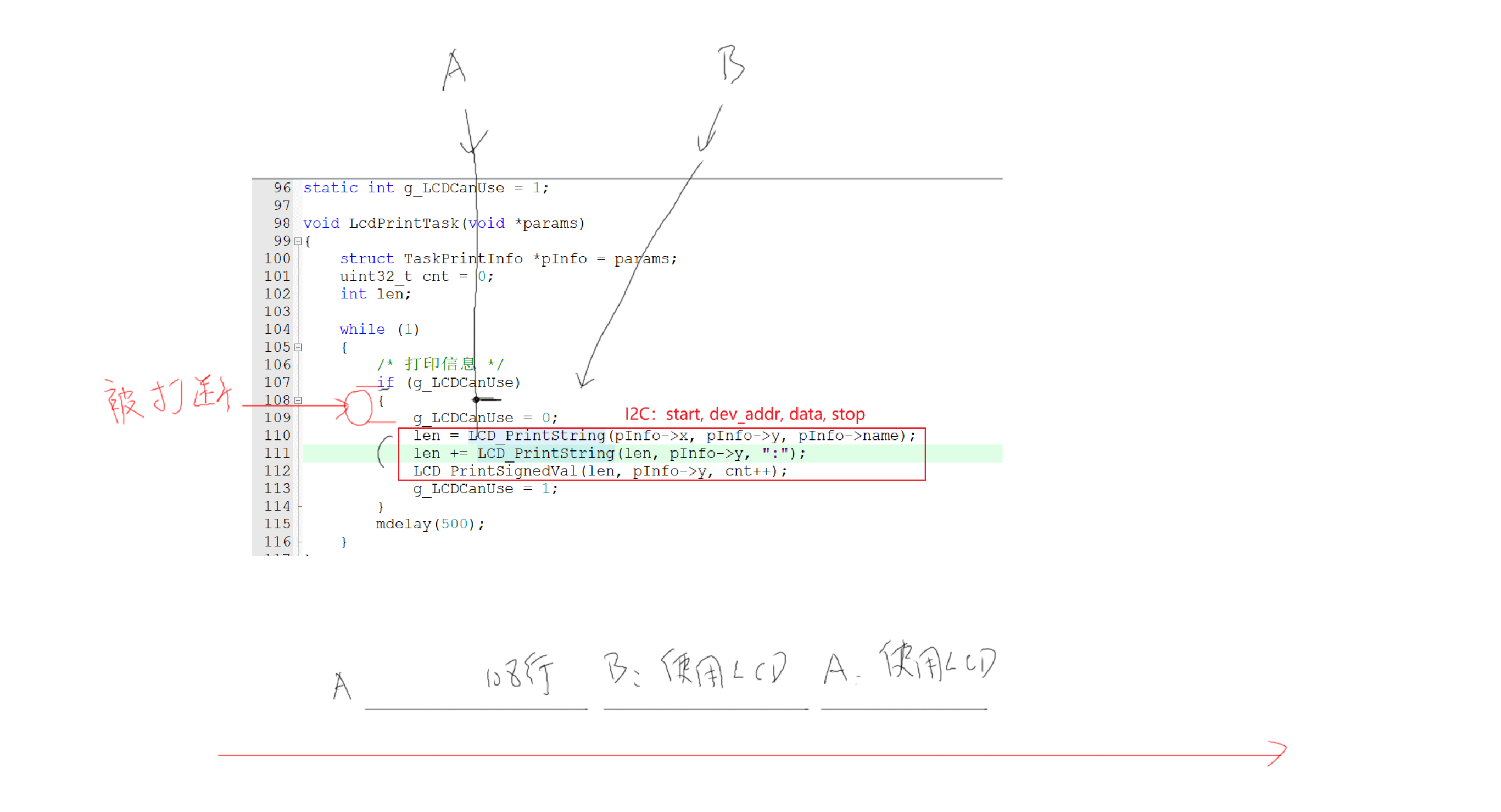
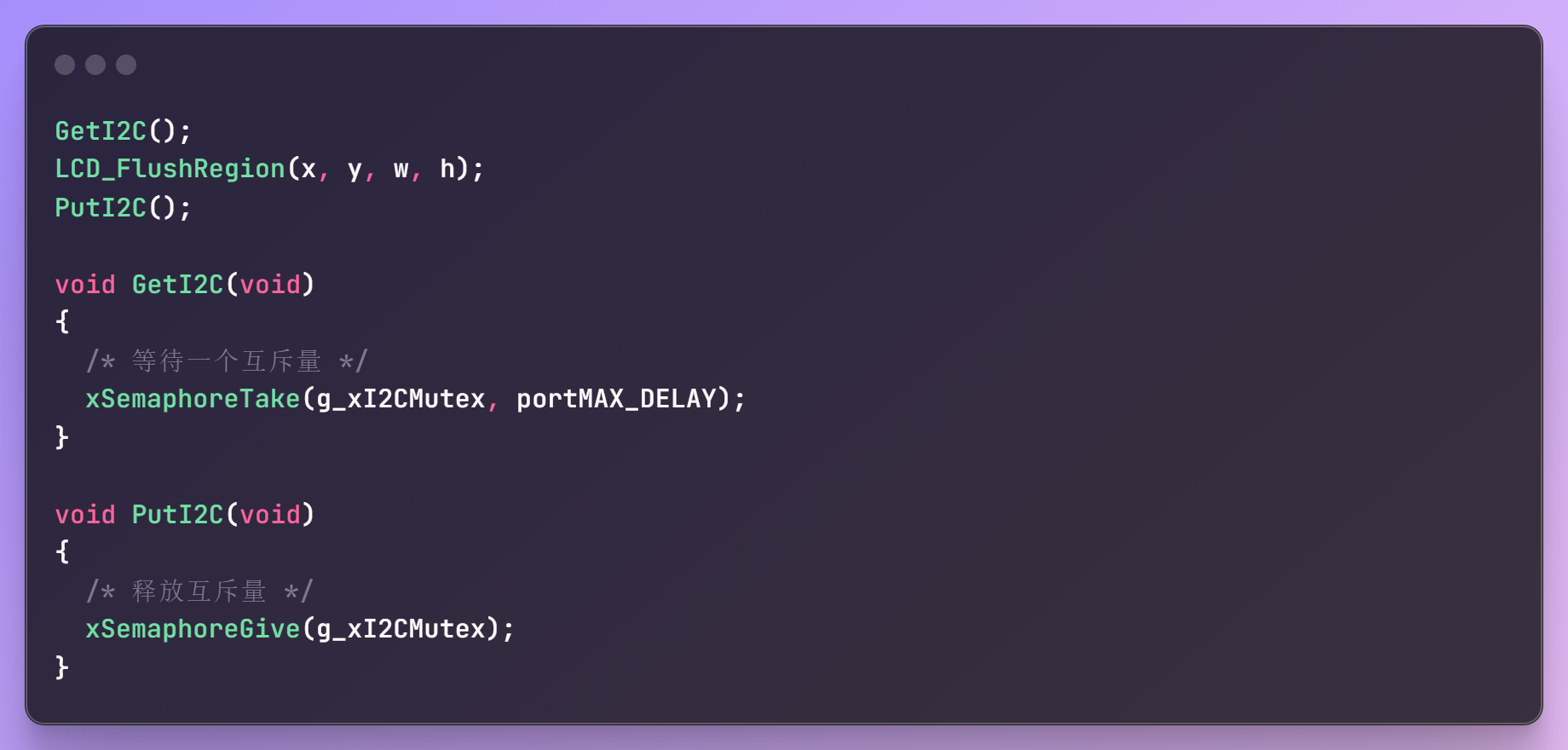
v10.0 互斥量——互斥访问LCD & 避免优先级反转
v11.0 系统优化
任务栈高水位监测 & 优化栈大小

所有任务运行时信息监测
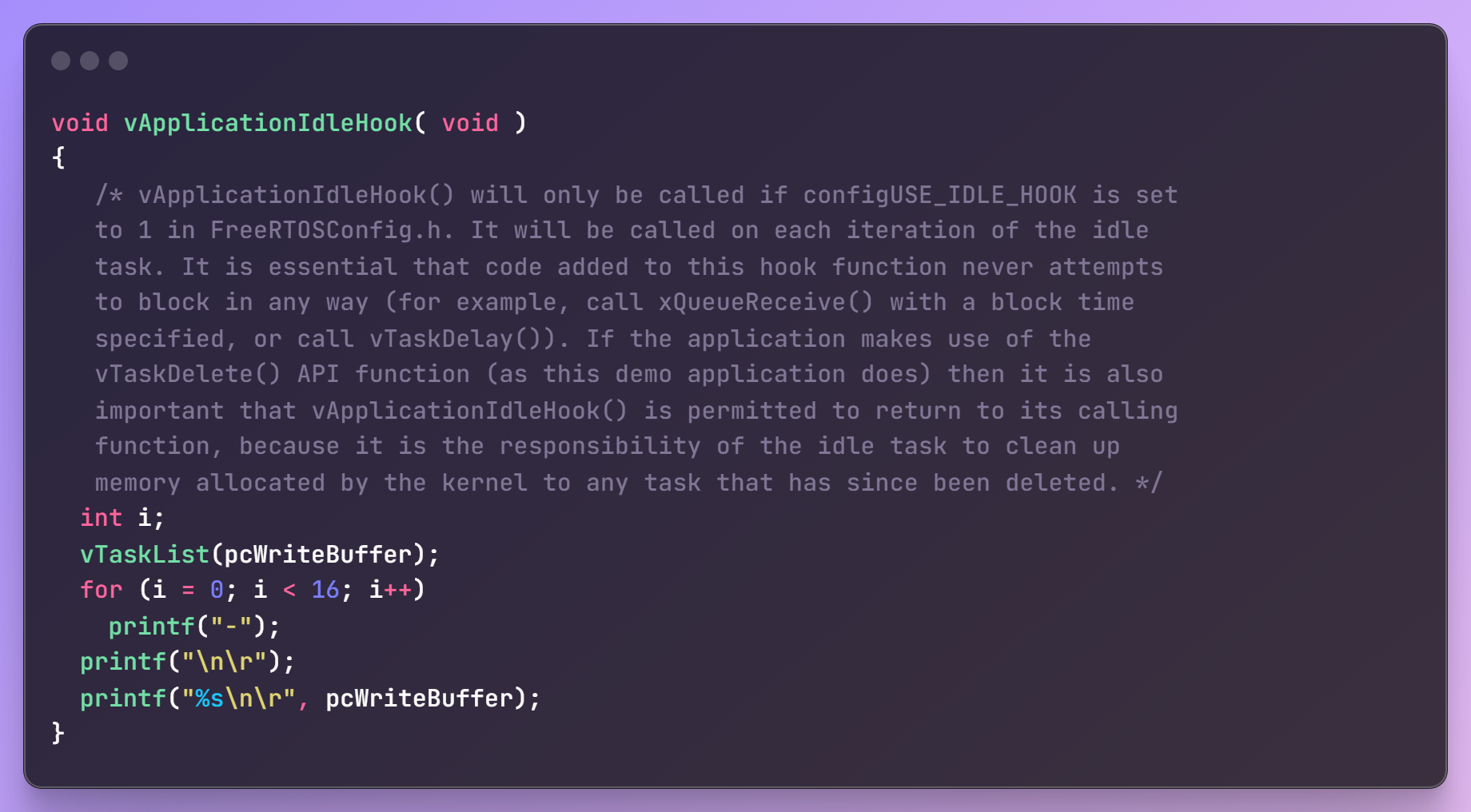
任务占用CPU时间监测